
Abstract
We present \(\textsf{Ditto}\), a novel entity matching system based on pre-trained Transformer language models. We fine-tune and cast EM as a sequence-pair classification problem to leverage such models with a simple architecture. Our experiments show that a straightforward application of language models such as BERT, DistilBERT, or RoBERTa pre-trained on large text corpora already significantly improves the matching quality and outperforms previous state-of-the-art (SOTA), by up to 29% of F1 score on benchmark datasets. We also developed three optimization techniques to further improve \(\textsf{Ditto}\) ’s matching capability. \(\textsf{Ditto}\) allows domain knowledge to be injected by highlighting important pieces of input information that may be of interest when making matching decisions. \(\textsf{Ditto}\) also summarizes strings that are too long so that only the essential information is retained and used for EM. Finally, \(\textsf{Ditto}\) adapts a SOTA technique on data augmentation for text to EM to augment the training data with (difficult) examples. This way, \(\textsf{Ditto}\) is forced to learn “harder” to improve the model’s matching capability. The optimizations we developed further boost the performance of \(\textsf{Ditto}\) by up to 9.8%. Perhaps more surprisingly, we establish that \(\textsf{Ditto}\) can achieve the previous SOTA results with at most half the number of labeled data. Finally, we demonstrate \(\textsf{Ditto}\) ’s effectiveness on a real-world large-scale EM task. On matching two company datasets consisting of 789K and 412K records, \(\textsf{Ditto}\) achieves a high F1 score of 96.5%.








Similar content being viewed by others
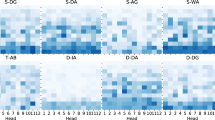


Notes
In DeepMatcher, the requirement that both entries have the same schema can be removed by treating the concatenation of the values in all columns as one value under one attribute.
References
Abuzaid, F., Sethi, G., Bailis, P., Zaharia, M.: To index or not to index: optimizing exact maximum inner product search. In: Proceedings of ICDE ’19, pp. 1250–1261. IEEE (2019)
Baraldi, A., Buono, F.D., Paganelli, M., Guerra, F.: Using landmarks for explaining entity matching models. In: EDBT, pp. 451–456 (2021)
Barlaug, N.: LEMON: explainable entity matching (2021). CoRR arXiv:2110.00516
Baxter, L.R., Baxter, R., Christen, P., et al.: A comparison of fast blocking methods for record (2003)
Beltagy, I., Lo, K., Cohan, A.: Scibert: a pretrained language model for scientific text (2019). arXiv preprint arXiv:1903.10676
Bilenko, M., Mooney, R.J.: Adaptive duplicate detection using learnable string similarity measures. In: Proceedings KDD ’03, pp. 39–48 (2003)
Bojanowski, P., Grave, E., Joulin, A., Mikolov, T.: Enriching word vectors with subword information. TACL 5, 135–146 (2017)
Brunner, U., Stockinger, K.: Entity matching with transformer architectures—a step forward in data integration. In: EDBT (2020)
Chen, Q., Zhu, X., Ling, Z.H., Inkpen, D., Wei, S.: Neural natural language inference models enhanced with external knowledge. In: Proceedings of ACL ’18, pp. 2406–2417 (2018)
Christen, P.: A survey of indexing techniques for scalable record linkage and deduplication. TKDE 24(9), 1537–1555 (2011)
Cicco, V.D., Firmani, D., Koudas, N., Merialdo, P., Srivastava, D.: Interpreting deep learning models for entity resolution: an experience report using LIME. In: aiDM@SIGMOD, pp. 8:1–8:4 (2019)
Clark, K., Khandelwal, U., Levy, O., Manning, C.D.: What does BERT look at? An analysis of BERT’s attention. In: Proceedings of BlackBoxNLP ’19, pp. 276–286 (2019)
Cohen, W.W., Richman, J.: Learning to match and cluster large high-dimensional data sets for data integration. In: Proceedings of KDD ’02, pp. 475–480 (2002)
Dalvi, N., Rastogi, V., Dasgupta, A., Das Sarma, A., Sarlos, T.: Optimal hashing schemes for entity matching. In: Proceeding of WWW ’13, pp. 295–306 (2013)
Das, S., Doan, A., Psgc, G.C., Gokhale, C., Konda, P., Govind, Y., Paulsen, D.: The magellan data repository. https://sites.google.com/site/anhaidgroup/projects/data
De Bruin, J.: Python Record Linkage Toolkit: a toolkit for record linkage and duplicate detection in Python (2019)
Devlin, J., Chang, M.W., Lee, K., Toutanova, K.: BERT: pre-training of deep bidirectional transformers for language understanding. In: Proceedings of NAACL-HLT ’19, pp. 4171–4186 (2019)
Ebaid, A., Thirumuruganathan, S., Aref, W.G., Elmagarmid, A.K., Ouzzani, M.: EXPLAINER: entity resolution explanations. In: ICDE, pp. 2000–2003 (2019)
Ebraheem, M., Thirumuruganathan, S., Joty, S., Ouzzani, M., Tang, N.: Distributed representations of tuples for entity resolution. PVLDB 11(11), 1454–1467 (2018)
Elmagarmid, A., Ilyas, I.F., Ouzzani, M., Quiané-Ruiz, J.A., Tang, N., Yin, S.: NADEEF/ER: generic and interactive entity resolution. In: Proceedings of SIGMOD ’14, pp. 1071–1074 (2014)
Fisher, J., Christen, P., Wang, Q., Rahm, E.: A clustering-based framework to control block sizes for entity resolution. In: Proceedings of KDD ’15, pp. 279–288 (2015)
Fu, C., Han, X., Sun, L., Chen, B., Zhang, W., Wu, S., Kong, H.: End-to-end multi-perspective matching for entity resolution. In: Proceedings of IJCAI ’19, pp. 4961–4967. AAAI Press (2019)
Ge, C., Wang, P., Chen, L., Liu, X., Zheng, B., Gao, Y.: Collaborer: a self-supervised entity resolution framework using multi-features collaboration (2021). CoRR arXiv:2108.08090
Gokhale, C., Das, S., Doan, A., Naughton, J.F., Rampalli, N., Shavlik, J., Zhu, X.: Corleone: hands-off crowdsourcing for entity matching. In: Proceedings of SIGMOD ’14, pp. 601–612 (2014)
Gurajada, S., Popa, L., Qian, K., Sen, P.: Learning-based methods with human-in-the-loop for entity resolution. In: CIKM, pp. 2969–2970 (2019)
He, Y., Ganjam, K., Lee, K., Wang, Y., Narasayya, V., Chaudhuri, S., Chu, X., Zheng, Y.: Transform-data-by-example (tde) extensible data transformation in excel. In: SIGMOD, pp. 1785–1788 (2018)
Heer, J., Hellerstein, J.M., Kandel, S.: Predictive interaction for data transformation. In: CIDR (2015)
Hochreiter, S., Schmidhuber, J.: Long short-term memory. Neural Comput. 9(8), 1735–1780 (1997)
Jain, A., Sarawagi, S., Sen, P.: Deep indexed active learning for matching heterogeneous entity representations. PVLDB 15(1), 31–45 (2021)
Jin, D., Sisman, B., Wei, H., Dong, X.L., Koutra, D.: Deep transfer learning for multi-source entity linkage via domain adaptation. PVLDB 15(3), 465–477 (2021)
Kasai, J., Qian, K., Gurajada, S., Li, Y., Popa, L.: Low-resource deep entity resolution with transfer and active learning. In: Proceedings of ACL ’19, pp. 5851–5861 (2019)
Kingma, D.P., Ba, J.: Adam: A method for stochastic optimization (2014). arXiv preprint arXiv:1412.6980
Konda, P., Das, S., GC, P.S., Doan, A., Ardalan, A., Ballard, J.R., Li, H., Panahi, F., Zhang, H., Naughton, J.F., Prasad, S., Krishnan, G., Deep, R., Raghavendra, V.: Magellan: toward building entity matching management systems. PVLDB 9(12), 1197–1208 (2016)
Köpcke, H., Thor, A., Rahm, E.: Evaluation of entity resolution approaches on real-world match problems. PVLDB 3(1–2), 484–493 (2010)
Lample, G., Conneau, A.: Cross-lingual language model pretraining (2019). arXiv preprint arXiv:1901.07291
Lee, J., Yoon, W., Kim, S., Kim, D., Kim, S., So, C.H., Kang, J.: Biobert: a pre-trained biomedical language representation model for biomedical text mining. Bioinformatics 36(4), 1234–1240 (2020)
Lewis, M., Liu, Y., Goyal, N., Ghazvininejad, M., Mohamed, A., Levy, O., Stoyanov, V., Zettlemoyer, L.: BART: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. In: ACL, pp. 7871–7880 (2020)
Li, B., Miao, Y., Wang, Y., Sun, Y., Wang, W.: Improving the efficiency and effectiveness for bert-based entity resolution. In: AAAI, vol. 35, pp. 13226–13233 (2021)
Li, P., Cheng, X., Chu, X., He, Y., Chaudhuri, S.: Auto-FuzzyJoin: Auto-program Fuzzy Similarity Joins Without Labeled Examples, pp. 1064–1076. Association for Computing Machinery, New York (2021)
Li, Y., Li, J., Suhara, Y., Doan, A., Tan, W.C.: Deep entity matching with pre-trained language models (2020). arXiv preprint arXiv:2004.00584
Li, Y., Li, J., Suhara, Y., Wang, J., Hirota, W., Tan, W.C.: Deep entity matching: challenges and opportunities. J. Data Inf. Qual. (JDIQ) 13(1), 1–17 (2021)
Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., Levy, O., Lewis, M., Zettlemoyer, L., Stoyanov, V.: RoBERTa: a robustly optimized bert pretraining approach (2019). arXiv preprint arXiv:1907.11692
Marcus, A., Wu, E., Karger, D.R., Madden, S., Miller R.C.: Human-powered sorts and joins. PVLDB 5(1), 13–24 (2011)
Meduri, V.V., Popa, L., Sen, P., Sarwat, M.: A comprehensive benchmark framework for active learning methods in entity matching. In: SIGMOD, pp. 1133–1147 (2020)
Miao, Z., Li, Y., Wang, X.: Rotom: a meta-learned data augmentation framework for entity matching, data cleaning, text classification, and beyond. In: SIGMOD, pp. 1303–1316 (2021)
Miao, Z., Li, Y., Wang, X., Tan, W.C.: Snippext: semi-supervised opinion mining with augmented data. In: Proceedings of WWW ’20 (2020)
Mihalcea, R., Tarau, P.: TextRank: bringing order into text. In: Proceedings of EMNLP ’04, pp. 404–411 (2004)
Mitchell, T.M., et al.: Machine Learning, vol. 45, no. 37, pp. 870–877. McGraw Hill, Burr Ridge (1997)
Mudgal, S., Li, H., Rekatsinas, T., Doan, A., Park, Y., Krishnan, G., Deep, R., Arcaute, E., Raghavendra, V.: Deep learning for entity matching: a design space exploration. In: Proceedings of SIGMOD ’18, pp. 19–34 (2018)
Papadakis, G., Skoutas, D., Thanos, E., Palpanas, T.: Blocking and filtering techniques for entity resolution: a survey (2019). arXiv preprint arXiv:1905.06167
Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., Killeen, T., Lin, Z., Gimelshein, N., Antiga, L., et al.: PyTorch: an imperative style, high-performance deep learning library. In: Proceedings of NeurIPS ’19, pp. 8024–8035 (2019)
Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., Blondel, M., Prettenhofer, P., Weiss, R., Dubourg, V., et al.: Scikit-learn: machine learning in python. J. Mach. Learn. Res. 12, 2825–2830 (2011)
Peeters, R., Bizer, C.: Cross-language learning for entity matching (2021). arXiv preprint arXiv:2110.03338
Peeters, R., Bizer, C.: Dual-objective fine-tuning of bert for entity matching. PVLDB 14(10), 1913–1921 (2021)
Pennington, J., Socher, R., Manning, C.D.: Glove: global vectors for word representation. In: Proceedings of EMNLP ’14, pp. 1532–1543 (2014)
Primpeli, A., Peeters, R., Bizer, C.: The WDC training dataset and gold standard for large-scale product matching. In: Companion Proceedings of WWW ’19, pp. 381–386 (2019)
Qian, K., Popa, L., Sen, P.: Active learning for large-scale entity resolution. In: CIKM, pp. 1379–1388 (2017)
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., Sutskever, I.: Language models are unsupervised multitask learners. OpenAI Blog 1(8), 9 (2019)
Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li, W., Liu, P.J.: Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res. 21(140), 1–67 (2020)
Ratner, A., Bach, S.H., Ehrenberg, H., Fries, J., Wu, S., Ré, C.: Snorkel: rapid training data creation with weak supervision. PVLDB 11, 269 (2017)
Reimers, N., Gurevych, I.: Sentence-BERT: sentence embeddings using Siamese BERT-networks. In: Proceedings of EMNLP-IJCNLP ’19, pp. 3982–3992 (2019)
Ribeiro, M.T., Singh, S., Guestrin, C.: “Why should I trust you?”: explaining the predictions of any classifier. In: ACM SIGKDD, pp. 1135–1144 (2016)
Rush, A.M., Chopra, S., Weston, J.: A neural attention model for abstractive sentence summarization. In: Proceedings of EMNLP ’15 (2015)
Saeedi, A., Peukert, E., Rahm, E.: Using link features for entity clustering in knowledge graphs. In: ESWC, Lecture Notes in Computer Science, vol. 10843, pp. 576–592. Springer (2018)
Sanh, V., Debut, L., Chaumond, J., Wolf, T.: DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter. In: Proceedings of \(\text{EMC}^2\) ’19 (2019)
Sarawagi, S., Bhamidipaty, A.: Interactive deduplication using active learning. In: Proceedings of KDD ’02, pp. 269–278 (2002)
Singh, R., Meduri, V.V., Elmagarmid, A., Madden, S., Papotti, P., Quiané-Ruiz, J.A., Solar-Lezama, A., Tang, N.: Synthesizing entity matching rules by examples. PVLDB 11(2), 189–202 (2017)
Stoyanovich, J., Howe, B., Jagadish, H.V.: Responsible data management. PVLDB 13(12), 3474–3488 (2020)
Sun, Y., Wang, S., Li, Y., Feng, S., Chen, X., Zhang, H., Tian, X., Zhu, D., Tian, H., Wu, H.: ERNIE: enhanced representation through knowledge integration (2019). arXiv preprint arXiv:1904.09223
Suri, S., Ilyas, I.F., Ré, C., Rekatsinas, T.: Ember: no-code context enrichment via similarity-based keyless joins. PVLDB 15(3), 699–712 (2021)
Tang, N., Fan, J., Li, F., Tu, J., Du, X., Li, G., Madden, S., Ouzzani, M.: RPT: relational pre-trained transformer is almost all you need towards democratizing data preparation. PVLDB 14(8), 1254–1261 (2021)
Tenney, I., Das, D., Pavlick, E.: BERT rediscovers the classical NLP pipeline. In: Proceedings of ACL ’19, pp. 4593–4601 (2019)
Teofili, T., Firmani, D., Koudas, N., Martello, V., Merialdo, P., Srivastava, D.: Effective explanations for entity resolution models. In: ICDE, pp. 2709–2721. IEEE (2022)
Thirumuruganathan, S., Li, H., Tang, N., Ouzzani, M., Govind, Y., Paulsen, D., Fung, G., Doan, A.: Deep learning for blocking in entity matching: a design space exploration. PVLDB 14(11), 2459–2472 (2021)
Tu, J., Han, X., Fan, J., Tang, N., Chai, C., Li, G., Du, X.: Dader: hands-off entity resolution with domain adaptation. PVLDB 15(12), 3666–3669 (2022)
Varma, P., Ré, C.: Snuba: automating weak supervision to label training data. PVLDB 12, 223 (2018)
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, Ł., Polosukhin, I.: Attention is all you need. In: Proceedings of NIPS ’17, pp. 5998–6008 (2017)
Wang, J., Kraska, T., Franklin, M.J., Feng, J.: CrowdER: crowdsourcing entity resolution. PVLDB 5(11), 1483–1494 (2012)
Wang, J., Li, G., Yu, J.X., Feng, J.: Entity matching: how similar is similar. PVLDB 4(10), 622–633 (2011)
Wang, P., Zheng, W., Wang, J., Pei, J.: Automating entity matching model development. In: ICDE, pp. 1296–1307. IEEE (2021)
Wang, Q., Cui, M., Liang, H.: Semantic-aware blocking for entity resolution. TKDE 28(1), 166–180 (2015)
Wang, X., He, X., Cao, Y., Liu, M., Chua, T.S.: KGAT: knowledge graph attention network for recommendation. In: Proceedings of KDD ’19, pp. 950–958 (2019)
WDC Product Data Corpus: http://webdatacommons.org/largescaleproductcorpus/v2
Wei, J., Zou, K.: EDA: easy data augmentation techniques for boosting performance on text classification tasks. In: Proceedings of EMNLP-IJCNLP ’19, pp. 6382–6388 (2019)
Wolf, T., Debut, L., Sanh, V., Chaumond, J., Delangue, C., Moi, A., Cistac, P., Rault, T., Louf, R., Funtowicz, M., et al.: Huggingface’s transformers: state-of-the-art natural language processing (2019). arXiv preprint arXiv:1910.03771
Wu, R., Bendeck, A., Chu, X., He, Y.: Ground truth inference for weakly supervised entity matching (2022). arXiv preprint arXiv:2211.06975
Wu, R., Chaba, S., Sawlani, S., Chu, X., Thirumuruganathan, S.: Zeroer: entity resolution using zero labeled examples. In: SIGMOD, pp. 1149–1164. Association for Computing Machinery, New York (2020)
Wu, R., Sakala, P., Li, P., Chu, X., He, Y.: Demonstration of panda: a weakly supervised entity matching system. PVLDB 14(12), 2735–2738 (2021)
Xiao, C., Wang, W., Lin, X., Yu, J.X., Wang, G.: Efficient similarity joins for near-duplicate detection. TODS 36(3), 15:1–15:41 (2011)
Xie, Q., Dai, Z., Hovy, E., Luong, M.T., Le, Q.V.: Unsupervised data augmentation (2019). arXiv preprint arXiv:1904.12848
Yang, B., Mitchell, T.: Leveraging knowledge bases in LSTMs for improving machine reading. In: Proceedings of ACL ’17, pp. 1436–1446 (2017)
Yang, Z., Dai, Z., Yang, Y., Carbonell, J., Salakhutdinov, R.R., Le, Q.V.: XLNet: generalized autoregressive pretraining for language understanding. In: Proceedings of NeurIPS ’19, pp. 5754–5764 (2019)
Zhang, D., Li, D., Guo, L., Tan, K.: Unsupervised entity resolution with blocking and graph algorithms. TKDE 34(3), 1501–1515 (2022)
Zhang, H., Cisse, M., Dauphin, Y.N., Lopez-Paz, D.: mixup: beyond empirical risk minimization. In: Proceedings of ICLR ’18 (2018)
Zhao, C., He, Y.: Auto-EM: end-to-end fuzzy entity-matching using pre-trained deep models and transfer learning. In: Proceedings of WWW ’19, pp. 2413–2424 (2019)
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Yuliang Li, Yoshi Suhara and Wang-Chiew Tan: Work done while the author was at Megagon Labs.
Appendices
Appendix
A Breakdown of the DM+ results and experiments
In this section, we provide a detailed summary of how we obtain the DeepMatcher+ (DM+) baseline results. Recall from Sect. 4.2 that DM+ is obtained by taking the best performance (highest F1 scores) of multiple baseline methods including DeepER [19], Magellan [33], DeepMatcher [49], and DeepMatcher’s follow-up work [22, 31].
We summarize these baseline results in Table 12 on the ER-Magellan benchmarks and explain each method next.
DeepER The original paper [19] proposes a DL-based framework for EM. Similar to DeepMatcher, DeepER first aggregates both data entries into their vector representations and uses a feedforward neural network to perform the binary classification based on the similarity of the two vectors. Each vector representation is obtained either by a simple averaging over the GloVe [55] embeddings per attribute or a RNN module over the serialized data entry. DeepER computes the similarity as the cosine similarity of the two vectors. Although [19] reported results on the Walmart-Amazon, Amazon-Google, DBLP-ACM, DBLP-Scholar, and the Fodors-Zagat datasets, the numbers are not directly comparable to the presented results of \(\textsf{Ditto}\) because their evaluation and data preparation methods are different (e.g., they used k-fold cross-validation, while we use the train/valid/test splits according to [49]). In our experiments, we implemented DeepER with LSTM as the RNN module and GloVe for the tokens embeddings as described in [19] and with the same hyper-parameters (a learning rate of 0.01 and the Adam optimizer [32]). We then evaluate DeepER in our evaluation settings. For each dataset, we report the best results obtained by the simple aggregation and the RNN-based method.
DeepMatcher (DM) We have summarized DM in Sect. 4.2. In addition to simply taking the numbers from the original paper [49], we also ran their open-source version (DM (reproduced)) with the default settings (the hybrid model with a batch size of 32 and 15 epochs). The reproduced results are in general lower than the original reported numbers in [49] (the 3rd column) because we did not try the other model variants and hyperparameters as in the original experiments. The code failed in the Fodors-Zagat and the Company datasets because of out-of-memory errors.
In addition, one key difference between DM and \(\textsf{Ditto}\) is that \(\textsf{Ditto}\) serializes the data entries while DM does not. One might wonder if DM can obtain better results by simply replacing its input with the serialized entries produced by \(\textsf{Ditto}\). We found that the results do not significantly improve overall, but it is up to 5.2% in the Abt-Buy dataset.
Others We obtained the results for Magellan by taking the reported results from [49] and the two follow-up works [22, 31] of DeepMatcher (denoted as ACL ’19 and IJCAI ’19 in Table 12). We did not repeat the experiments since they have the same evaluation settings as ours.
B The difference between Ditto and a recent work
There is a recent work [8] that also applies pre-trained LMs to entity matching and obtained good results. The method proposed in [8] is essentially identical to the baseline version of \(\textsf{Ditto}\) which only serializes the data entries into text sequences and fine-tunes the LM on the binary sequence-pair classification task. On top of that, \(\textsf{Ditto}\) also applies 3 optimizations of injecting domain knowledge, data augmentation, and summarization to further improve the model’s performance. We also evaluate \(\textsf{Ditto}\) more comprehensively as we tested \(\textsf{Ditto}\) on all the 13 ER-Magellan datasets, the WDC product benchmark, and a company matching dataset, while [8] experimented in 5/13 of the ER-Magellan datasets.
On these 5 evaluated datasets, one might notice that the reported F1 scores in [8] are slightly higher compared to the baseline’s F1 scores shown in Table 5. The reason is that according to [8], for each run on each dataset, the F1 score is computed as the model’s best F1 score on the test set among all the training epochs, while we report the test F1 score of the epoch with the best F1 on the validation set. Our evaluation method is more standard since it prevents overfitting the test set (see Chapter 4.6.5 of [48]) and is also used by DeepMatcher and Magellan [49]. It is not difficult to see that over the same set of model snapshots, the F1 score computed by the [8]’s evaluation method would be greater or equal to the F1 score computed using our method, which explains the differences in the reported values between us and [8].
Table 13 summarizes the detailed comparison of the baseline \(\textsf{Ditto}\), the proposed method in [8], and the full \(\textsf{Ditto}\). Recall that we construct the baseline by taking the best performing pre-trained model among DistilBERT [65], BERT [17], XLNet [93], and RoBERTa [42] following [8]. Although the baseline \(\textsf{Ditto}\) does not outperform [8] because of the different evaluation methods, the optimized \(\textsf{Ditto}\) is able to outperform [8] in 4/5 of the evaluated datasets.
See Table 14.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Li, Y., Li, J., Suhara, Y. et al. Effective entity matching with transformers. The VLDB Journal 32, 1215–1235 (2023). https://doi.org/10.1007/s00778-023-00779-z
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00778-023-00779-z