
Abstract
This paper studies the problem of how to conduct external sorting on flash drives while avoiding intermediate writes to the disk. The focus is on sort in portable electronic devices, where relations are only larger than the main memory by a small factor, and on sort as part of distributed processes where relations are frequently partially sorted. In such cases, sort algorithms that refrain from writing intermediate results to the disk have three advantages over algorithms that perform intermediate writes. First, on devices in which read operations are much faster than writes, such methods are efficient and frequently outperform Merge Sort. Secondly, they reduce flash cell degradation caused by writes. Thirdly, they can be used in cases where there is not enough disk space for the intermediate results. Novel sort algorithms that avoid intermediate writes to the disk are presented. An experimental evaluation, on different flash storage devices, shows that in many cases the new algorithms can extend the lifespan of the devices by avoiding unnecessary writes to the disk, while maintaining efficiency, in comparison with Merge Sort.








































Similar content being viewed by others

Notes
We used a standard C++ implementation of Quicksort, with random pivot.
References
Ajwani, D., Malinger, I., Meyer, U., Toledo, S.: Characterizing the performance of flash memory storage devices and its impact on algorithm design. In: Proceedings of the 7th International Conference on Experimental Algorithms, pp. 208–219, Provincetown, MA, USA. Springer (2008)
Albutiu, M.-C., Kemper, A., Neumann, T.: Massively parallel sort-merge joins in main memory multi-core database systems. Proc. VLDB Endow. 5(10), 1064–1075 (2012)
Aldous, D., Diaconis, P.: Longest increasing subsequences: from patience sorting to the Baik–Deift–Johansson theorem. Bull. Am. Math. Soc. 36(4), 413–432 (1999)
Balkesen, C., Alonso, G., Teubner, J., Özsu, M.T.: Multi-core, main-memory joins: sort vs. hash revisited. Proc. VLDB Endow. 7(1), 85–96 (2013)
Ben-Moshe, S., Fischer, E., Fischer, M., Kanza, Y., Matsliah, A., Staelin, C.: Detecting and exploiting near-sortedness for efficient relational query evaluation. In: Proceedings of the 14th International Conference on Database Theory, pp. 256–267, Uppsala, Sweden. ACM (2011)
Bender, M.A., Farach-Colton, M., Johnson, R., Kuszmaul, B.C., Medjedovic, D., Montes, P., Shetty, P., Spillane, R.P., Zadok, E.: Don’t thrash: how to cache your hash on flash. In: Proceedings of the 3rd USENIX Conference on Hot Topics in Storage and File Systems, Portland, OR. USENIX Association (2011)
Bonnet, P., Bouganim, L.: Flash device support for database management. In: Fifth Biennial Conference on Innovative Data Systems Research, pp. 1–8. Asilomar, CA, USA (2011)
Brähler, S.: Analysis of the android architecture. Master’s thesis, Karlsruhe Institute (2010). http://os.itec.kit.edu/downloads/sa_2010_braehler-stefan_android-architecture.pdf
Chandramouli, B., Goldstein, J.: Patience is a virtue: revisiting merge and sort on modern processors. In: Proceedings of the 2014 ACM SIGMOD International Conference on Management of Data, pp. 731–742, Snowbird, Utah, USA (2014)
Chen, F., Koufaty, D.A., Zhang, X.: Understanding intrinsic characteristics and system implications of flash memory based solid state drives. In: Proceedings of the Eleventh International Joint Conference on Measurement and Modeling of Computer Systems, pp. 181–192, Seattle, WA, USA. ACM (2009)
Chhugani, J., Nguyen, A.D., Lee, V.W., Macy, W., Hagog, M., Chen, Y.-K., Baransi, A., Kumar, S., Dubey, P.: Efficient implementation of sorting on multi-core simd cpu architecture. Proc. VLDB Endow. 1(2), 1313–1324 (2008)
Cormen, T.H., Stein, C., Rivest, R.L., Leiserson, C.E.: Introduction to Algorithms, 2nd edn. McGraw-Hill Higher Education, New York (2001)
Dean, J., Ghemawat, S.: Mapreduce: simplified data processing on large clusters. Commun. ACM 51(1), 107–113 (2008)
Debnath, B., Sengupta, S., Li, J.: Flashstore: high throughput persistent key-value store. Proc. VLDB Endow. 3(1–2), 1414–1425 (2010)
DeWitt, D.J., Do, J., Patel, J.M., Zhang, D.: Fast peak-to-peak behavior with SSD buffer pool. In: Proceedings of the International Conference on Data Engineering, pp. 1129–1140, Washington, DC, USA. IEEE Computer Society (2013)
Do, J., Kee, Y.-S., Patel, J.M., Park, C., Park, K., DeWitt, D.J.: Query processing on smart SSDs: opportunities and challenges. In: Proceedings of the 2013 ACM SIGMOD International Conference on Management of Data, pp. 1221–1230, New York, NY, USA (2013)
Do, J., Patel, J.M.: Join processing for flash SSDs: remembering past lessons. In: Proceedings of the Fifth International Workshop on Data Management on New Hardware, pp. 1–8, Providence, Rhode Island (2009)
Do, J., Zhang, D., Patel, J.M., DeWitt, D.J., Naughton, J.F., Halverson, A.: Turbocharging DBMS buffer pool using SSDs. In: Proceedings of the 2011 ACM SIGMOD International Conference on Management of Data, pp. 1113–1124, Athens, Greece (2011)
Fredman, M.L.: On computing the length of longest increasing subsequences. Discrete Math. 11(1), 29–35 (1975)
Friedman, R., Hefez, I., Kanza, Y., Levin, R., Safra, E., Sagiv, Y.: Wiser: a web-based interactive route search system for smartphones. In: Proceedings of the 21st International Conference on World Wide Web, pp. 337–340, Lyon, France (2012)
Garcia-Molina, H., Ullman, J.D., Widom, J.: Database Systems: The Complete Book, 2nd edn. Prentice Hall Press, Upper Saddle River (2008)
Gotsman, R., Kanza, Y.: A dilution-matching-encoding compaction of trajectories over road networks. GeoInformatica 19(2), 331–364 (2015)
Graefe, G.: Implementing sorting in database systems. ACM Comput. Surv. 38(3), 1–37 (2006)
Graefe, G.: The five-minute rule 20 years later (and how flash memory changes the rules). Commun. ACM 52(7), 48–59 (2009)
Graefe, G., Harizopoulos, S., Kuno, H.A., Shah, M.A., Tsirogiannis, D., Wiener, J.L.: Designing database operators for flash-enabled memory hierarchies. IEEE Data Eng. Bull. 33(4), 21–27 (2010)
Härder, T.: A scan-driven sort facility for a relational database system. In: Proceedings of the 3rd International Conference on Very Large Data Bases, vol. 3, pp. 236–244, Tokyo, Japan. VLDB Endowment (1977)
Hu, X.-Y., Eleftheriou, E., Haas, R., Iliadis, I., Pletka, R.: Write amplification analysis in flash-based solid state drives. In: Proceedings of SYSTOR: The Israeli Experimental Systems Conference, pp. 10:1–10:9, Haifa, Israel. ACM (2009)
Kang, W.-H., Lee, S.-W., Moon, B.: Flash-based extended cache for higher throughput and faster recovery. Proc. VLDB Endow. 5(11), 1615–1626 (2012)
Knuth, D.E.: Length of strings for a merge sort. Commun. ACM 6(11), 685–688 (1963)
Knuth, D.E.: The Art of Computer Programming: Sorting and Searching, vol. 3, 2nd edn. Addison Wesley Longman Publishing, Redwood City (1998)
Koltsidas, I., Viglas, S.D.: Flashing up the storage layer. Proc. VLDB Endow. 1(1), 514–525 (2008)
Koltsidas, I., Viglas, S.D.: Data management over flash memory. In: Proceedings of the 2011 ACM SIGMOD International Conference on Management of Data, pp. 1209–1212, Athens, Greece (2011)
Kwan, S.C., Baer, J.-L.: The I/O performance of multiway mergesort and tag sort. IEEE Trans. Comput. C–34(4), 383–387 (1985)
Larson, P.-A.: External sorting: run formation revisited. IEEE Trans. Knowl. Data Eng. 15(4), 961–972 (2003)
Larson, P.-A., Graefe, G.: Memory management during run generation in external sorting. In: Proceedings of the 1998 ACM SIGMOD International Conference on Management of Data, pp. 472–483, Seattle, Washington, USA (1998)
Lee, S.-W., Moon, B.: Design of flash-based DBMS: an in-page logging approach. In: Proceedings of the 2007 ACM SIGMOD International Conference on Management of Data, pp. 55–66, Beijing, China (2007)
Lee, S.-W., Moon, B., Park, C., Kim, J.-M., Kim, S.-W.: A case for flash memory SSD in enterprise database applications. In: Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data, pp. 1075–1086, Vancouver, Canada. ACM (2008)
Levin, R., Kanza, Y.: Stratified-sampling over social networks using MapReduce. In: Proceedings of the ACM SIGMOD International Conference on Management of Data, pp. 863–874, Snowbird, Utah, USA (2014)
Liu, X., Salem, K.: Hybrid storage management for database systems. Proc. VLDB Endow. 6(8), 541–552 (2013)
Liu, Y., He, Z., Chen, Y.-P.P., Nguyen, T.: External sorting on flash memory via natural page run generation. Comput. J. 54(11), 1882–1990 (2011)
Mallows, C.: Problem 62–2, patience sorting. SIAM Rev. 4(2), 148–149 (1962)
Mann, S.: Wearable computing: a first step toward personal imaging. Computer 30(2), 25–32 (1997)
Myers, D.: On the use of NAND flash memory in high-performance relational databases. Master’s thesis, Massachusetts Institute of Technology (MIT) (2008). http://hdl.handle.net/1721.1/43070
Nyberg, C., Barclay, T., Cvetanovic, Z., Gray, J., Lomet, D.: Alphasort: a cache-sensitive parallel external sort. VLDB J. 4(4), 603–628 (1995)
Pang, H., Carey, M.J., Livny, M.: Memory-adaptive external sorting. In: Proceedings of the 19th International Conference on Very Large Data Bases, pp. 618–629, San Francisco, CA, USA. Morgan Kaufmann Publishers (1993)
Salzberg, B.: Merging sorted runs using large main memory. Acta Inf. 27(3), 195–215 (1989)
Soundararajan, G., Prabhakaran, V., Balakrishnan, M., Wobber, T.: Extending SSD lifetimes with disk-based write caches. In: Proceedings of the 8th USENIX Conference on File and Storage Technologies, pp. 8–8, Berkeley, CA, USA. USENIX Association (2010)
Tsirogiannis, D., Harizopoulos, S., Shah, M.A., Wiener, J.L., Graefe, G.: Query processing techniques for solid state drives. In: Proceedings of the 35th SIGMOD international Conference on Management of Data, pp. 59–72, Providence, Rhode Island, USA (2009)
Weiser, M.: Some computer science issues in ubiquitous computing. Commun. ACM 36(7), 75–84 (1993)
Zhang, N., Tatemura, J., Patel, J., Hacigumus, H.: Re-evaluating designs for multi-tenant OLTP workloads on SSD-based I/O subsystems. In: Proceedings of the ACM SIGMOD International Conference on Management of Data, pp. 1383–1394, Snowbird, Utah, USA (2014)
Zhang, W., Larson, P.-A.: Dynamic memory adjustment for external Mergesort. In: Proceedings of the 23rd International Conference on Very Large Data Bases, pp. 376–385, San Francisco, CA, USA. Morgan Kaufmann Publishers (1997)
Zhang, W., Larson, P.-A.: Buffering and read-ahead strategies for external Mergesort. In: Proceedings of the 24th International Conference on Very Large Data Bases, pp. 523–533, San Francisco, CA, USA (1998)
Zheng, L., Larson, P.-A.: Speeding up external Mergesort. IEEE Trans. Knowl. Data Eng. 8(2), 322–332 (1996)
Zheng, Y., Xie, X., Ma, W.-Y.: Geolife: a collaborative social networking service among user, location and trajectory. IEEE Data Eng. Bull. 33(2), 32–40 (2010)
Acknowledgments
This research was supported in part by the Israel Science Foundation (Grant 1467/13) and by the Isreali Ministry of Science and Technology (Grant 3-9617). We thank the anonymous reviewers for their insightful comments and suggestions.
Author information
Authors and Affiliations
Corresponding author
Appendices
Appendix 1: Proofs
Proof of Proposition 1.
Proof
Consider element \(A_O[i]\), where \(i\le k/2\). If we do not swap \(A_O[i]\) with \(A_I[i]\), then \(A_O[i]\le A_I[i]\). In this case, \(A_O[i]\) is smaller than the elements \(A_O[i+1], \ldots , A_O[k]\) because \(A_O\) is sorted. Also, \(A_O[i]\) is smaller than the elements \(A_I[i+1], \ldots , A_I[k]\) because \(A_I[i]\) is smaller than these elements due to the order of \(A_I\). Hence, there are at least k elements that are greater than \(A_I[i]\) in the two arrays \(A_O\) and \(A_I\).
If we swap \(A_O[i]\) with \(A_I[i]\), then before the swap the elements \(A_I[i+1], \ldots , A_I[k]\) are greater than \(A_I[i]\) due to the order of \(A_I\). The elements \(A_O[i+1], \ldots , A_O[k]\) are greater than \(A_I[i]\) because they are greater than \(A_O[i]\) and \(A_O[i]> A_I[i]\), as a cause to the swap. Consequently, prior to the swap there are at least k elements greater than \(A_I[i]\) in the two arrays, and after the swap this holds for \(A_I[i]\).
Based on the above two cases \(\{A_O[1], \ldots , A_O[k/2]\}\subset S\). Similar arguments can show that for every element among \(A_I[k/2], \ldots , A_I[k]\) there are at least k elements smaller than it, and hence, \(\{A_I[k/2], \ldots , A_I[k]\}\cap S=\emptyset \).
Finally, we show that after the swaps the arrays are sorted. Consider \(A_O[i]\) and \(A_O[i+1]\), for some \(1\le i \le k-1\). Before the swapping phase, \(A_O[i]\le A_O[i+1]\), since \(A_O\) is initially sorted. Thus, if none of them is swapped, \(A_O[i]\le A_O[i+1]\) holds. If both \(A_O[i]\) and \(A_O[i+1]\) are swapped, then the claim holds because \(A_I\) is initially sorted, so \(A_I[i]\le A_I[i+1]\). If just \(A_O[i]\) and \(A_I[i]\) are swapped, then \(A_I[i]<A_O[i]\), so \(A_I[i]<A_O[i]\le A_O[i+1]\), so the claim holds. If just \(A_O[i+1]\) and \(A_I[i+1]\) are swapped, then \(A_O[i]\le A_I[i]\), because they were not swapped and \(A_I[i]\le A_I[i+1]\) because \(A_I\) is sorted, thus \(A_O[i]\le A_I[i+1]\) before the swap and the claim holds. Similar arguments show that \(A_I\) is sorted after the swaps. \(\square \)
Proof of Lemma 1.
Proof
The union of two different MSCs is not an MSC because otherwise it would contradict maximality—each MSC is a proper subset of the union but cannot be a proper subset of an MSC. The intersection of any two MSCs is an empty set because otherwise their union would be an MSC, in contradiction to the previous statement. \(\square \)
Proof of Proposition 2.
Proof
To prove the existence of a partition, consider the following recursive process. When given a sorted (ascending) sequence, return as a partition a set comprising this sequence. When given a sequence \(t_1, \ldots , t_m\) that contains two consecutive tuples \(t_j\) and \(t_{j+1}\) such that \(t_j[K] > t_{j+1}[K]\), apply the process recursively on \(t_1, \ldots , t_j\) and \(t_{j+1}, \ldots , t_m\) and return the union of the partitions that were computed by the recursive calls.
The recursive process provides a partition of R because tuples of R are never discarded or duplicated in the process. Hence, the created sets are disjoint and cover R. Obviously, every set in the result is a sorted sequence, since otherwise it would have been partitioned. Maximality follows from the fact that the partition is always into sequences \(t_1, \ldots , t_j\) and \(t_{j+1}, \ldots , t_k\) such that \(t_j[K] > t_{j+1}[K]\); thus, extending each such sequence disobeys the order.
To show that a partition is unique, suppose there were two different partitions of R into MSCs. Then there would be a tuple t such that t is in one MSC of the first partition and in a different MSC of the second partition. In this case, the intersection of two different MSCs is not empty, since it contains t, in contradiction to Lemma 1. \(\square \)
Proof of Proposition 3.
Proof
(Sketch) For two tuples \(t_i\) and \(t_j\) that are in the same MSC, their order is the order in the MSC, and hence, it is according to the sort key.
If \(t_i\) is in \(M_i\), \(t_j\) is in \(M_j\) and there is an edge from \(M_i\) to \(M_j\), then \(M_i\) precedes \(M_j\). Suppose \(M_i\) totally precedes \(M_j\). Let \(t^{\prime }_i\) be the last tuple of \(M_i\) and \(t^{\prime }_j\) be the first tuple of \(M_j\). Then, \(t^{\prime }_i[K]\le t^{\prime }_j[K]\), and thus, \(t_i[K]\le t^{\prime }_i[K]\le t^{\prime }_j[K]\le t_j[K]\). Suppose \(M_i\) overlaps and precedes \(M_j\). Let \((t^{\prime }_i, t^{\prime }_j)\) be the connectors of \(M_i\) and \(M_j\). Then, \(t_i[K]\le t^{\prime }_i[K]\le t^{\prime }_j[K]\le t_j[K]\).
The rest of the proof is by induction showing that if \(t_i\) is in \(M_i\), \(t_j\) is in \(M_j\) and there is a path in \(G_R\) from \(M_i\) to \(M_j\), then \(t_i[K]\le t_j[K]\). The induction is on the length of the path where the case of \(M_i\) and \(M_j\) that are connected by an edge is the basis of the induction. \(\square \)
Proof of Proposition 4.
Proof
From Proposition 3 follows that the underlying sequence of \(P_b\) is a sorted sequence. Given a sorted subsequence of R, comprising \(t^{\prime \prime }_1, \ldots , t^{\prime \prime }_{k^{\prime \prime }}\), we partition it by assigning each tuple to the MSC that contains it. Recall that the partition into MSCs is unique (Proposition 2). Let \(M_{i_1}, \ldots , M_{i_n}\) be the MSCs to which we assigned tuples of the given sorted subsequence. Each pair of consecutive tuples \(t^{\prime \prime }_i\), \(t^{\prime \prime }_{i+1}\) in the subsequence, satisfies one of the following cases. (1) Tuples \(t^{\prime \prime }_i, t^{\prime \prime }_{i+1}\) are in the same MSC. (2) Tuples \(t^{\prime \prime }_i, t^{\prime \prime }_{i+1}\) belong to MSCs \(M_i\) and \(M_j\) such that \(M_i\) totally precedes \(M_j\). (3) Tuples \(t^{\prime \prime }_i, t^{\prime \prime }_{i+1}\) belong to MSCs \(M_i\) and \(M_j\) such that \(M_i\) overlaps and precedes \(M_j\). One of these cases must hold. If Case 1 does not hold, \(t^{\prime \prime }_i\) and \(t^{\prime \prime }_{i+1}\) are tuples in two different MSCs such that \(t^{\prime \prime }_i\) appears in R before \(t^{\prime \prime }_{i+1}\) and \(t^{\prime \prime }_i[K]\le t^{\prime \prime }_{i+1}[K]\). In this case, either the MSCs do not overlap (Case 2) or overlap (Case 3). Thus, \(t^{\prime \prime }_1, \ldots , t^{\prime \prime }_{k^{\prime \prime }}\) yields a path in \(G_R\). The MSCs \(M_{i_1}, \ldots , M_{i_n}\) are, therefore, part of a path in \(G_R\). Since the weight of this path is smaller than the weight of \(P_b\), it holds that the number of tuples in \(t^{\prime \prime }_1, \ldots , t^{\prime \prime }_{k^{\prime \prime }}\) does not exceed the number of tuples that \(P_b\) comprises. \(\square \)
Appendix 2: I/O rates
To illustrate the performances of the storage devices on which we ran the tests, we used CrystalDiskMark Footnote 2—a well-known hard drive benchmark.
We performed four different tests on our devices, to examine their characteristics: (1) Sequential read test—4 GB of data were read from the device sequentially, the block size was 1024 KB. (2) Sequential write test—4 GB of data were written to the device sequentially, the block size was 1024 KB. (3) Random read test—4 GB of data were read from the device from random addresses, the block size was 512 KB. (4) Random write test—4 GB of data were written to the device in random addresses, the block size was 512 KB. The tests were performed ten times, the average results were taken, and the rate was calculated. The results are presented in Table 4.
Table 4 shows that the HDD reading rates are almost equal to the writing rates (for both random and sequential accesses). This is non-surprising as there is no difference between reading and writing in HDD. Note that in HDD the writing rates are a little bit better than the reading rates. This is due to the buffering mechanism, which in this benchmark we could not control (as opposed to our experiments). The random I/Os are less efficient than the sequential I/Os, on HDD, due to the large seek time in random access, relatively to the access times in sequential access.
As opposed to the sequential and random read rates of the HDD, we can see that the sequential and random read rates are similar in both SD Card and Micro SD Card. According to [1], the read performances depend on the block size, but usually not on whether the access pattern is random or sequential. We can also see that the sequential read rate is higher than the sequential write rate, in both devices.
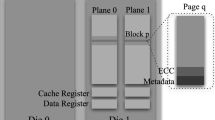
We can see that the SSD performances are good relatively to the other devices. The SSD optimizes the performances in two different levels. (1) An hardware level parallelism is used to perform read, write and erase operations on different planes independently. (2) On the firmware level, the controller of the SSD optimizes the I/O operations while using the garbage collector to erase blocks, as a background process and not immediately. Table 4 shows that the random write performance is relatively poor due to write amplification caused by garbage collection. When writing randomly, the overhead of moving valid pages to other blocks leads to write amplification, which increases the required bandwidth and shortens the time during which the SSD reliably operates [27]. The sequential read rate is slightly better than the random read rate, due to optimizations performed by the controller.
Rights and permissions
About this article

Cite this article
Kanza, Y., Yaari, H. External sorting on flash storage: reducing cell wearing and increasing efficiency by avoiding intermediate writes. The VLDB Journal 25, 495–518 (2016). https://doi.org/10.1007/s00778-016-0426-5
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00778-016-0426-5