
Abstract
Time series is traditionally treated with two main approaches, i.e., the time domain approach and the frequency domain approach. These approaches must rely on a sliding window so that time-shift versions of a sequence can be measured to be similar. Coupled with the use of a root point-to-point measure, existing methods often have quadratic time complexity. We offer the third \(\mathbb {R}\) domain approach. It begins with an insight that sequences in a stationary time series can be treated as sets of independent and identically distributed (iid) points generated from an unknown distribution in \(\mathbb {R}\). This \(\mathbb {R}\) domain treatment enables two new possibilities: (a) The similarity between two sequences can be computed using a distributional measure such as Wasserstein distance (WD), kernel mean embedding or isolation distributional kernel (\(\mathcal {K}_I\)), and (b) these distributional measures become non-sliding-window-based. Together, they offer an alternative that has more effective similarity measurements and runs significantly faster than the point-to-point and sliding-window-based measures. Our empirical evaluation shows that \(\mathcal {K}_I\) is an effective and efficient distributional measure for time series; and \(\mathcal {K}_I\)-based detectors have better detection accuracy than existing detectors in two tasks: (i) anomalous sequence detection in a stationary time series and (ii) anomalous time series detection in a dataset of non-stationary time series. The insight makes underutilized “old things new again” which gives existing distributional measures and anomaly detectors a new life in time series anomaly detection that would otherwise be impossible.












Similar content being viewed by others


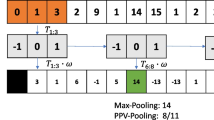
Notes
We use this term to denote either a part of one stationary time series or one time series in a dataset of non-stationary time series, depending on which of the two anomaly detection tasks under investigation.
Detecting anomalous sequences in a non-stationary time series is outside the scope of this paper because the notion of normal sequences could be defined in various ways, depending on the kind of non-stationarity which is often ill-defined. Yet, we show in Sect. 7 that the proposed treatment works for the second anomaly detection task in a dataset of time series, where individual time series can be non-stationary.
We have attempted more complicated measures such as MSM [52] and TWED [31]. They are very time-consuming because they have at least quadratic time complexity, and neither of them (using the Python implementations from sktime [30]) could complete the run within the 2-day time frame for any dataset we have used.
These methods are evaluated for time series classification in their papers, but their representation steps do not need label information and are independent of the downstream task.
The feature map of Gaussian kernel is approximated from the Nyström method [63] in order to accelerate the computation. The sample size of the Nyström method is set to \(\sqrt{nl}\) which is also equal to the number of features. The bandwidth of \(\mathcal {K}_G\) is searched over \(\{10^m\ |\ m=-4,-3,\ldots ,0,1\}\).
The biggest dataset in the UCR archive is not used due to the lack of memories.
References
Bandaragoda, T.R., Ting, K.M., Albrecht, D., Liu, F.T., Zhu, Y., Wells, J.R.: Isolation-based anomaly detection using nearest-neighbor ensembles. Comput. Intell. 34(4), 968–998 (2018)
Beggel, L., Kausler, B.X., Schiegg, M., Pfeiffer, M., Bischl, B.: Time series anomaly detection based on shapelet learning. Comput. Stat. 34(3), 945–976 (2019)
Benkabou, S.E., Benabdeslem, K., Canitia, B.: Unsupervised outlier detection for time series by entropy and dynamic time warping. Knowl. Inf. Syst. 54(2), 463–486 (2018)
Bock, C., Togninalli, M., Ghisu, E., Gumbsch, T., Rieck, B., Borgwardt, K.: A Wasserstein subsequence kernel for time series. In: Proceedings of the International Conference on Data Mining, pp. 964–969 (2019)
Boniol, P., Linardi, M., Roncallo, F., Palpanas, T., Meftah, M., Remy, E.: Unsupervised and scalable subsequence anomaly detection in large data series. VLDB J. 30(6), 909–931 (2021)
Boniol, P., Paparrizos, J., Palpanas, T., Franklin, M.J.: SAND: streaming subsequence anomaly detection. In: Proceedings of the VLDB Endowment, pp. 1717–1729 (2021)
Breunig, M.M., Kriegel, H.P., Ng, R.T., Sander, J.: LOF: Identifying density-based local outliers. In: Proceedings of the ACM SIGMOD International Conference on Management of Data, pp. 93–104 (2000)
Cazelles, E., Robert, A., Tobar, F.: The Wasserstein–Fourier distance for stationary time series. IEEE Trans. Signal Process. 69, 709–721 (2020)
Chan, F.P., Fu, A.C.: Haar wavelets for efficient similarity search of time-series: with and without time warping. IEEE Trans. Knowl. Data Eng. 15(3), 686–705 (2003)
Dau, H.A., Bagnall, A., Kamgar, K., Yeh, C.C.M., Zhu, Y., Gharghabi, S., Ratanamahatana, C.A., Keogh, E.: The UCR time series archive. IEEE/CAA J. Autom. Sinica 6(6), 1293–1305 (2019)
Dempster, A., Schmidt, D.F., Webb, G.I.: Minirocket: A very fast (almost) deterministic transform for time series classification. In: Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pp. 248–257 (2021)
Demšar, J.: Statistical comparisons of classifiers over multiple datasets. J. Mach. Learn. Res. 7, 1–30 (2006)
Dickey, D.A., Fuller, W.A.: Distribution of the estimators for autoregressive time series with a unit root. J. Am. Stat. Assoc. 74(366), 427–431 (1979)
Elliott, G., Rothenberg, T.J., Stock, J.H.: Efficient tests for an autoregressive unit root. Econometrica 64(4), 813–836 (1996)
Faloutsos, C., Ranganathan, M., Manolopoulos, Y.: Fast subsequence matching in time-series databases. ACM SIGMOD Rec. 23(2), 419–429 (1994)
Gharghabi, S., Imani, S., Bagnall, A., Darvishzadeh, A., Keogh, E.: An ultra-fast time series distance measure to allow data mining in more complex real-world deployments. Data Min. Knowl. Disc. 34(4), 1104–1135 (2020)
Gold, O., Sharir, M.: Dynamic time warping and geometric edit distance: breaking the quadratic barrier. ACM Trans. Algorithms 14(4), 1–17 (2018)
Goldberger, A.L., Amaral, L.A., Glass, L., Hausdorff, J.M., Ivanov, P.C., Mark, R.G., Mietus, J.E., Moody, G.B., Peng, C.K., Stanley, H.E.: Physiobank, physiotoolkit, and physionet: components of a new research resource for complex physiologic signals. Circulation 101(23), 215–220 (2000)
Hobijn, B., Franses, P.H., Ooms, M.: Generalizations of the KPSS-test for stationarity. Stat. Neerl. 58(4), 483–502 (2004)
Hyndman, R.J.: Computing and graphing highest density regions. Am. Stat. 50(2), 120–126 (1996)
Hyndman, R.J., Wang, E., Laptev, N.: Large-scale unusual time series detection. In: Proceedings of the International Conference on Data Mining Workshop, pp. 1616–1619 (2015)
Itakura, F.: Analysis synthesis telephony based on the maximum likelihood method. In: Proceedings of the 6th International Congress on Acoustics, pp. 280–292 (1968)
Jones, M., Nikovski, D., Imamura, M., Hirata, T.: Exemplar learning for extremely efficient anomaly detection in real-valued time series. Data Min. Knowl. Disc. 30(6), 1427–1454 (2016)
Kalpakis, K., Gada, D., Puttagunta, V.: Distance measures for effective clustering of arima time-series. In: Proceedings of the IEEE International Conference on Data Mining, pp. 273–280 (2001)
Keogh, E., Lin, J., Fu, A.: Hot sax: efficiently finding the most unusual time series subsequence. In: Proceedings of the IEEE International Conference on Data Mining, pp. 226–233 (2005)
Keogh, E., Ratanamahatana, C.A.: Exact indexing of dynamic time warping. Knowl. Inf. Syst. 7(3), 358–386 (2005)
Klein, J.L.: Statistical Visions in Time: A History of Time Series Analysis, pp. 1662–1938. Cambridge University Press, Cambridge (1997)
Knox, E.M., Ng, R.T.: Algorithms for mining distancebased outliers in large datasets. In: Proceedings of the 24th International Conference on Very Large Data Bases, pp. 392–403 (1998)
Liu, F.T., Ting, K.M., Zhou, Z.H.: Isolation forest. In: Proceedings of the International Conference on Data Mining, pp. 413–422 (2008)
Löning, M., Bagnall, A., Ganesh, S., Kazakov, V., Lines, J., Király, F.J.: sktime: A unified interface for machine learning with time series. arXiv:1909.07872 (2019)
Marteau, P.F.: Time warp edit distance with stiffness adjustment for time series matching. IEEE Trans. Pattern Anal. Mach. Intell. 31(2), 306–318 (2008)
Moody, G.B., Mark, R.G.: The impact of the MIT-BIH arrhythmia database. IEEE Eng. Med. Biol. Mag. 20(3), 45–50 (2001)
Muandet, K., Fukumizu, K., Sriperumbudur, B., Schölkopf, B., et al.: Kernel mean embedding of distributions: a review and beyond. Found. Trends® Mach. Learn. 10(1–2), 1–141 (2017)
Muandet, K., Schölkopf, B.: One-class support measure machines for group anomaly detection. In: Proceedings of the 29th Conference on Uncertainty in Artificial Intelligence, pp. 449–458 (2013)
Paparrizos, J., Boniol, P., Palpanas, T., Tsay, R.S., Elmore, A., Franklin, M.J.: Volume under the surface: a new accuracy evaluation measure for time-series anomaly detection. In: Proceedings of the VLDB Endowment, pp. 2774–2787 (2022)
Paparrizos, J., Franklin, M.J.: Grail: efficient time-series representation learning. In: Proceedings of the VLDB Endowment, pp. 1762–1777 (2019)
Paparrizos, J., Gravano, L.: k-Shape: Efficient and accurate clustering of time series. In: Proceedings of the ACM SIGMOD International Conference on Management of Data, pp. 1855–1870 (2015)
Paparrizos, J., Kang, Y., Boniol, P., Tsay, R.S., Palpanas, T., Franklin, M.J.: TSB-UAD: an end-to-end benchmark suite for univariate time-series anomaly detection. In: Proceedings of the VLDB Endowment, pp. 1697–1711 (2022)
Paparrizos, J., Liu, C., Elmore, A.J., Franklin, M.J.: Debunking four long-standing misconceptions of time-series distance measures. In: Proceedings of the ACM SIGMOD International Conference on Management of Data, pp. 1887–1905 (2020)
Popivanov, I., Miller, R.J.: Similarity search over time-series data using wavelets. In: Proceedings of the International Conference on Data Engineering, pp. 212–221 (2002)
Qin, X., Ting, K.M., Zhu, Y., Lee, V.C.: Nearest-neighbour-induced isolation similarity and its impact on density-based clustering. In: Proceedings of the AAAI Conference on Artificial Intelligence, pp. 4755–4762 (2019)
Qiu, C., Pfrommer, T., Kloft, M., Mandt, S., Rudolph, M.: Neural transformation learning for deep anomaly detection beyond images. In: Proceedings of the International Conference on Machine Learning, pp. 8703–8714 (2021)
RueshendorffS, L.: Wasserstein metric. In: Encyclopedia of Mathematics (2002)
Sakoe, H.: Dynamic-programming approach to continuous speech recognition. In: Proceedings of the International Congress of Acoustics (1971)
Sakoe, H., Chiba, S.: Dynamic programming algorithm optimization for spoken word recognition. IEEE Trans. Acoust. Speech Signal Process. 26(1), 43–49 (1978)
Schmidl, S., Wenig, P., Papenbrock, T.: Anomaly detection in time series: a comprehensive evaluation. In: Proceedings of the VLDB Endowment, pp. 1779–1797 (2022)
Schölkopf, B., Platt, J.C., Shawe-Taylor, J., Smola, A.J., Williamson, R.C.: Estimating the support of a high-dimensional distribution. Neural Comput. 13(7), 1443–1471 (2001)
Senin, P., Lin, J., Wang, X., Oates, T., Gandhi, S., Boedihardjo, A.P., Chen, C., Frankenstein, S.: Time series anomaly discovery with grammar-based compression. In: Proceedings of the 18th International Conference on Extending Database Technology, pp. 481–492 (2015)
Shen, Y., Chen, Y., Keogh, E., Jin, H.: Accelerating time series searching with large uniform scaling. In: Proceedings of the SIAM International Conference on Data Mining, pp. 234–242 (2018)
Shumway, R.H., Stoffer, D.S.: Time Series Analysis and Its Applications: With R Examples. Springer, Berlin (2017)
Smola, A., Gretton, A., Song, L., Schölkopf, B.: A Hilbert space embedding for distributions. In: Proceedings of the International Conference on Algorithmic Learning Theory, pp. 13–31 (2007)
Stefan, A., Athitsos, V., Das, G.: The move-split-merge metric for time series. IEEE Trans. Knowl. Data Eng. 25(6), 1425–1438 (2012)
Tan, C.W., Petitjean, F., Webb, G.I.: Elastic bands across the path: A new framework and method to lower bound DTW. In: Proceedings of the SIAM International Conference on Data Mining, pp. 522–530 (2019)
Tavenard, R., Faouzi, J., Vandewiele, G., Divo, F., Androz, G., Holtz, C., Payne, M., Yurchak, R., Rußwurm, M., Kolar, K., et al.: Tslearn, a machine learning toolkit for time series data. J. Mach. Learn. Res. 21(1), 4686–4691 (2020)
Tax, D.M., Duin, R.P.: Support vector data description. Mach. Learn. 54(1), 45–66 (2004)
Ting, K.M., Liu, Z., Zhang, H., Zhu, Y.: A new distributional treatment for time series and an anomaly detection investigation. In: Proceedings of the VLDB Endowment, pp. 2321–2333 (2022)
Ting, K.M., Wells, J.R., Washio, T.: Isolation kernel: the X factor in efficient and effective large scale online kernel learning. Data Min. Knowl. Disc. 35(6), 2282–2312 (2021)
Ting, K.M., Xu, B.C., Washio, T., Zhou, Z.H.: Isolation distributional kernel: a new tool for kernel based anomaly detection. In: Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 198–206 (2020)
Ting, K.M., Xu, B.C., Washio, T., Zhou, Z.H.: Isolation distributional kernel: a new tool for point and group anomaly detections. IEEE Trans. Knowl. Data Eng. 35(03), 2697–2710 (2023)
Ting, K.M., Zhu, Y., Zhou, Z.H.: Isolation kernel and its effect on SVM. In: Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 2329–2337 (2018)
Togninalli, M., Ghisu, E., Llinares-López, F., Rieck, B., Borgwardt, K.: Wasserstein Weisfeiler-Lehman graph kernels. In: Proceedings of the Conference on Neural Information Processing Systems, pp. 6436–6446 (2019)
Wu, R., Keogh, E.J.: Current time series anomaly detection benchmarks are flawed and are creating the illusion of progress. IEEE Trans. Knowl. Data Eng. 35(03), 2421–2429 (2023)
Yang, T., Li, Y.f., Mahdavi, M., Jin, R., Zhou, Z.H.: Nyström method vs random Fourier features: a theoretical and empirical comparison. In: Proceedings of Conference on Neural Information Processing Systems, pp. 476–484 (2012)
Yeh, C.C.M., Zhu, Y., Ulanova, L., Begum, N., Ding, Y., Dau, H.A., Silva, D.F., Mueen, A., Keogh, E.: Matrix profile I: all pairs similarity joins for time series: a unifying view that includes motifs, discords and shapelets. In: Proceedings of the International Conference on Data Mining, pp. 1317–1322 (2016)
Yue, Z., Wang, Y., Duan, J., Yang, T., Huang, C., Tong, Y., Xu, B.: Ts2vec: Towards universal representation of time series. In: Proceedings of the AAAI Conference on Artificial Intelligence, pp. 8980–8987 (2022)
Zhu, Y., Zimmerman, Z., Senobari, N.S., Yeh, C.C.M., Funning, G., Mueen, A., Brisk, P., Keogh, E.: Matrix profile II: Exploiting a novel algorithm and gpus to break the one hundred million barrier for time series motifs and joins. In: Proceedings of the International Conference on Data Mining, pp. 739–748 (2016)
Acknowledgements
This project is supported by National Natural Science Foundation of China (Grant No. 62076120). The insight and the distributional treatment on the first anomaly detection task (i.e., anomalous sequence detection in one stationary time series) were presented in International Conference on Very Large Databases 2022 [56].
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
The machine used in the experiments has one Intel Core i7-12700K CPU with 128 GB memory and one NVIDIA GeForce RTX 3060 GPU with 12 GB memory.
1.1 Experiment settings for anomalous sequence detection
Sequences in each time series are preprocessed with z-score normalization. All final scores output by detectors are normalized in [0, 1]. For detectors that rely on randomization, we report the average result of 10 trials on each time series.
[Datasets] Synthetic datasets noisy_sine and ARMA are originated from a previous work [23]. Real-world datasets include MIT-BIH Supraventricular Arrhythmia Database (MBA) [18, 32], and other datasets from various domains have been studied in earlier works [23, 25, 48].
Some datasets have two versions, e.g., ann_gun and stdb_308; and each version uses one of the two variables. When either version produces similar AUC for most detectors, we have chosen to use one only. Some datasets are trivial, e.g., chfdb_chf0175 and qtdbsel102; and all detectors have the perfect result (\(\hbox {AUC}=1\)), so we do not show them in Table 7.
We labeled anomalous periods for each time series following the previous work [23, 25, 48]. Details are given in Table 17. Positions of anomalies in MBA datasets can be seen in folder “MBA_Annotation."
The period of some datasets varies slightly at different time steps in the series; but it has no effect on the detection accuracy of all algorithms. Our algorithm works well when the sequence length is set to be roughly the length of the period.
Brief descriptions of some datasets are given as follows.
dutch_pwrdemand: There are a total of 6 anomalous weeks. Some papers [5, 23, 25] use this dataset with fewer anomalies because they treat continuous anomalous weeks as one anomaly.
ann_gun: It has only one anomalous period when it was first used in Keogh’s work [25], as shown in Fig. 11a. Other anomalous periods in this dataset were later identified [5], and they are shown in Fig. 11b.
Patient_respiration: Like the previous work [23], we use the subset that begins at 15,500 and ends at 22,000 from the nprs44 dataset [25]. There are one apparent anomaly and one subtle anomaly in this dataset as shown in Fig. 12a.
TEK: Following the previous work [23], we also concatenate dataset TEK14, TEK16 and TEK17 as TEK of length 15,000. In Keogh’s work [25], a total of 4 anomalies are marked. But TEK14 has 2 anomalous snippets belonging to the same period as shown in Fig. 12b. Since we regard each anomaly as an anomalous sequence of one complete period, it is treated as one anomalous periodic sequence of length 1000. So there are a total of 3 anomalous sequences in our annotations of this dataset.
MBA803, MBA805, MBA806, MBA820 and MBA14046: These datasets are subsets of the full MBA dataset, as used in the previous work [5].


Anomalies in a Patient_respiration; b a period of TEK14. The diagrams are extracted from [25]
[Algorithms] The STOMP [66] implementation of MP is used; NormA is from http://helios.mi.parisdescartes.fr/~themisp/norma/;
\(\mathcal {K}_I\)-based detectors are our implementations based on [59]; and WFD is from https://github.com/GAMES-UChile/Wasserstein-Fourier. Others are from scikit-learn.org. All are in Python.
The parameter search ranges of all algorithms used are given in Table 18.
As for the 1Line method, we use one of the following five types of basic vectorized primitive functions in Matlab as an anomaly score for each sliding window of size \(\omega \):
-
I.
±diff(X): the difference between the current point and the previous point. Here \(\omega =1\).
-
II.
±movmax(X, \({{\varvec{\omega }}}\))
-
III.
±movmin(X, \({{\varvec{\omega }}}\))
-
IV.
±movmean(X, \({{\varvec{\omega }}}\))
-
V.
±movstd(X, \({{\varvec{\omega }}}\))
where X is the time series; and the maximum, minimum, mean or standard deviation is computed for each window of \({{\varvec{\omega }}}\) points.
We run these 5 one-liners on each dataset and report the median AUC (out of the five values) in Table 7. Low median values indicate that the datasets are hard to detect using the 1Line method; otherwise, the datasets have anomalies that can be easily detected.
[Measures] The detection accuracy of an anomaly detector is measured in terms of AUC (area under ROC curve). As all the anomaly detectors are unsupervised learners, all models are trained with the given datasets with no labels. Only after the trained models have made predictions, the ground truth labels are used to compute the AUC for each dataset.
Given a periodic time series X of length n and period length m, a sequence \(X_i\) of X is a subset of contiguous values of length m, for \(i=1,\ldots ,s\), where \(s= \lfloor \hbox {length}(X)/m\rfloor \). A distribution-based (non-sliding-window) algorithm outputs a score of each periodic sequence \(X_{i}\). Then AUC can be calculated based on scores \(\alpha _i\) for \(X_{i}\ \forall i=1,\ldots ,s\).
An anomaly detector using the sliding-window size \(\omega \) produces a total of \(\hbox {length}(X)-\omega +1\) sequences from X. When calculating AUC, scores of the sliding sequences are transformed into periodic sequence scores as follows: Let \(S_h\) be the anomaly score of sequence \(X_h\), where \(1 \le h \le (\hbox {length}(X)-\omega +1)\). The final score corresponds to a periodic sequence \(X_i\) is the maximum score of \(S_h\ \forall h\) such that at least half of \(X_{h}\) is included in \(X_{i}\).
1.2 Experiment settings for anomalous time series detection
[Datasets] Out of the initial 109 time series datasets (used in [11]) in UCR time series classification archive [10], we remove the datasets having the length of time series less than 200 and choose the top 20 datasets with the largest number of time series for our evaluation. (The datasets MixedShapesSmallTrain and FreezerSmallTrain are not included because they are the subsets of the two datasets chosen, namely, MixedShapesRegularTrain and FreezerRegularTrain, respectively).
New labeled datasets (normal vs. anomalous) are created as follows.
Each dataset in the archive contains a training set and a testing set. For each of the combined training-and-testing time series dataset having k classes, we take \(\lfloor k/2 \rfloor \) largest classes and treat them to be the normality. Then, we sample 2% of time series from the other classes with an initial seed number 10 and treat them as anomalous time series.
The characteristics of the generated datasets are shown in Table 19. Note that the previous work [2, 3] chose only 1 class as the normality which makes the task trivial. The way we produce datasets allowing several classes as the normality makes this task more interesting and challenging.
[Algorithms] \(\mathcal {K}_I\)-based detectors are our implementations based on [59]. Mini-Rocket is from https://github.com/angus924/minirocket. TS2Vec is from https://github.com/yuezhihan/ts2vec. WTK is from https://github.com/BorgwardtLab/WTK. NeuTraL is from https://github.com/boschresearch/NeuTraL-AD. All the above are in Python. DOTS is a Scala implementation from https://github.com/B-Seif/anomaly-detection-time-series; Hyndman is a R implementation from https://github.com/robjhyndman/anomalous-acm. DTW and SBD are from the Python package tslearn [54].
The warping window of DTW is set to 5% of the length of the time series of each dataset, because the detection accuracy becomes worse when we attempt other window sizes or no windows.
For TS2Vec, we use its experimental settings of classification task because we require the instance-level representations.
For Mini-Rocket and NeuTraL, we use their default parameter configurations suggested in their papers.
The parameter search ranges of all the algorithms that need parameter tuning are given in Table 20.
As for the 1Line method, we use one of the following five types of basic vectorized primitive functions in Matlab as an anomaly score for each time series \(T_j, j=1,\ldots ,n\), where n is the number of time series in the dataset.
-
I.
±max(\(T_j\)): the maximum value of time series
-
II.
±min(\(T_j\)): the minimum value of time series
-
III.
±mean(\(T_j\)): the mean value of time series
-
IV.
±std(\(T_j\)): the standard deviation of time series
-
V.
±max(diff(\(T_j\))): the maximum of the difference between the current point and the previous point
We run these five 1-Line methods on each dataset and report the maximum AUC in Table 10. Low maximum values indicate that the datasets are hard to detect using any of the 1Line methods; otherwise, the datasets have anomalies which can be easily detected.
1.3 Additional experimental results for anomalous time series detection are given in Tables 21 and 22.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Ting, K.M., Liu, Z., Gong, L. et al. A new distributional treatment for time series anomaly detection. The VLDB Journal 33, 753–780 (2024). https://doi.org/10.1007/s00778-023-00832-x
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00778-023-00832-x