
Abstract
Historical data are frequently involved in situations where the available reports on time series are temporally aggregated at different levels, e.g., the monthly counts of people infected with measles. In real databases, the time periods covered by different reports can have overlaps (i.e., time-ticks covered by more than one reports) or gaps (i.e., time-ticks not covered by any report). However, data analysis and machine learning models require reconstructing the historical events in a finer granularity, e.g., the weekly patient counts, for elaborate analysis and prediction. Thus, data disaggregation algorithms are becoming increasingly important in various domains. Time series disaggregation methods commonly utilize domain knowledge about the data, e.g., smoothness, periodicity, or sparsity, to improve the reconstruction accuracy. In this paper, we propose a novel approach, called TurboLift, which aims to improve the quality of the solutions provided by existing disaggregation methods. Starting from a solution produced by a specific method, TurboLift finds a new solution that reduces the disaggregation error and is close to the initial one. We derive a closed-form solution to the proposed formulation of TurboLift that enables us to obtain an accurate reconstruction analytically, without performing resource and time-consuming iterations. Experiments on real data from different domains showcase the effectiveness of TurboLift in terms of disaggregation error, and outlier and anomaly detection.





















Similar content being viewed by others
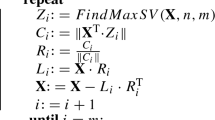


Change history
07 July 2023
A Correction to this paper has been published: https://doi.org/10.1007/s00778-023-00801-4
Notes
The Toeplitz matrix is a matrix in which each descending diagonal from left to right is constant [16].
References
Almutairi, F.M., Yang, F., Song, H.A., Faloutsos, C., Sidiropoulos, N., Zadorozhny, V.: Homerun: scalable sparse-spectrum reconstruction of aggregated historical data. Proc. VLDB Endow. 11(11), 1496–1508 (2018)
Almutairi, F.M., Kanatsoulis, C.I., Sidiropoulos, N.: PREMA: principled tensor data recovery from multiple aggregated views (2019). arXiv preprint arXiv:1910.12001
Bleiholder, J., Naumann, F.: Data fusion. ACM Comput. Surv. (CSUR) 41(1), 1 (2009)
Boyd, S., Parikh, N., Chu, E., Peleato, B., Eckstein, J.: Distributed optimization and statistical learning via the alternating direction method of multipliers. Found. Trends® Mach. Learn. 3(1), 1–122 (2011)
Chen, S., Donoho, D.: Basis pursuit. In: Proceedings of 1994 28th Asilomar Conference on Signals, Systems and Computers, vol. 1, pp. 41–44. IEEE (1994)
Chen, Y., Chen, L., Zhang, C.J.: Crowdfusion: a crowdsourced approach on data fusion refinement. In: 2017 IEEE 33rd International Conference on Data Engineering (ICDE), pp. 127–130. IEEE (2017)
Chow, G.C., Lin, A.: Best linear unbiased interpolation, distribution, and extrapolation of time series by related series. Rev. Econ. Stat. 53(4), 372–375 (1971)
Di Fonzo, T.: The estimation of M disaggregate time series when contemporaneous and temporal aggregates are known. Rev. Econ. Stat. 178–182 (1990)
Dong, X.L., Naumann, F.: Data fusion: resolving data conflicts for integration. Proc. VLDB Endow. 2(2), 1654–1655 (2009)
Dong, X.L., Srivastava, D.: Big data integration. In: 2013 IEEE 29th International Conference on Data Engineering (ICDE), pp. 1245–1248. IEEE (2013)
Donoho, D.L.: Compressed sensing. IEEE Trans. Inf. Theory 52(4), 1289–1306 (2006)
Faloutsos, C., Jagadish, H.V., Sidiropoulos, N.D.: Recovering information from summary data. In: Proceedings of 23rd International Conference on Very Large Data Bases, August 25–29, 1997, Athens, Greece, VLDB’97, pp. 36–45 (1997). http://www.vldb.org/conf/1997/P036.PDF
Golub, G.H., Van Loan, C.F.: Matrix Computations, vol. 3. JHU Press, Baltimore (2012)
Hall, D.L., Jordan, J.M.: Human-Centered Information Fusion. Artech House, Norwood (2010)
Hall, D.L., McMullen, S.A.: Mathematical Techniques in Multisensor Data Fusion. Artech House, Norwood (2004)
Heinig, G., et al.: Algebraic Methods for Toeplitz-Like Matrices and Operators, vol. 13. Birkhauser, Basel (2013)
Holmes, M.P., Isbell, J., Lee, C., Gray, A.G.: QUIC-SVD: Fast SVD using cosine trees. In: Koller, D., Schuurmans, D., Bengio, Y., Bottou, L. (eds.) Advances in Neural Information Processing Systems, vol. 21, pp. 673–680. Curran Associates Inc, New York (2009)
Hormati, A., Vetterli, M.: Annihilating filter-based decoding in the compressed sensing framework. In: Optical Engineering+ Applications, pp. 670121–670121. International Society for Optics and Photonics (2007)
Jaynes, E.T.: The well-posed problem. Found. Phys. 3(4), 477–492 (1973)
Jin, Y.H., Williams, B.D., Tokar, T., Waller, M.A.: Forecasting with temporally aggregated demand signals in a retail supply chain. J. Bus. Logist. 36(2), 199–211 (2015)
Liu, Z., Song, H.A., Zadorozhny, V., Faloutsos, C., Sidiropoulos, N.: H-fuse: efficient fusion of aggregated historical data. In: Proceedings of the 2017 SIAM International Conference on Data Mining, pp. 786–794. SIAM (2017)
Panagiotopoulou, A., Anastassopoulos, V.: Super-resolution image reconstruction techniques: trade-offs between the data-fidelity and regularization terms. Inf. Fusion 13(3), 185–195 (2012)
Pavia-Miralles, J.M.: A survey of methods to interpolate, distribute and extra-polate time series. J. Serv. Sci. Manag. 3(04), 449 (2010)
Pavia-Miralles, J.M., Cabrer-Borras, B.: On estimating contemporaneous quarterly regional GDP. J. Forecast. 26(3), 155–170 (2007)
Rekatsinas, T., Joglekar, M., Garcia-Molina, H., Parameswaran, A., Re, C.: Slimfast: guaranteed results for data fusion and source reliability. In: Proceedings of the 2017 ACM International Conference on Management of Data, pp. 1399–1414. ACM (2017)
Research, F.: Fast randomized SVD. https://research.fb.com/fast-randomized-svd/ (2014)
Rossi, N., et al.: A note on the estimation of disaggregate time series when the aggregate is known. Rev. Econ. Stats. 64(4), 695–696 (1982)
Salinas, R.A., Richardson, C., Abidi, M.A., Gonzalez, R.C.: Data fusion: color edge detection and surface reconstruction through regularization. IEEE Trans. Ind. Electron. 43(3), 355–363 (1996)
Sax, C., Steiner, P.: Temporal Disaggregation of time series. R J. 5(2), 80–88 (2013). http://journal.r-project.org/archive/2013-2/sax-steiner.pdf
Shamir, O.: Fast stochastic algorithms for SVD and PCA: convergence properties and convexity. In: International Conference on Machine Learning, pp. 248–256 (2016)
Stoica, P., Moses, R.L.: Introduction to Spectral Analysis, vol. 1. Prentice Hall, Upper Saddle River (1997)
Tycho: Project tycho: data for health. https://www.tycho.pitt.edu (2013)
Van Panhuis, W.G., Grefenstette, J., Jung, S.Y., Chok, N.S., Cross, A., Eng, H., Lee, B.Y., Zadorozhny, V., Brown, S., Cummings, D., et al.: Contagious diseases in the United States from 1888 to the present. N. Engl. J. Med. 369(22), 2152 (2013)
Yang, F., Song, H.A., Liu, Z., Faloutsos, C., Zadorozhny, V., Sidiropoulos, N.: Ares: automatic disaggregation of historical data. In: 2018 IEEE 34th International Conference on Data Engineering (ICDE), pp. 65–76. IEEE (2018)
Zadorozhny, V., Grant, J.: A systematic approach to reliability assessment in integrated databases. J. Intell. Inf. Syst. 46(3), 409–424 (2016)
Zadorozhny, V., Lewis, M.: Information fusion for usar operations based on crowdsourcing. In: 16th International Conference on Information Fusion (FUSION), pp. 1450–1457. IEEE (2013)
Zhu, Y., Comaniciu, D., Pellkofer, M., Koehler, T.: Reliable detection of overtaking vehicles using robust information fusion. IEEE Trans. Intell. Transp. Syst. 7(4), 401–414 (2006)
Acknowledgements
This material is based upon work supported by the National Science Foundation under Grants Nos. IIS-1247489, IIS-1247632. This work is also partially supported by an IBM Faculty Award and a Google Focused Research Award. V. Zadorozhny was partially supported by NSF BCS-1244672 Grant. N. Sidiropoulos was partially supported by NSF IIS-1247632 and IIS-1447788. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation, or other funding parties. The U.S. Government is authorized to reproduce and distribute reprints for Government purposes notwithstanding any copyright notation here on.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The original article was revised due to update in affiliation of second author.
A preliminaries of the analytical solution
A preliminaries of the analytical solution
In this section introduce some mathematical background to facilitate the understanding of the Lemma 1
-
\(\textbf{A}^T\textbf{A} \in \mathcal {R} ^ {N \times N}\) is a positive semi-definite matrix.
-
The singular value decomposition (SVD) of \(\textbf{A}^T\textbf{A}\) is \(\textbf{U} {\varvec{\Sigma }} \textbf{U}^T\), where \(\textbf{U} \in \mathcal {R}^{N\times N} \) contains a set of singular vectors of \(\textbf{A}^T\textbf{A}\) and \({\varvec{\Sigma }} \in \mathcal {R}^{N\times N}\) is a diagonal matrix with non-negative singular values \(\lambda _i >= 0\) \((i = 1,2,\ldots ,N)\) on the diagonal.
-
The singular value matrix \({\varvec{\Sigma }}a\) can be written as a partitioned matrix \( \begin{bmatrix} {\varvec{\Sigma }}_1 &{} 0 \\ 0 &{} 0 \end{bmatrix} \) where \({\varvec{\Sigma }}_1 \in \mathcal {R}^{M \times M}\) contains all nonzero singular values. Correspondingly the matrix \(\textbf{U}\) can split into two parts \([\textbf{U}_1, \textbf{U}_2]\), where \(\textbf{U}_1 \in \mathcal {R}^{N\times M}\) contains the singular vectors corresponding to the nonzero singular values, while \(\textbf{U}_2 \in \mathcal {R}^{N\times (N-M)}\) contains the remaining part. Based on the property of a singular vector, \(\textbf{U}_1 \perp \textbf{U}_2\) \((\textbf{U}_1^T\textbf{U}_2 = 0)\) and \(\textbf{U}_2 \perp \textbf{A}^T\) \((\textbf{U}_2^T\textbf{A}^T = 0)\)
-
Suppose we have
$$\begin{aligned} {\varvec{\Lambda }}&= {\varvec{\Sigma }} + \textbf{I}_n \\&= \begin{bmatrix} {\varvec{\Sigma }}_1 &{} \quad \textbf{0} \\ \textbf{0} &{} \quad \textbf{0} \end{bmatrix} + \begin{bmatrix} \textbf{I}_M &{}\quad \textbf{0} \\ \textbf{0} &{} \quad \textbf{I}_{N-M} \end{bmatrix} \\&= \begin{bmatrix} \lambda _1+1 &{} \quad ...&{} \quad 0 &{}\quad .&{}\quad .&{}\quad 0\\ ... &{} \quad . &{} \quad .&{} \quad . &{} \quad . &{} \quad ...\\ 0 &{} \quad ... &{} \quad \lambda _{M}+1&{} \quad .&{} \quad . &{} \quad 0\\ 0 &{} \quad ... &{} \quad 0 &{} \quad 1 &{} \quad ... &{} \quad 0\\ ... &{} \quad . &{} \quad .&{} \quad . &{} \quad . &{} \quad ...\\ 0 &{} \quad ... &{} \quad 0 &{} \quad 0 &{} \quad ... &{} \quad 1\\ \end{bmatrix} \end{aligned}$$where \(\lambda _i + 1 > 1\) \((i = 1,2,\ldots ,M)\) and \(\textbf{I}_n\) is the n-dimension identity matrix.
From the geometric series,
$$\begin{aligned} \frac{1}{\beta } + \left( \frac{1}{\beta }\right) ^2 + \cdots + \left( \frac{1}{\beta }\right) ^n&\\ =&\frac{1}{\beta }(1 + \cdots +\left( \frac{1}{\beta }\right) ^{n-1}) \\ =&\frac{1-\beta ^{-n}}{\beta -1} \end{aligned}$$With \(n \rightarrow \infty \), if \(\beta > 1\), the equation converge to \(\frac{1}{\beta -1}\), while if \(\beta = 1\), the equation equal to n.
Then
$$\begin{aligned} \lim _{n \rightarrow \infty }\sum _{k=1}^n{\varvec{\Lambda }}^{-k} =n \begin{bmatrix} \frac{1}{\lambda _1} &{} \quad ...&{} \quad 0 &{}\quad .&{}\quad .&{} \quad 0\\ ... &{} \quad . &{} \quad .&{}\quad . &{}\quad . &{} \quad ...\\ 0 &{} \quad ... &{} \quad \frac{1}{\lambda _{M}}&{} \quad .&{} \quad . &{} \quad 0\\ 0 &{} \quad ... &{} \quad 0 &{} \quad n &{} \quad ... &{} \quad 0\\ ... &{} \quad . &{} \quad .&{} \quad . &{} \quad . &{} \quad ...\\ 0 &{} \quad ... &{} \quad 0 &{} \quad 0 &{} \quad ... &{} \quad n\\ \end{bmatrix} \end{aligned}$$ -
Since \(\lim _{n \rightarrow \infty } \frac{1}{\beta ^n} = 0\), for \(\beta > 1\),
$$\begin{aligned}&\lim _{n \rightarrow \infty } {\varvec{\Lambda }} ^{-n} = \\&\lim _{n \rightarrow \infty }\begin{bmatrix} \frac{1}{(\lambda _1+1)^n} &{} \quad ...&{} \quad 0 &{}\quad .&{}\quad .&{} \quad 0\\ ... &{} \quad . &{} \quad .&{} \quad . &{} \quad . &{} \quad ...\\ 0 &{} \quad ... &{}\quad \frac{1}{(\lambda _{M}+1)^n}&{}\quad .&{} \quad . &{} \quad 0\\ 0 &{} \quad ... &{} \quad 0 &{} \quad 1 &{} \quad ... &{} \quad 0\\ ... &{} \quad . &{} \quad .&{} \quad . &{} \quad . &{} \quad ...\\ 0 &{} \quad ... &{} \quad 0 &{} \quad 0 &{} \quad ... &{} \quad 1\\ \end{bmatrix} \\&=\begin{bmatrix} 0 &{} \quad ...&{} \quad 0 &{}\quad .&{}\quad .&{} \quad 0\\ ... &{} \quad . &{} \quad .&{} \quad . &{} \quad . &{} \quad ...\\ 0 &{} \quad ... &{} \quad 0&{} \quad .&{} \quad . &{} \quad 0\\ 0 &{} \quad ... &{} \quad 0 &{} \quad 1 &{} \quad ... &{} \quad 0\\ ... &{} \quad . &{} \quad .&{} \quad . &{} \quad . &{} \quad ...\\ 0 &{} \quad ... &{} \quad 0 &{} \quad 0 &{} \quad ... &{} \quad 1\\ \end{bmatrix} = \begin{bmatrix} 0 &{}\quad 0 \\ 0 &{} \quad \textbf{I}_{N-M} \end{bmatrix} \end{aligned}$$
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Yang, F., Almutairi, F.M., Song, H.A. et al. TurboLift: fast accuracy lifting for historical data recovery. The VLDB Journal 29, 1129–1148 (2020). https://doi.org/10.1007/s00778-020-00609-6
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00778-020-00609-6