
Abstract
Energy efficiency has recently replaced performance as the main design goal for microprocessors across all market segments. Vectorization, parallelization, specialization and heterogeneity are the key approaches that both academia and industry embrace to make energy efficiency a reality. New architectural proposals are validated against real applications in order to ensure correctness and perform performance and energy evaluations. However, keeping up with architectural changes while maintaining similar workloads and algorithms (for comparative purposes) becomes a real challenge. If benchmarks are optimized for certain features and not for others, architects may end up overestimating the impact of certain techniques and underestimating others. The main contribution of this work is a detailed description and evaluation of ParVec, a vectorized version of the PARSEC benchmark suite (as a case study of a commonly used application set). ParVec can target SSE, AVX and NEON™ SIMD architectures by means of custom vectorization and math libraries. The performance and energy efficiency improvements from vectorization depend greatly on the fraction of code that can be vectorized. Vectorization-friendly benchmarks obtain up to 10\(\times \) energy improvements per thread. The ParVec benchmark suite is available for the research community to serve as a new baseline for evaluation of future computer systems.
















Similar content being viewed by others



Notes
This happens in applications with data dependencies, idle cycles and average IPC. If a “power/performance virus” kernel is used, SIMD units will burn additional power depending on register size.
Model Specific Registers.
Region of Interest, that is, code without IO.
Fig. 2 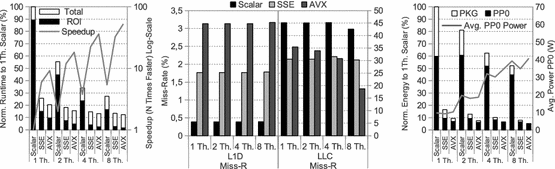
Blackscholes (from left to right) runtime, cache miss rate and energy (Intel)
Fig. 3 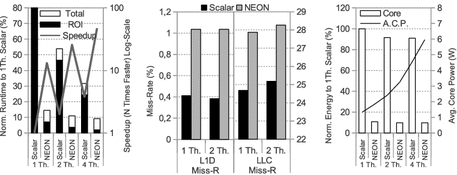
Blackscholes (from left to right) runtime, cache miss rate and energy (ARM)
Sum of the horizontal and vertical components.
A stride load of size \(n\) will require \(n\) registers as input in addition to the memory address to load from. Data is converted from AoS to SoA and stored into the target registers.
In financial terms, an option granting its owner the right but not the obligation to enter into an underlying swap.
A manual loop unrolling mechanism.


References
Bienia, C.: Benchmarking modern multiprocessors. Ph.D. Thesis, Princeton (2011)
Borkar S, Chien AA (2011) The Future of Microprocessors. ACM, NY
Cebrian, J.M., Natvig, L.: Temperature effects on on-chip energy measurements. In: Proceedings of the International Green Computing Conference (IGCC), 2013, pp. 78–87. IEEE Computer Society, Los Alamitos (2012)
Cebrian, J.M., Natvig, L., Jahre, M.: Parvec: vectorized PARSEC benchmarks (2014). http://www.ntnu.edu/ime/eecs/parvec
Cebrian, J.M., Natvig, L., Meyer, J.C.: Improving energy efficiency through parallelization and vectorization on Intel Core i5 and i7 Processors. In: Proceedings of the 2012 SC Companion: High Performance Computing, Networking Storage and Analysis (2012)
Cebrian, J.M., Jahre, M., Natvig, L.: Optimized hardware for suboptimal software: the case for SIMD-aware benchmarks. In: Proceedings of 2014 IEEE International Symposium on Performance Analysis of Systems and Software ISPASS (2014)
Che, S., et al.: Rodinia: a benchmark suite for heterogeneous computing. In: Proceedings of the 2009 IEEE International Symposium on Workload Characterization, IEEE (2009)
Dennard, R., et al.: Design of Ion-Implanted Mosfet’s With Very Small Physical Dimensions (1974)
Donald, J., Martonosi, M.: Techniques for multicore thermal management: classification and new exploration. In: Proc. of the 33rd Int. Symp. on Comp. Arch. (2006)
Esmaeilzadeh, H., et al.: Dark silicon and the end of multicore scaling. In: Proc. of the 38th Annual International Symposium on Computer Architecture, ISCA, ACM (2011)
Feng, W.C., Lin, H., Scogland, T., Zhang, J.: Opencl and the 13 dwarfs: a work in progress. In: Proc. of the 3rd ACM/SPEC Int. Conf. on Performance Engineering, ICPE ’12, ACM (2012)
Ferdman, M., et al.: Clearing the clouds: a study of emerging scale-out workloads on modern hardware. In: 17th Int. Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS) (2012)
Firasta, N., et al.: White paper: Intel AVX: new frontiers in performance improvements and energy efficiency (2008)
Gerber, R.: The Software Optimization Cookbook. Intel Press (2002)
Ghose, S., Srinath, S., Tse, J.: Accelerating a PARSEC benchmark using portable subword SIMD. In: CS 5220: Final Project Report. Cornell Eng. (2011)
Hennessy JL, Patterson DA (2006) Computer Architecture: A Quantitative Approach, 4th edn. Morgan Kaufmann Publishers Inc., San Francisco
Hennessy, J.L., Patterson, D.A.: Computer Architecture: A Quantitative Approach, 5th edn. Morgan Kaufmann Publishers Inc. (2012)
ITRS: Int. Technology Roadmap for Semiconductors report (2012). http://www.itrs.net/Links/2012ITRS/Home2012.htm
Kaxiras, S., Martonosi, M.: Computer Architecture Techniques for Power-Efficiency, 1st edn. Morgan and Claypool Publishers (2008)
Kim, C., et al.: Technical report: closing the ninja performance gap through traditional programming and compiler technology (2012)
Li, J., Martínez, J.F.: Power-Performance Considerations of Parallel Computing on Chip Multiprocessors, pp. 397–422. ACM, New York (2005)
Li, M., Sasanka, R., Adve, S.V., kuang Chen, Y., Debes, E.: The alpbench benchmark suite. In. In Proc. of the IEEE Int. Symp. on Workload Characterization (2005)
Li, S.: Case study: computing black-scholes with Intel advanced vector extensions (2012). http://software.intel.com/en-us/articles/case-study-computing-black-scholes-with-intel-advanced-vector-extensions
Lien, H., Natvig, L., Hasib, A.A., Meyer, J.C.: Case studies of multi-core energy efficiency in task based programs. In: ICT-GLOW, pp. 44–54 (2012)
Lotze, J., Sutton, P.D., Lahlou, H.: Many-core accelerated libor swaption portfolio pricing. In: Proc. of the 2012 SC Companion: High Performance Computing, Networking Storage and Analysis, SCC ’12, IEEE Computer Society (2012)
Molka D et al (2011) Flexible Workload Generation for HPC Cluster Efficiency Benchmarking. Springer, Berlin
Mucci, P.J., Browne, S., Deane, C., Ho, G.: PAPI: a portable interface to hardware performance counters. In: Proc. of the Dep. of Defense Users Group Conf. (1999)
Pommier, J.: Simple SSE and SSE2 sin, cos, log and exp (2007). http://gruntthepeon.free.fr/ssemath/
Totoni, E., Behzad, B., Ghike, S., Torrellas, J.: Comparing the power and performance of Intel’s SCC to state-of-the-art CPUs and GPUs, pp. 78–87. IEEE Computer Society, Los Alamitos (2012)
Acknowledgments
The authors would like to thank the Computer Architecture and Design (CARD) group. The Energy Efficient Computing Systems (EECS) for the funding, Intel for providing the hardware to be used in our experiments and ARM for their constant support to our group.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Cebrian, J.M., Jahre, M. & Natvig, L. ParVec: vectorizing the PARSEC benchmark suite. Computing 97, 1077–1100 (2015). https://doi.org/10.1007/s00607-015-0444-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00607-015-0444-y