
Abstract
Knowledge distillation is a commonly used method for model compression that has been widely utilized in various computer vision tasks. Many efforts have utilized attention mechanisms to guide the student networks during training, encouraging them to mimic the important features of the teacher. However, most of these efforts use either the channel attention map or the spatial attention map to guide the student, ignoring the importance of positional features. In this paper, we propose a new distillation framework transferring global and positional features (DFGPD), which consists of three parts: global and positional distillation, a generic teacher framework and a two-stage distillation method. DFGPD takes positional information into consideration for a more effective distillation process. We conduct extensive comparison experiments, ablation studies, and sensitivity studies to demonstrate the effectiveness and stability of DFGPD. Our results show that (1) DFGPD achieves comparable or even better performance compared to state-of-the-art methods; (2) DFGPD can alleviate the bigger-models-not-always-better-teachers issue to a certain extent.






Similar content being viewed by others
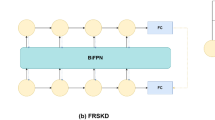
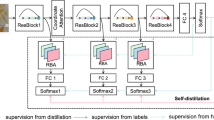
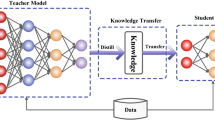
Data availability
The datasets generated and utilized as well as the datasets used for analysis in this study can be requested from the corresponding author upon reasonable request.
References
Yang, W., Feng, J., Xie, G., Liu, J., Guo, Z., Yan, S.: Video super-resolution based on spatial-temporal recurrent residual networks. Comput. Vis. Image Underst. 168, 79–92 (2018)
Tang, S., Guo, D., Hong, R., Wang, M.: Graph-based multimodal sequential embedding for sign language translation. IEEE Trans. Multim. 24, 4433–4445 (2021)
Artacho, B., Savakis, A.: Unipose: unified human pose estimation in single images and videos. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 7035–7044 (2020)
Su, W., Li, L., Liu, F., He, M., Liang, X.: AI on the edge: a comprehensive review. Artif. Intell. Rev. 55(8), 6125–6183 (2022)
Li, L., Su, W., Liu, F., He, M., Liang, X.: Knowledge fusion distillation: improving distillation with multi-scale attention mechanisms. Neural Process. Lett. 1–16 (2023)
Romero, A., Ballas, N., Kahou, S.E., Chassang, A., Gatta, C., Bengio, Y.: Fitnets: hints for thin deep nets. In: Bengio, Y., LeCun, Y. (eds) 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7–9, 2015, Conference Track Proceedings (2015)
Zagoruyko, S., Komodakis, N.: Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer. In: 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24–26, 2017, Conference Track Proceedings, OpenReview.net (2017)
Zhang, L., Ma, K.: Improve object detection with feature-based knowledge distillation: Towards accurate and efficient detectors. In: 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3–7, 2021, OpenReview.net (2021)
Yang, Z., Li, Z., Jiang, X., Gong, Y., Yuan, Z., Zhao, D., Yuan, C.: Focal and global knowledge distillation for detectors. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18–24, 2022, IEEE, pp. 4633–4642 (2022)
Zhang, L., Song, J., Gao, A., Chen, J., Bao, C., Ma, K.: Be your own teacher: improve the performance of convolutional neural networks via self distillation. In: 2019 IEEE/CVF International Conference on Computer Vision, ICCV 2019, Seoul, Korea (South), October 27–November 2, 2019, IEEE, pp. 3712–3721 (2019)
Ji, M., Shin, S., Hwang, S., Park, G., Moon, I.: Refine myself by teaching myself: feature refinement via self-knowledge distillation. In: IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, Virtual, June 19–25, 2021, pp. 10664–10673, Computer Vision Foundation/IEEE (2021)
Tan, M., Pang, R., Le, Q.V.: Efficientdet: scalable and efficient object detection. In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, June 13–19, 2020, Computer Vision Foundation/IEEE, pp. 10778–10787 (2020)
Verma, A., Gulati, P., Gupta, S.: [re] distilling knowledge via knowledge review. CoRR vol. abs/2205.11246 (2022)
Dai, C., Liu, X., Li, Z., Chen, M.: A tucker decomposition based knowledge distillation for intelligent edge applications. Appl. Soft Comput. 101, 107051 (2021)
Cho, J.H., Hariharan, B.: On the efficacy of knowledge distillation. In: 2019 IEEE/CVF International Conference on Computer Vision, ICCV 2019, Seoul, Korea (South), October 27–November 2, 2019, IEEE, pp. 4793–4801 (2019)
Mirzadeh, S., Farajtabar, M., Li, A., Ghasemzadeh, H.: Improved knowledge distillation via teacher assistant: bridging the gap between student and teacher. CoRR vol. abs/1902.03393 (2019)
Hinton, G.E., Vinyals, O., Dean, J.: Distilling the knowledge in a neural network. CoRR vol. abs/1503.02531 (2015)
Zhang, Y., Xiang, T., Hospedales, T.M., Lu, H.: Deep mutual learning. In: 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, June 18–22, 2018, Computer Vision Foundation/IEEE Computer Society, pp. 4320–4328 (2018)
Howard, A.G., Zhu, M., Chen, B., Kalenichenko, D., Wang, W., Weyand, T., Andreetto, M., Adam, H.: Mobilenets: efficient convolutional neural networks for mobile vision applications. CoRR vol. abs/1704.04861 (2017)
Zhang, L., Tan, Z., Song, J., Chen, J., Bao, C., Ma, K.: SCAN: a scalable neural networks framework towards compact and efficient models. In: Wallach, H.M., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E.B., Garnett, R. (eds.) Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, December 8–14, 2019, Vancouver, BC, Canada, pp. 4029–4038 (2019)
Deng, J., Dong, W., Socher, R., Li, L.-J., Li, K., Fei-Fei, L.: Imagenet: a large-scale hierarchical image database. In: 2009 IEEE Conference on Computer Vision and Pattern Recognition, Ieee, pp. 248–255 (2009)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, June 27–30, 2016, IEEE Computer Society, pp. 770–778 (2016)
Zagoruyko, S., Komodakis, N.: Wide residual networks. In: Wilson, R.C., Hancock, E.R., Smith, W.A.P. (eds.) Proceedings of the British Machine Vision Conference 2016, BMVC 2016, York, UK, September 19–22, 2016. BMVA Press (2016)
Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition. In: Bengio, Y., LeCun, Y. (eds.) 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7–9, 2015, Conference Track Proceedings (2015)
Howard, A., Pang, R., Adam, H., Le, Q.V., Sandler, M., Chen, B., Wang, W., Chen, L., Tan, M., Chu, G., Vasudevan, V., Zhu, Y.: Searching for mobilenetv3. In: 2019 IEEE/CVF International Conference on Computer Vision, ICCV 2019, Seoul, Korea (South), October 27–November 2, 2019, IEEE, pp. 1314–1324 (2019)
Zhang, X., Zhou, X., Lin, M., Sun, J.: Shufflenet: an extremely efficient convolutional neural network for mobile devices. In: 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, June 18–22, 2018, Computer Vision Foundation/IEEE Computer Society, pp. 6848–6856 (2018)
Ma, N., Zhang, X., Zheng, H., Sun, J.: Shufflenet V2: practical guidelines for efficient CNN architecture design. In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y. (eds.) Computer Vision—ECCV 2018—15th European Conference, Munich, Germany, September 8–14, 2018, Proceedings, Part XIV, vol. 11218 of Lecture Notes in Computer Science, pp. 122–138. Springer (2018)
Zhao, B., Cui, Q., Song, R., Qiu, Y., Liang, J.: Decoupled knowledge distillation. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18–24, 2022, IEEE, pp. 11943–11952 (2022)
Yang, Z., Li, Z., Shao, M., Shi, D., Yuan, Z., Yuan, C.: Masked generative distillation. In: Avidan, S., Brostow, G.J., Cissé, M., Farinella, G.M., Hassner, T. (eds.) Computer Vision—ECCV 2022—17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XI, vol. 13671 of Lecture Notes in Computer Science, pp. 53–69. Springer (2022)
Yang, Z., Zeng, A., Li, Z., Zhang, T., Yuan, C., Li, Y.: From knowledge distillation to self-knowledge distillation: A unified approach with normalized loss and customized soft labels. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 17185–17194 (2023)
Sun, S., Ren, W., Li, J., Wang, R., Cao, X.: Logit standardization in knowledge distillation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 15731–15740 (2024)
Miles, R., Mikolajczyk, K.: Understanding the role of the projector in knowledge distillation. Proc. AAAI Conf. Artif. Intell. 38, 4233–4241 (2024)
Cordts, M., Omran, M., Ramos, S., Rehfeld, T., Enzweiler, M., Benenson, R., Franke, U., Roth, S., Schiele, B.: The cityscapes dataset for semantic urban scene understanding. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 3213–3223 (2016)
Everingham, M., Van Gool, L., Williams, C.K., Winn, J., Zisserman, A.: The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 88, 303–338 (2010)
Chen, L.-C., Zhu, Y., Papandreou, G., Schroff, F., Adam, H.: Encoder–decoder with atrous separable convolution for semantic image segmentation. In: Proceedings of the European Conference on Computer Vision (ECCV), pp. 801–818 (2018)
Zhao, H., Shi, J., Qi, X., Wang, X., Jia, J.: Pyramid scene parsing network. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2881–2890 (2017)
Liu, Y., Chen, K., Liu, C., Qin, Z., Luo, Z., Wang, J.: Structured knowledge distillation for semantic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 2604–2613 (2019)
Wang, Y., Zhou, W., Jiang, T., Bai, X., Xu, Y.: Intra-class feature variation distillation for semantic segmentation. In: Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part VII 16, pp. 346–362. Springer (2020)
Yang, C., Zhou, H., An, Z., Jiang, X., Xu, Y., Zhang, Q.: Cross-image relational knowledge distillation for semantic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 12319–12328 (2022)
Shu, C.,. Liu, Y, Gao, J., Yan, Z., Shen, C.: Channel-wise knowledge distillation for dense prediction. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 5311–5320 (2021)
LeCun, Y., Boser, B.E., Denker, J.S., Henderson, D., Howard, R.E., Hubbard, W.E., Jackel, L.D.: Backpropagation applied to handwritten zip code recognition. Neural Comput. 1(4), 541–551 (1989)
Acknowledgements
This work was supported in part by National Key R &D Program of China (2023YFB4706800); National Key R &D Program of China (2021YFB2501800).
Author information
Authors and Affiliations
Contributions
Weixing Su: conceptualization, methodology, software. Haoyu Wang: data curation, visualization, writing—original draft. Fang Liu: funding acquisition, formal analysis, writing—original draft. Linfeng Li: investigation, validation, writing—review and editing.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Ethical approval
The content of this manuscript is original and has not been published or submitted for publication elsewhere. We confirm that this submission complies with the policies of your journal, and that neither the manuscript nor the underlying study violates any of the journal’s ethical guidelines.
Additional information
Communicated by Xun Yang.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Su, W., Wang, H., Liu, F. et al. DFGPD: a new distillation framework with global and positional distillation. Multimedia Systems 30, 274 (2024). https://doi.org/10.1007/s00530-024-01503-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s00530-024-01503-9