
Abstract
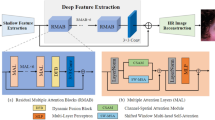
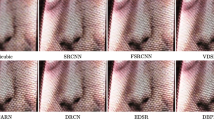
Image super-resolution (SR) is a fundamental problem in image processing. Recently, CNN-based methods have been favored for their ability to effectively utilize local information. Later, Transformer-based methods have gained significant attention for their excellent modeling of long-range pixel correlations. However, many Transformer-based methods do not simultaneously consider spatial and channel correlations, leading to incomplete feature representation. Some initial methods attempt to combine CNNs and Transformers to integrate local and global information but often fail to balance fine-grained details and long-range dependencies, resulting in suboptimal feature aggregation. To address this issue, we design a novel hybrid SR network that achieves comprehensive fusion of global and local information. We propose a Dual-path Collaborative Block (DCB), which includes a Dual Attention Transformer Module (DATM), a Multi-scale Convolution Module (MCM), and a Selective Fusion Module (SFM). Our DATM integrates channel attention with the traditional Transformer structure, enabling features to capture a broader range of information. The MCM enhances feature representation. SFM selectively fuses features based on similarity between those generated by DATM and MCM, effectively preserving the global outline and local details. Extensive experimental results on standard benchmark datasets demonstrate that our model performs better compared to existing SR methods, providing superior image quality and preservation of detail. Our code can be found at https://github.com/CZhangIR/DCNet.git.








Similar content being viewed by others

Data availability
No datasets were generated or analysed during the current study.
References
Greenspan, H.: Super-resolution in medical imaging. Comput. J. 52(1), 43–63 (2009)
Qiu, D., Zheng, L., Zhu, J., Huang, D.: Multiple improved residual networks for medical image super-resolution. Future Gener. Comput. Syst. 116, 200–208 (2021)
Li, X., Yu, L., Chen, H., Fu, C.-W., Xing, L., Heng, P.-A.: Transformation-consistent self-ensembling model for semisupervised medical image segmentation. IEEE Trans. Neural Netw. Learn. Syst. 32(2), 523–534 (2020)
Mudunuri, S.P., Biswas, S.: Low resolution face recognition across variations in pose and illumination. IEEE Trans. Pattern Anal. Mach. Intell. 38(5), 1034–1040 (2015)
Farooq, M., Dailey, M.N., Mahmood, A., Moonrinta, J., Ekpanyapong, M.: Human face super-resolution on poor quality surveillance video footage. Neural Comput. Appl. 33, 13505–13523 (2021)
Zhang, L., Zhang, H., Shen, H., Li, P.: A super-resolution reconstruction algorithm for surveillance images. Signal Process. 90(3), 848–859 (2010)
Ledig, C., Theis, L., Huszár, F., Caballero, J., Cunningham, A., Acosta, A., Aitken, A., Tejani, A., Totz, J., Wang, Z., et al.: Photo-realistic single image super-resolution using a generative adversarial network. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4681–4690 (2017)
Fanfani, M., Colombo, C., Bellavia, F.: Restoration and enhancement of historical stereo photos. J. Imaging 7(7), 103 (2021)
Lugmayr, A., Danelljan, M., Timofte, R., Fritsche, M., Gu, S., Purohit, K., Kandula, P., Suin, M., Rajagoapalan, A., Joon, N.H., et al.: Aim 2019 challenge on real-world image super-resolution: methods and results. In: 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), pp. 3575–3583. IEEE (2019)
Dong, C., Loy, C.C., He, K., Tang, X.: Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 38(2), 295–307 (2015)
Kim, J., Lee, J.K., Lee, K.M.: Accurate image super-resolution using very deep convolutional networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1646–1654 (2016)
Kim, S., Jun, D., Kim, B.-G., Lee, H., Rhee, E.: Single image super-resolution method using cnn-based lightweight neural networks. Appl. Sci. 11(3), 1092 (2021)
Zhu, H., Xie, C., Fei, Y., Tao, H.: Attention mechanisms in cnn-based single image super-resolution: a brief review and a new perspective. Electronics 10(10), 1187 (2021)
Tian, C., Zhuge, R., Wu, Z., Xu, Y., Zuo, W., Chen, C., Lin, C.-W.: Lightweight image super-resolution with enhanced cnn. Knowl. Based Syst. 205, 106235 (2020)
Liang, J., Cao, J., Sun, G., Zhang, K., Van Gool, L., Timofte, R.: Swinir: image restoration using swin transformer. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 1833–1844 (2021)
Zamir, S.W., Arora, A., Khan, S., Hayat, M., Khan, F.S., Yang, M.-H.: Restormer: efficient transformer for high-resolution image restoration. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 5728–5739 (2022)
Yoo, J., Kim, T., Lee, S., Kim, S.H., Lee, H., Kim, T.H.: Enriched cnn-transformer feature aggregation networks for super-resolution. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pp. 4956–4965 (2023)
Li, W., Li, J., Gao, G., Deng, W., Yang, J., Qi, G.-J., Lin, C.-W.: Efficient image super-resolution with feature interaction weighted hybrid network. IEEE Trans. Multimed. 26, 1–12 (2024)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 770–778 (2016)
Lim, B., Son, S., Kim, H., Nah, S., Mu Lee, K.: Enhanced deep residual networks for single image super-resolution. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, pp. 136–144 (2017)
Ioffe, S., Szegedy, C.: Batch normalization: accelerating deep network training by reducing internal covariate shift. In: International Conference on Machine Learning, pp. 448–456. PMLR (2015)
Zhang, Y., Tian, Y., Kong, Y., Zhong, B., Fu, Y.: Residual dense network for image super-resolution. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2472–2481 (2018)
Ahn, N., Kang, B., Sohn, K.-A.: Fast, accurate, and lightweight super-resolution with cascading residual network. In: Proceedings of the European Conference on Computer Vision (ECCV), pp. 252–268 (2018)
Hu, J., Shen, L., Sun, G.: Squeeze-and-excitation networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 7132–7141 (2018)
Zhang, Y., Li, K., Li, K., Wang, L., Zhong, B., Fu, Y.: Image super-resolution using very deep residual channel attention networks. In: Proceedings of the European Conference on Computer Vision (ECCV), pp. 286–301 (2018)
Dai, T., Cai, J., Zhang, Y., Xia, S.-T., Zhang, L.: Second-order attention network for single image super-resolution. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 11065–11074 (2019)
Liu, J., Tang, J., Wu, G.: Residual feature distillation network for lightweight image super-resolution. In: Computer Vision—ECCV 2020 Workshops: Glasgow, UK, August 23–28, 2020, Proceedings, Part III 16, pp. 41–55 (2020). Springer
Zhang, W., Zhao, W., Li, J., Zhuang, P., Sun, H., Xu, Y., Li, C.: Cvanet: cascaded visual attention network for single image super-resolution. Neural Netw. 170, 622–634 (2024)
Shang, S., Shan, Z., Liu, G., Wang, L., Wang, X., Zhang, Z., Zhang, J.: Resdiff: combining cnn and diffusion model for image super-resolution. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 38, pp. 8975–8983 (2024)
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, Ł., Polosukhin, I.: Attention is all you need. In: Advances in Neural Information Processing Systems, vol. 30 (2017)
Zhang, Q., Yang, Y.-B.: Rest: an efficient transformer for visual recognition. Adv. Neural. Inf. Process. Syst. 34, 15475–15485 (2021)
Chen, J., Lu, Y., Yu, Q., Luo, X., Adeli, E., Wang, Y., Lu, L., Yuille, A.L., Zhou, Y.: Transunet: transformers make strong encoders for medical image segmentation. arXiv preprint arXiv:2102.04306 (2021)
Zhang, C., Wang, L., Cheng, S., Li, Y.: Swinsunet: pure transformer network for remote sensing image change detection. IEEE Trans. Geosci. Remote Sens. 60, 1–13 (2022)
Fan, C.-M., Liu, T.-J., Liu, K.-H.: Sunet: swin transformer unet for image denoising. In: 2022 IEEE International Symposium on Circuits and Systems (ISCAS), pp. 2333–2337. IEEE (2022)
Zhou, S., Chan, K., Li, C., Loy, C.C.: Towards robust blind face restoration with codebook lookup transformer. Adv. Neural. Inf. Process. Syst. 35, 30599–30611 (2022)
Jiang, K., Wang, Z., Chen, C., Wang, Z., Cui, L., Lin, C.-W.: Magic elf: image deraining meets association learning and transformer. arXiv preprint arXiv:2207.10455 (2022)
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., et al.: An image is worth 16\(\times\) 16 words: transformers for image recognition at scale. arXiv:2010.11929 (2021)
Chen, H., Wang, Y., Guo, T., Xu, C., Deng, Y., Liu, Z., Ma, S., Xu, C., Xu, C., Gao, W.: Pre-trained image processing transformer. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 12299–12310 (2021)
Lin, X., Sun, S., Huang, W., Sheng, B., Li, P., Feng, D.D.: Eapt: efficient attention pyramid transformer for image processing. IEEE Trans. Multimed. 25, 50–61 (2021)
Wang, Z., Cun, X., Bao, J., Zhou, W., Liu, J., Li, H.: Uformer: a general u-shaped transformer for image restoration. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 17683–17693 (2022)
Ronneberger, O., Fischer, P., Brox, T.: U-net: convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-assisted intervention—MICCAI 2015: 18th International Conference, Munich, Germany, October 5–9, 2015, Proceedings, Part III 18, pp. 234–241. Springer (2015)
Zhang, X., Zeng, H., Guo, S., Zhang, L.: Efficient long-range attention network for image super-resolution. In: European Conference on Computer Vision, pp. 649–667 (2022). Springer
Huang, S., Liu, X., Tan, T., Hu, M., Wei, X., Chen, T., Sheng, B.: Transmrsr: transformer-based self-distilled generative prior for brain mri super-resolution. Vis. Comput. 39(8), 3647–3659 (2023)
Chen, Z., Zhang, Y., Gu, J., Kong, L., Yuan, X., et al.: Cross aggregation transformer for image restoration. Adv. Neural. Inf. Process. Syst. 35, 25478–25490 (2022)
Zhang, X., Zhang, Y., Yu, F.: Hit-sr: hierarchical transformer for efficient image super-resolution. In: European Conference on Computer Vision, pp. 483–500. Springer (2025)
Cheng, K., Yu, L., Tu, Z., He, X., Chen, L., Guo, Y., Zhu, M., Wang, N., Gao, X., Hu, J.: Effective diffusion transformer architecture for image super-resolution. arXiv preprint arXiv:2409.19589 (2024)
Dai, Z., Liu, H., Le, Q.V., Tan, M.: Coatnet: marrying convolution and attention for all data sizes. Adv. Neural. Inf. Process. Syst. 34, 3965–3977 (2021)
Lu, Z., Li, J., Liu, H., Huang, C., Zhang, L., Zeng, T.: Transformer for single image super-resolution. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 457–466 (2022)
Wang, Y., Lu, T., Zhang, Y., Jiang, J., Wang, J., Wang, Z., Ma, J.: Tanet: a new paradigm for global face super-resolution via transformer-cnn aggregation network. arXiv preprint arXiv:2109.08174 (2021)
Wu, Q., Zeng, H., Zhang, J., Li, W., Xia, H.: A hybrid network of cnn and transformer for subpixel shifting-based multi-image super-resolution. Opt. Lasers Eng. 182, 108458 (2024)
Gendy, G., Sabor, N.: Transformer-style convolution network for lightweight image super-resolution. Multimed. Tools Appl. 31, 1–24 (2025)
Li, J., Ke, Y.: Hybrid convolution-transformer for lightweight single image super-resolution. In: ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 2395–2399. IEEE (2024)
Wang, W., Yao, L., Chen, L., Lin, B., Cai, D., He, X., Liu, W.: Crossformer: a versatile vision transformer hinging on cross-scale attention. arXiv 2021. arXiv preprint arXiv:2108.00154 (2018)
Wang, X., Yu, K., Dong, C., Loy, C.C.: Recovering realistic texture in image super-resolution by deep spatial feature transform. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 606–615 (2018)
Timofte, R., Agustsson, E., Van Gool, L., Yang, M.-H., Zhang, L.: Ntire 2017 challenge on single image super-resolution: methods and results. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, pp. 114–125 (2017)
Bevilacqua, M., Roumy, A., Guillemot, C., Alberi-Morel, M.L.: Low-complexity single-image super-resolution based on nonnegative neighbor embedding. In: Proceedings of the International Conference on British Machine Vision, pp. 1–10 (2012)
Zeyde, R., Elad, M., Protter, M.: On single image scale-up using sparse-representations. In: Curves and Surfaces: 7th International Conference, Avignon, France, June 24–30, 2010, Revised Selected Papers 7, pp. 711–730. Springer (2012)
Martin, D., Fowlkes, C., Tal, D., Malik, J.: A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In: Proceedings Eighth IEEE International Conference on Computer Vision. ICCV 2001, vol. 2, pp. 416–423. IEEE (2001)
Huang, J.-B., Singh, A., Ahuja, N.: Single image super-resolution from transformed self-exemplars. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 5197–5206 (2015)
Matsui, Y., Ito, K., Aramaki, Y., Fujimoto, A., Ogawa, T., Yamasaki, T., Aizawa, K.: Sketch-based manga retrieval using manga109 dataset. Multimed. Tools Appl. 76, 21811–21838 (2017)
Niu, B., Wen, W., Ren, W., Zhang, X., Yang, L., Wang, S., Zhang, K., Cao, X., Shen, H.: Single image super-resolution via a holistic attention network. In: Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XII 16, pp. 191–207. Springer (2020)
Mei, Y., Fan, Y., Zhou, Y., Huang, L., Huang, T.S., Shi, H.: Image super-resolution with cross-scale non-local attention and exhaustive self-exemplars mining. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 5690–5699 (2020)
Li, A., Zhang, L., Liu, Y., Zhu, C.: Feature modulation transformer: cross-refinement of global representation via high-frequency prior for image super-resolution. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 12514–12524 (2023)
Liu, X., Liao, X., Shi, X., Qing, L., Ren, C.: Efficient information modulation network for image super-resolution. In: ECAI 2023, pp. 1544–1551 (2023)
Da, K.: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014)
Acknowledgements
This work was supported by the Natural Science Foundation of China under Grant 62272016, the Natural Science Foundation of China under Grant 62372018 and the Natural Science Foundation of China under Grant U21B2038.
Author information
Authors and Affiliations
Contributions
Chun Zhang: methodology, Writing—original draft, experiment implementation. Jin Wang: conceptualization, writing—review and editing, supervision. Yunhui Shi: formal analysis, validation. Baocai Yin: project administration. Nam Ling: writing—reviewing and editing.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no competing interests.
Additional information
Communicated by Bing-kun Bao.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Zhang, C., Wang, J., Shi, Y. et al. A CNN-transformer hybrid network with selective fusion and dual attention for image super-resolution. Multimedia Systems 31, 126 (2025). https://doi.org/10.1007/s00530-025-01711-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s00530-025-01711-x