
Abstract
Many studies have been conducted on seeking an efficient solution for graph similarity search over certain (deterministic) graphs due to its wide application in many fields, including bioinformatics, social network analysis, and Resource Description Framework data management. All prior work assumes that the underlying data is deterministic. However, in reality, graphs are often noisy and uncertain due to various factors, such as errors in data extraction, inconsistencies in data integration, and for privacy-preserving purposes. Therefore, in this paper, we study similarity graph containment search on large uncertain graph databases. Similarity graph containment search consists of subgraph similarity search and supergraph similarity search. Different from previous works assuming that edges in an uncertain graph are independent of each other, we study uncertain graphs where edges’ occurrences are correlated. We formally prove that subgraph or supergraph similarity search over uncertain graphs is \(\#\)P-hard; thus, we employ a filter-and-verify framework to speed up these two queries. For the subgraph similarity query, in the filtering phase, we develop tight lower and upper bounds of subgraph similarity probability based on a probabilistic matrix index (PMI). PMI is composed of discriminative subgraph features associated with tight lower and upper bounds of subgraph isomorphism probability. Based on PMI, we can filter out a large number of uncertain graphs and maximize the pruning capability. During the verification phase, we develop an efficient sampling algorithm to validate the remaining candidates. For the supergraph similarity query, in the filtering phase, we propose two pruning algorithms, one lightweight and the other strong, based on maximal common subgraphs of query graph and data graph. We run the two pruning algorithms against a probabilistic index that consists of powerful graph features. In the verification, we design an approximate algorithm based on the Horvitz–Thompson estimator to fast validate the remaining candidates. The efficiencies of our proposed solutions to the subgraph and supergraph similarity search have been verified through extensive experiments on real uncertain graph datasets.




























Similar content being viewed by others


Notes
Neighbor edges are the edges that are incident to the same vertex or the edges of a triangle.
In this paper, we consider undirected graphs, although it is straightforward to extend our methods to directed graphs.
Without loss of the generality, in this paper, we assume a query graph is a connected deterministic graph, and an uncertain graph is connected.
According to the subgraph similarity search, insertion does not change the query graph.
For \(g\in SC_{q}\), we have \( d\le \delta \), since the uncertain graphs with \(d>\delta \) have been filtered out in the structural pruning.
In this paper, we use the algorithm in [47] to compute embeddings of a feature in \(g^c\).
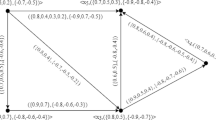
We only show the relaxed queries containing features in graph \(001^c\).
References
Abadi, D.J., Marcus, A., Madden, S.R., Hollenbach, K.: Scalable semantic web data management using vertical partitioning. In: Proceedings of VLDB, pp. 411–422 (2007)
Adar, E., Re, C.: Managing uncertainty in social networks. IEEE Data Eng. Bull. 30(2), 15–22 (2007)
Aggarwal, C.: Managing and Mining Uncertain Data. Springer, Berlin (2009)
Aggarwal, C., Wang, H.: Managing and Mining Graph Data. Springer, Berlin (2010)
Asthana, S., King, O., Gibbons, F., Roth, F.: Predicting protein complex membership using probabilistic network reliability. Genome Res. 14(6), 1170–1175 (2004)
Bader, J.S., Chaudhuri, A., Rothberg, J.M., Chant, J.: Gaining confidence in high-throughput protein interaction networks. Nat. Biotechnol. 22(1), 78–85 (2003)
Balas, E., Xue, J.: Weighted and unweighted maximum clique algorithms with upper bounds from fractional coloring. Algorithmica 15, 397–412 (1996)
Biswas, S., Morris, R.: Exor: opportunistic multi-hop routing for wireless networks. In: Proceedings of SIGCOMM, pp. 133–144 (2005)
Chatr-Aryamontri, A., Ceol, A.E.A.: Mint: the molecular interaction database. Nucleic Acids Res. 35(suppl 1), D572–D574 (2007)
Chui, H., Sung, W.-K., Wong, L.: Exploiting indirect neighbours and topological weight to predict protein function from protein–protein interactions. Bioinformatics 22(13), 47–58 (2007)
Cook, W.J., Cunningham, W.H., Pulleyblank, W.R., Schrijver, A.: Combinatorial Optimization. Wiley-Interscience, London (1997)
Cordellaand, L.P., Foggia, P., Sansone, C.: A (sub)graph isomorphism algorithm for matching large graphs. IEEE Trans. Pattern Anal. Mach. Intell. 38(10), 1367–1372 (2004)
Dalvi, N.N., Suciu, D.: Management of probabilistic data: foundations and challenges. In: Proceedings of PODS, pp. 1–12 (2007)
Hochbaum, D. (ed.): Approximation algorithms for NP-Hard problems. PWS, Boston (1997)
Fishman, G.S.: A monte carlo sampling plan based on product form estimation. In: Proceedings of the 23rd Conference on Winter Simulation, pp. 1012–1017. IEEE Computer Society (1991)
Garey, M.R., Johnson, D.S.: Computers and Intractability: A Guide to the Theory of NP-Completeness. W.H. Freeman, San Francisco (1979)
Guha, R., Kumar, R., Tomkins, A.: Propagation of trust and distrust. In: Proceedings of WWW, pp. 403–412 (2004)
He, H., Singh, A.K.: Closure-tree: an index structure for graph queries. In: Proceedings of ICDE, pp. 27–38 (2006)
Hua, M., Pei, J.: Probabilistic path queries in road networks: traffic uncertainty aware path selection. In: Proceedings of EDBT, pp. 347–358 (2010)
Huang, C., Darwiche, A.: Inference in belief networks: a procedural guide. Int. J. Approx. Reason. 15(3), 225–263 (1996)
Huang, H., Liu, C.: Query evaluation on probabilistic rdf databases. In: Proceedings of WISE, pp. 307–320 (2009)
Jiang, H., Wang, H., Yu, P.S., Zhou, S.: Gstring: a novel approach for efficient search in graph databases. In: Proceedings of ICDE, pp. 566–575 (2007)
Jiang, R., Tu, Z., Chen, T., Sun, F.: Network motif identification in stochastic networks. PNAS 103(25), 9404–9409 (2006)
Jin, R., Liu, L., Ding, B., Wang, H.: Distance-constraint reachability computation in uncertain graphs. In: Proceedings of VLDB, pp. 551–562 (2011)
Karzanov, A.V., Timofeev, E.A.: Efficient algorithm for finding all minimal edge cuts of a nonoriented graph. Cybern. Syst. Anal. 22(2), 156–162 (1986)
Koch, I.: Enumerating all connected maximal common subgraphs in two graphs. Theor. Comput. Sci. 250(1), 1–30 (2001)
Kollios, G., Potamias, M., Terzi, E.: Clustering large probabilistic graphs. TKDE 25(2), 325–336 (2013)
Kozlov, M., Tarasov, S., Hacijan, L.: Polynomial solvability of convex quadratic programming. Math. Dokl. 20, 1108–1111 (1979)
Thompson, S.K.: Sampling the Third Edition. Wiley Series in Probability and Statistics. Wiley, London (2012)
Chen, L., Lian, X.: Efficient query answering in probabilistic rdf graphs. In: Proceedings of SIGMOD, pp. 157–168 (2011)
Liben-Nowell, D., Kleinberg, J.: The link prediction problem for social networks. In: Proceedings of CIKM, pp. 556–569 (2003)
Liu, L., Jin, R., Aggrawal, C., Shen, Y.: Reliable clustering on uncertain graphs. In: Proceedings of ICDM, pp. 459–468. IEEE (2012)
Mitzenmacher, M., Upfal, E.: Probability and Computing: Randomized Algorithms and Probabilistic Analysis. Cambridge University Press, Cambridge (2005)
Moustafa, W.E., Kimmig, A., Deshpande, A., Getoor, L.: Subgraph pattern matching over uncertain graphs with identity linkage uncertainty. In: ICDE, pp. 904–915 (2014)
Potamias, M., Bonchi, F., Gionis, A., Kollios, G.: k-nearest neighbors in uncertain graphs. In: Proceedings of VLDB, pp. 997–1008 (2010)
Rintaro, S., Harukazu, S., Yoshihide, H.: Interaction generality: a measurement to assess the reliability of a protein–protein interaction. Nucleic Acids Res. 30(5), 1163–1168 (2002)
Seshadri, P., Swami, A.N.: Generalized partial indexes. In: Proceedings of ICDE (1995)
Shang, H., Zhang, Y., Lin, X., Yu, J.X.: Taming verification hardness: an efficient algorithm for testing subgraph isomorphism. In: Proceedings of VLDB, pp. 364–375 (2008)
Shang, H., Zhu, K., Lin, X., Zhang, Y., Ichise, R.: Similarity search on supergraph containment. In: Proceedings of ICDE, pp. 637–648 (2010)
Smith, B., Ashburner, M.E.A.: The obo foundry: coordinated evolution of ontologies to support biomedical data integration. Nat. Biotechnol. 25(11), 1251–1255 (2007)
Stonebraker, M.: The case for partial indexes. SIGMOD Rec. 18(4), 4–11 (1989)
Suciu, D., Dalvi, N.N.: Foundations of probabilistic answers to queries. In: Proceedings of SIGMOD, p. 963 (2005)
Suthram, S., Shlomi, T., Ruppin, E., Sharan, R., Ideker, T.: A direct comparison of protein interaction confidence assignment schemes. Bioinformatics 7(1), 360 (2006)
Szklarczyk, D., Franceschini, A., et al.: The string database in 2011: functional interaction networks of proteins, globally integrated and scored. Nucleic Acids Res. 39(8), 561–568 (2011)
Wang, X., Ding, X., Tung, A.K.H., Ying, S., Jin, H.: An efficient graph indexing method. In: Proceedings of ICDE, pp. 805–916 (2012)
Williams, D.W., Huan, J., Wang, W.: Graph database indexing using structured graph decomposition. In: Proceedings of ICDE, pp. 976–985 (2007)
Yan, X., Han, J.: Closegraph: mining closed frequent graph patterns. In: Proceedings of KDD, pp. 286–295 (2003)
Yan, X., Yu, P.S., Han, J.: Graph indexing: a frequent structurebased approach. In: Proceedings of SIGMOD, pp. 335–346 (2004)
Yan, X., Yu, P.S., Han, J.: Substructure similarity search in graph databases. In: Proceedings of SIGMOD, pp. 766–777 (2005)
Yuan, Y., Chen, L., Wang, G.: Efficiently answering probability threshold-based shortest path queries over uncertain graphs. In: Proceedings of DASFAA, pp. 155–170 (2010)
Yuan, Y., Wang, G., Chen, L., Wang, H.: Efficient subgraph similarity search on large probabilistic graph databases. In: Proceedings of VLDB, pp. 800–811 (2012)
Yuan, Y., Wang, G., Chen, L., Wang, H.: Efficient keyword search on uncertain graph data. TKDE 25(12), 2767–2779 (2013)
Yuan, Y., Wang, G., Wang, H., Chen, L.: Efficient subgraph search over large uncertain graphs. In: Proceedings of VLDB, pp. 876–886 (2011)
Zeng, Z., Tung, A.K.H., Wang, J., Zhou, L., Feng, J.: Comparing stars: on approximating graph edit distance. In: Proceedings of VLDB, pp. 25–36 (2009)
Zhang, S., Yang, J., Jin, W.: Sapper: subgraph indexing and approximate matching in large graphs. In: VLDB (2010)
Zhu, G., Lin, X., Zhu, K., Zhang, W., Yu, J.X.: Treespan: efficiently computing similarity all-matching. In: SIGMOD (2012)
Zou, Z., Gao, H., Li, J.: Discovering frequent subgraphs over uncertain graph databases under probabilistic semantics. In: Proceedings of KDD, pp. 633–642 (2010)
Zou, Z., Gao, H., Li, J.: Mining frequent subgraph patterns from uncertain graph data. TKDE 22(9), 1203–1218 (2010)
Acknowledgments
Ye Yuan is supported by the NSFC (Grant No. 61100024) and the Fundamental Research Funds for the Central Universities (Grant No. N130504006). Guoren Wang is supported by the NSFC (Grant No. 61025007, 61328202 and U1401256), National Basic Research Program of China (973, Grant No. 2011CB302200-G), National High Technology Research and Development 863 Program of China (Grant No. 2012AA011004). Lei Chen is supported by the NSFC (Grant No. 61328202), the Hong Kong RGC Project N HKUST637/13, National Grand Fundamental Research 973 Program of China under Grant 2014CB340300, Microsoft Research Asia Gift Grant and Google Faculty Award 2013.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Yuan, Y., Wang, G., Chen, L. et al. Graph similarity search on large uncertain graph databases. The VLDB Journal 24, 271–296 (2015). https://doi.org/10.1007/s00778-014-0373-y
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00778-014-0373-y