
Abstract
We present Stratosphere, an open-source software stack for parallel data analysis. Stratosphere brings together a unique set of features that allow the expressive, easy, and efficient programming of analytical applications at very large scale. Stratosphere’s features include “in situ” data processing, a declarative query language, treatment of user-defined functions as first-class citizens, automatic program parallelization and optimization, support for iterative programs, and a scalable and efficient execution engine. Stratosphere covers a variety of “Big Data” use cases, such as data warehousing, information extraction and integration, data cleansing, graph analysis, and statistical analysis applications. In this paper, we present the overall system architecture design decisions, introduce Stratosphere through example queries, and then dive into the internal workings of the system’s components that relate to extensibility, programming model, optimization, and query execution. We experimentally compare Stratosphere against popular open-source alternatives, and we conclude with a research outlook for the next years.











Similar content being viewed by others



Notes
PACT is a portmanteau for “parallelization contract.”
We follow the definitions from the original MapReduce paper [22] but exclude execution-specific assumptions (such as the presence of sorted reduce inputs).
Fig. 5 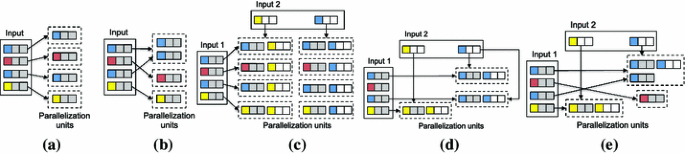
The five second-order functions (PACTs) currently implemented in Stratosphere. The parallelization units implied by the PACTs are enclosed in dotted boxes. a Map b Reduce c Cross d Match e CoGroup
Nephele was a cloud nymph in ancient Greek mythology. The name comes from Greek “\(\nu \epsilon \phi o \varsigma \),” meaning “cloud.” The name tips a hat to Dryad [44] (a tree nymph) that influenced Nephele’s design.
When referring to Java, we refer also to other languages built on top of Java and the JVM, for example, Scala or Groovy.
Some language compilers can transform functions that return a sequence of values automatically into an iterator. Java, however, offers no such mechanism.
At the time of writing, Scope is not offered as a product or service by Microsoft.

References
Ackermann, S., Jovanovic, V., Rompf, T., Odersky, M.: Jet: an embedded dsl for high performance big data processing. In: BigData Workshop at VLDB (2012)
Alexandrov, A., Ewen, S., Heimel, M., Hueske, F., Kao, O., Markl, V., Nijkamp, E., Warneke, D.: Mapreduce and pact - comparing data parallel programming models. In: BTW, pp. 25–44 (2011)
Alexandrov, A., Battré, D., Ewen, S., Heimel, M., Hueske, F., Kao, O., Markl, V., Nijkamp, E., Warneke, D.: Massively parallel data analysis with pacts on nephele. PVLDB 3(2), 1625–1628 (2010)
Apache Giraph. http://incubator.apache.org/giraph/
Apache Hadoop. http://hadoop.apache.org/
Apache Hive. http://sortbenchmark.org/
Aster Data. http://www.asterdata.com/
Battré, D., Ewen, S., Hueske, F., Kao, O., Markl, V., Warneke, D.: Nephele/pacts: a programming model and execution framework for web-scale analytical processing. In: SoCC, pp. 119–130 (2010)
Battré, D., Frejnik, N., Goel, S., Kao, O., Warneke, D.: Evaluation of network topology inference in opaque compute clouds through end-to-end measurements. In: IEEE CLOUD, pp. 17–24 (2011)
Battré, D., Frejnik, N., Goel, S., Kao, O., Warneke, D.: Inferring network topologies in infrastructure as a service cloud. In: CCGRID, pp. 604–605 (2011)
Battré, D., Hovestadt, M., Lohrmann, B., Stanik, A., Warneke, D.: Detecting bottlenecks in parallel dag-based data flow programs. In: MTAGS (2010)
Behm, A., Borkar, V.R., Carey, M.J., Grover, R., Li, C., Onose, N., Vernica, R., Deutsch, A., Papakonstantinou, Y., Tsotras, V.J.: Asterix: towards a scalable, semistructured data platform for evolving-world models. Distrib. Parallel Databases 29(3), 185–216 (2011)
Beyer, K.S., Ercegovac, V., Gemulla, R., Balmin, A., Eltabakh, M.Y., Kanne, C.C., Özcan, F., Shekita, E.J.: Jaql: a scripting language for large scale semistructured data analysis. PVLDB 4(12), 1272–1283 (2011)
Boden, C., Karnstedt, M., Fernandez, M., Markl, V.: Large-scale social media analytics on stratosphere. In: WWW (2013)
Borkar, V.R., Carey, M.J., Grover, R., Onose, N., Vernica, R.: Hyracks: a flexible and extensible foundation for data-intensive computing. In: ICDE, pp. 1151–1162 (2011)
Bruno, N., Agarwal, S., Kandula, S., Shi, B., Wu, M.C., Zhou, J.: Recurring job optimization in scope. In: SIGMOD Conference, pp. 805–806 (2012)
Cha, M., Haddadi, H., Benevenuto, F., Gummadi, P.K.: Measuring user influence in twitter: the million follower fallacy. In: ICWSM (2010)
Chafi, H., DeVito, Z., Moors, A., Rompf, T., Sujeeth, A.K., Hanrahan, P., Odersky, M., Olukotun, K.: Language virtualization for heterogeneous parallel computing. In: OOPSLA, pp. 835–847 (2010)
Chattopadhyay, B., Lin, L., Liu, W., Mittal, S., Aragonda, P., Lychagina, V., Kwon, Y., Wong, M.: Tenzing a sql implementation on the mapreduce framework. PVLDB 4(12), 1318–1327 (2011)
Chaudhuri, S., Shim, K.: Including group-by in query optimization. In: VLDB, pp. 354–366 (1994)
Cohen, J.: Graph twiddling in a mapreduce world. Comput. Sci. Eng. 11(4), 29–41 (2009)
Dean, J., Ghemawat, S.: Mapreduce: simplified data processing on large clusters. In: OSDI, pp. 137–150 (2004)
DeWitt, D.J., Gerber, R.H., Graefe, G., Heytens, M.L., Kumar, K.B., Muralikrishna, M.: Gamma—a high performance dataflow database machine. In: VLDB, pp. 228–237 (1986)
Elnozahy, E.N.M., Alvisi, L., Wang, Y.M., Johnson, D.B.: A survey of rollback-recovery protocols in message-passing systems. ACM Comput. Surv. 34(3), 375–408 (2002)
Ewen, S., Schelter, S., Tzoumas, K., Warneke, D., Markl, V.: Iterative parallel data processing with stratosphere: an inside look. In: SIGMOD (2013)
Ewen, S., Tzoumas, K., Kaufmann, M., Markl, V.: Spinning fast iterative data flows. PVLDB 5(11), 1268–1279 (2012)
Fegaras, L., Li, C., Gupta, U.: An optimization framework for map-reduce queries. In: EDBT, pp. 26–37 (2012)
Fushimi, S., Kitsuregawa, M., Tanaka, H.: An overview of the system software of a parallel relational database machine grace. In: VLDB, pp. 209–219 (1986)
Ghemawat, S., Gobioff, H., Leung, S.T.: The google file system. In: SOSP, pp. 29–43 (2003)
Graefe, G., Bunker, R., Cooper, S.: Hash joins and hash teams in microsoft sql server. In: VLDB, pp. 86–97 (1998)
Graefe, G.: Implementing sorting in database systems. ACM Comput. Surv. 38(3), Article ID 10 (2006)
Graefe, G.: Parallel query execution algorithms. In: Encyclopedia of Database Systems, pp. 2030–2035 (2009)
Graefe, G.: Volcano—an extensible and parallel query evaluation system. IEEE Trans. Knowl. Data Eng. 6(1), 120–135 (1994)
Greenplum. http://www.greenplum.com/
Guo, Z., Fan, X., Chen, R., Zhang, J., Zhou, H., McDirmid, S., Liu, C., Lin, W., Zhou, J., Zhou, L.: Spotting code optimizations in data-parallel pipelines through periscope. In: OSDI, pp. 121–133 (2012)
Harjung, J.J.: Reducing formal noise in pact programs. Master’s thesis, Technische Universität Berlin, Faculty of EECS (2013)
Heise, A., Rheinländer, A., Leich, M., Leser, U., Naumann, F.: Meteor/sopremo: an extensible query language and operator model. In: BigData Workshop at VLDB (2012)
Heise, A., Naumann, F.: Integrating open government data with stratosphere for more transparency. Web Semant.: Sci. Serv. Agents World Wide Web 14, 45–56 (2012)
Höger, M., Kao, O., Richter, P., Warneke, D.: Ephemeral materialization points in stratosphere data management on the cloud. Adv. Parallel Comput. 23, 163–181 (2013)
Hovestadt, M., Kao, O., Kliem, A., Warneke, D.: Evaluating adaptive compression to mitigate the effects of shared i/o in clouds. In: IPDPS Workshops, pp. 1042–1051 (2011)
Hueske, F., Krettek, A., Tzoumas, K.: Enabling operator reordering in data flow programs through static code analysis. CoRR abs/1301.4200 (2013)
Hueske, F., Peters, M., Krettek, A., Ringwald, M., Tzoumas, K., Markl, V., Freytag, J.C.: Peeking into the optimization of data flow programs with mapreduce-style udfs. In: ICDE (2013)
Hueske, F., Peters, M., Sax, M., Rheinländer, A., Bergmann, R., Krettek, A., Tzoumas, K.: Opening the black boxes in data flow optimization. PVLDB 5(11), 1256–1267 (2012)
Isard, M., Budiu, M., Yu, Y., Birrell, A., Fetterly, D.: Dryad: distributed data-parallel programs from sequential building blocks. In: EuroSys, pp. 59–72 (2007)
Jahani, E., Cafarella, M.J., Ré, C.: Automatic optimization for mapreduce programs. PVLDB 4(6), 385–396 (2011)
Java HotSpot VM Whitepaper. http://www.oracle.com/technetwork/java/whitepaper-135217.html
JavaScript Object Notation. http://json.org/
Kalavri, V.: Integrating pig and stratosphere. Master’s thesis, KTH, School of Information and Communication Technology (ICT) (2012)
Kang, U., Tsourakakis, C.E., Faloutsos, C.: Pegasus: a peta-scale graph mining system. In: ICDM, pp. 229–238 (2009)
Kung, H.T., Robinson, J.T.: On optimistic methods for concurrency control. ACM Trans. Database Syst. 6(2), 213–226 (1981)
Leich, M., Adamek, J., Schubotz, M., Heise, A., Rheinländer, A., Markl, V.: Applying stratosphere for big data analytics. In: BTW, pp. 507–510 (2013)
Lim, H., Herodotou, H., Babu, S.: Stubby: a transformation-based optimizer for mapreduce workflows. PVLDB 5(11), 1196–1207 (2012)
Low, Y., Gonzalez, J., Kyrola, A., Bickson, D., Guestrin, C., Hellerstein, J.M.: Distributed graphlab: a framework for machine learning in the cloud. PVLDB 5(8), 716–727 (2012)
Malewicz, G., Austern, M.H., Bik, A.J.C., Dehnert, J.C., Horn, I., Leiser, N., Czajkowski, G.: Pregel: a system for large-scale graph processing. In: SIGMOD Conference, pp. 135–146 (2010)
McSherry, F., Murray, D., Isaacs, R., Isard, M.: Differential dataflow. In: CIDR (2013)
Mihaylov, S.R., Ives, Z.G., Guha, S.: Rex: recursive, delta-based data-centric computation. PVLDB 5(11), 1280–1291 (2012)
Olston, C., Reed, B., Srivastava, U., Kumar, R., Tomkins, A.: Pig latin: a not-so-foreign language for data processing. In: SIGMOD Conference, pp. 1099–1110 (2008)
Pike, R., Dorward, S., Griesemer, R., Quinlan, S.: Interpreting the data: parallel analysis with sawzall. Sci. Program. 13(4), 277–298 (2005)
Project Gutenberg. http://www.gutenberg.org/
Selinger, P.G., Astrahan, M.M., Chamberlin, D.D., Lorie, R.A., Price, T.G.: Access path selection in a relational database management system. In: SIGMOD Conference, pp. 23–34 (1979)
Silva, Y.N., Larson, P.A., Zhou, J.: Exploiting common subexpressions for cloud query processing. In: ICDE, pp. 1337–1348 (2012)
Stanford Network Analysis Project. http://snap.stanford.edu/
Teradata. http://www.teradata.com/
Thusoo, A., Sarma, J.S., Jain, N., Shao, Z., Chakka, P., Anthony, S., Liu, H., Wyckoff, P., Murthy, R.: Hive—a warehousing solution over a map-reduce framework. PVLDB 2(2), 1626–1629 (2009)
Valiant, L.G.: A bridging model for parallel computation. Commun. ACM 33(8), 103–111 (1990)
Wang, Y.M., Fuchs, W.K.: Lazy checkpoint coordination for bounding rollback propagation. In: Reliable Distributed Systems, 1993. Proceedings., 12th Symposium on, pp. 78–85 (1993)
Warneke, D., Kao, O.: Nephele: efficient parallel data processing in the cloud. In: SC-MTAGS (2009)
Warneke, D., Kao, O.: Exploiting dynamic resource allocation for efficient parallel data processing in the cloud. IEEE Trans. Parallel Distrib. Syst. 22(6), 985–997 (2011)
Yu, Y., Isard, M., Fetterly, D., Budiu, M., Erlingsson, Ú., Gunda, P.K., Currey, J.: Dryadlinq: a system for general-purpose distributed data-parallel computing using a high-level language. In: OSDI, pp. 1–14 (2008)
Zaharia, M., Chowdhury, M., Das, T., Dave, A., Ma, J., McCauley, M., Franklin, M.J., Shenker, S., Stoica, I.: Resilient distributed datasets: a fault-tolerant abstraction for in-memory cluster computing. In: NSDI (2012)
Zhang, J., Zhou, H., Chen, R., Fan, X., Guo, Z., Lin, H., Li, J.Y., Lin, W., Zhou, J., Zhou, L.: Optimizing data shuffling in data-parallel computation by understanding user-defined functions. In: NSDI (2012)
Zhou, J., Bruno, N., Lin, W.: Advanced partitioning techniques for massively distributed computation. In: SIGMOD Conference, pp. 13–24 (2012)
Zhou, J., Larson, P.Å., Chaiken, R.: Incorporating partitioning and parallel plans into the scope optimizer. In: ICDE, pp. 1060–1071 (2010)
Zhou, J., Bruno, N., Wu, M.C., Larson, P.Å., Chaiken, R., Shakib, D.: Scope: parallel databases meet mapreduce. VLDB J. 21(5), 611–636 (2012)
Acknowledgments
We would like to thank the Master students that worked on the Stratosphere project and implemented many components of the system: Thomas Bodner, Christoph Brücke, Erik Nijkamp, Max Heimel, Moritz Kaufmann, Aljoscha Krettek, Matthias Ringwald, Tommy Neubert, Fabian Tschirschnitz, Tobias Heintz, Erik Diessler, Thomas Stolltmann.
Author information
Authors and Affiliations
Corresponding author
Additional information
Stratosphere is funded by the German Research Foundation (DFG) under grant FOR 1306.
Rights and permissions
About this article

Cite this article
Alexandrov, A., Bergmann, R., Ewen, S. et al. The Stratosphere platform for big data analytics. The VLDB Journal 23, 939–964 (2014). https://doi.org/10.1007/s00778-014-0357-y
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00778-014-0357-y