
Abstract
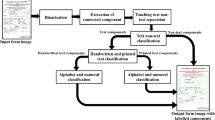
Business forms with the dense text boxes have a complicated layout, diverse content, and low quality. It is a challenging task for the existing methods of form understanding to recognize form structure and to meet the requirements in real-time application scenarios. In this paper, we propose a novel multi-task lightweight block pyramid network for form segmentation and classification, named BPFormNet. According to the characteristics of the form images, we exploit the multi-scale pyramidal feature hierarchy of CNN (Convolutional Neural Network) to construct a multi-level, multi-scale block pyramid, which consists of the low-level, mid-level, and high-level convolutional blocks designed for the corresponding feature layer, and builds the semantic feature maps of multi-scale effective fusion at every level. BPFromNet leverages the interdependence between the twin task of segmentation task of form frames and classification task to improve the performance of the classification under the training strategy of small samples. Furthermore, BPFormNet performs comprehensive lightweighting from three levels: multi-level, multi-scale convolutional block combination, multi-size kernel combination, and disassembly of kernels. Experimental results on the collected image dataset of Chinese insurance forms (CIF) show that BPFormNet with the block pyramid has a strong capability of form feature representation. Comparing with some state-of-the-art (SOTA) lightweight models and their combinations, BPFormNet achieves a better performance in both segmentation and classification task than the models of single block, significantly reduces the model complexity while maintaining the model accuracy, and provides the real-time, high-quality results of form structure recognition for the downstream task of text recognition and information extraction.
















Similar content being viewed by others


Data availability
The datasets generated during and analyzed during the current study are available in the [GitHub] repository, [https://github.com/HansonLinn/Insurance-Forms-Understanding-Framework/tree/main/Form%20datasets].
References
Adam P., Abhishek C., Sangpil K., Eugenio C.: ENet: a deep neural network architecture for real-time semantic segmentation. arXiv:1606.02147 (2016)
Andrew H., Ruoming P., Hartwig A., Quoc V. L., Mark S., Bo C., Weijun W., Liang-Chieh C., Mingxing T., Grace C., Vijay V., Yukun Z.: Searching for MobileNetV3. IEEE/CVF International Conference on Computer Vision (ICCV), pp. 1314–1324 (2019)
Brian L. D., Bryan S. M., Scott C., Brian L. P., Chris T.: Deep visual template-free form parsing. International Conference on Document Analysis and Recognition (ICDAR), pp. 134–141 (2019)
Cesarini F., Marinai S, Sarti L., Soda G.: Trainable table location in document images. International Conference on Pattern Recognition, pp. 236–240 (2002)
Changqian Y., Jingbo W., Chao P., Changxin G., Gang Y., Nong S.: BiSeNet: Bilateral segmentation network for real-time semanticsegmentation. European Conference of Computer Vision (ECCV), pp. 334–349 (2018)
Chen, J., Chen, Y.S., Li, W.H., et al.: Image co-segmentation based on pyramid features cross-correlation network. Sci China Inf Sci 66(1), 119101 (2023)
Christian S., Vincent V., Sergey I., Jonathon S., Zbigniew W.: Rethinking the inception architecture for computer vision. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 2818–2826 (2016)
Dang T., Hoang D., Tran Q., et al.: End-to-End Hierarchical Relation Extraction for Generic Form Understanding. 2020 25th International Conference on Pattern Recognition (ICPR). pp.5238–5245 (2021)
Devashish P., Ayan G., Kshitij K., et al.: CascadeTabNet: An approach for end to end table detection and structure recognition from image-based documents. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, pp. 572–573 (2020)
Dominika, T., Pawel, S., Mateusz, F., Piotr, J.D., Lukasz, B.: CERMINE: automatic extraction of structured metadata from scientific literature. Int. J. Document Anal. Recognit. 18(4), 317–335 (2015)
Eduardo, R., José, M.Á., Luis, M.B., Roberto, A.: ERFNet: Efficient residual factorized convnet for real-time semantic segmentation. IEEE Trans. Intell. Transp. Syst. 19(1), 263–272 (2018)
Gilani A., Qasim S R., Malik I., Shafait F.: Table detection using deep learning. International Conference on Document Analysis and Recognition (ICDAR) pp. 771–776 (2017)
Hanchao L., Pengfei X., Haoqiang F., Jian S. DFANet: Deep Feature Aggregation for Real-Time Semantic Segmentation. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 9522–9531 (2019)
Hao L., Gao L., Yi X., Tang Z.: A table detection method for pdf documents based on convolutional neural networks. IAPR Workshop on Document Analysis Systems, pp. 287–292 (2016)
He K., Zhang X., Ren S., Sun J.: Deep residual learning for image recognition. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 770–778 (2016)
Jaume G., Ekenel H K., Thiran J P.:FUNSD: A dataset for form understanding in noisy scanned documents. International Conference on Document Analysis and Recognition Workshops (ICDARW), pp. 1–6 (2019)
Johan, F., Murat, S., Burak, K., Shahzad, K.: TableDet: an end-to-end deep learning approach for table detection and table image classification in data sheet images. Neurocomputing 468, 317–334 (2022)
Karen S., Andrew Z.: Very deep convolutional networks for large-scale image recognition. In: International Conference on Learning Representations (ICLR) (2015)
Kasar T., Barlas P., Adam S., Chatelain C., Paquet T.: Learning to detect tables in scanned document images using line information. In: 12th International Conference on Document Analysis and Recognition (ICDAR), pp. 1185–1189 (2013)
Lecun, Y., Bottou, L., Bengio, Y., Patrick, H.: Gradient-based learning applied to document recognition. Proc. IEEE 86(11), 2278–2324 (1998)
Li C., Bi B., Yan M., Wang W., Huang S., Huang F., Si L.: StructuralLM: Structural pre-training for form understanding. In: Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, 2021: 6309–6318 (2021)
Li M., Cui L., Huang S., Wei F., Zhou M., Li Z.: TableBank: table benchmark for image-based table detection and recognition. In: 12th Language Resources and Evaluation Conference, pp. 1918–1925 (2019)
Li M., Xu Y., Cui L., Huang S., Wei F., Li Z., Zhou M.:. DocBank: A benchmark dataset for document layout analysis. In: International Conference on Computational Linguistics, pp. 949–960 (2020)
Liang Q., Zaisheng L., Zhanzhan C., Peng Z., Shiliang P., Yi N., Wenqi R., Wenming T., Fei W.: LGPMA: Complicated table structure recognition with local and global pyramid mask alignment. In: International Conference on Document Analysis and Recognition (ICDAR), pp. 99–114 (2021)
Liu, L., Wang, Z., Qiu, T., Chen, Q., Suen, C.Y.: Document image classification: progress over two decades. Neurocomputing 453, 223–240 (2021)
Long J., Shelhamer E., Darrell T.: Fully convolutional networks for semantic segmentation. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 3431–3440 (2015)
Mark S., Andrew G H., Menglong Z., Andrey Z., Liang-Chieh C.: Mobilenetv2: inverted residuals and linear bottlenecks. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 4510–4520 (2018)
Matthew D Z., Rob F.: Visualizing and understanding convolutional networks. In: European Conference of Computer Vision (ECCV), pp. 818–833 (2014)
Mohammad H., Hamed M.: Document image classification using SqueezeNet convolutional neural network. In: 5th Iranian Conference on Signal Processing and Intelligent Systems (ICSPIS), pp. 1–4 (2019)
Nikola, M., Cassie, G., Robert, H., Goran, N.: A framework for information extraction from tables in biomedical literature. Int. J. Doc. Anal. Recognit. 22(1), 55–78 (2019)
Nishant S., Alexandre M., Malcolm G., Adrian L.: A survey of deep learning approaches for OCR and document understanding, arXiv:2011.13534 (2021)
Olaf R., Philipp F., Thomas B.: U-Net: Convolutional networks for biomedical image segmentation. In: Medical image computing and computer-assisted intervention (MICCAI), pp. 234–241 (2015)
Paliwal SS., Vishwanath D., Rahul R., Sharma M., Vig L.: TableNet: Deep learning model for end-to-end table detection and tabular data extraction from scanned document images. In: International conference on document analysis and recognition (ICDAR), pp. 128–133 (2019)
Rudra P. K. P., Stephan L., Roberto C.: Fast-SCNN: fast semantic segmentation network. In: British machine vision conference, pp. 289 (2019)
Sanghyeon A., Minjun L., Sanglee P., Heerin Y., Jungmin S.: An ensemble of simple convolutional neural network models for MNIST digit recognition. arXiv:2008.10400 (2020)
Schreiber S., Agne S., Wolf I., Dengel A., Ahmed S.: DeepDeSRT: deep learning for detection and structure recognition of tables in document images. In: International conference on document analysis and recognition (ICDAR), pp. 1162–1167 (2017)
Siddiqui SA., Pervaiz IK., Andreas D., Sheraz A.: Rethinking semantic segmentation for table structure recognition in forms. In: International conference on document analysis and recognition (ICDAR), pp. 1397–1402 (2019)
Taha E., Hossam E A E M., Hazem M A.: LiteSeg: a novel lightweight convnet for semantic segmentation. In: Digital image computing: techniques and applications, pp. 1–7 (2019)
Thomas K., Andreas D.: The T-Recs table recognition and analysis system. In: Document analysis systems, pp. 255–269 (1998)
Tsung-Yi, L., Michael, M., Serge, J. B., James, H., Pietro, P., Deva, R., Piotr, D.C., Lawrence Z.: Microsoft COCO: common objects in context. In: European conference on computer vision (ECCV) pp. 740–755 (2014)
Tsung-Yi, L., Piotr, D., Ross, B.G., Kaiming, H., Bharath, H., Serge, J.B.: Feature pyramid networks for object detection. In: IEEE/CVF conference on computer vision and pattern recognition (CVPR), pp. 936–944 (2017)
Xiaohan, D., Xiangyu, Z., Ningning, M., Jungong, H., Guiguang, D., Jian, S.: RepVGG: making VGG-style convnets great again. In: IEEE Conference on Computer Vision and Pattern Recognition, pp. 13733–13742 (2021)
Xu, Y., Li, M., Cui, L., Huang, S., Wei, F., Zhou, M.: LayoutLM: pre-training of text and layout for document image understanding. In: Conference on Knowledge Discovery and Data Mining (KDD), pp. 1192–1200 (2020)
Xu, Y., Lv, T., Cui, L., Wang, G., Lu, Y., Florêncio, D., Zhang, C., Wei, F.:LayoutXLM: multimodal pre-training for multilingual visually-rich document understanding. arXiv preprint arXiv: 2104.08836 (2021)
Yang, X., Yiheng, X., Tengchao, L., Lei, C., Furu, W., Guoxin, W., Yijuan, L., Dinei, A. F. F., Cha, Z., Wanxiang, C., Min, Z., Lidong, Z.: LayoutLMv2: multi-modal pre-training for visually-rich document understanding. In: The Joint Conference of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (ACL/IJCNLP 2021), pp. 2579–2591 (2021)
Zhang X., Zhou X., Lin M., Sun J.: ShuffleNet: An extremely efficient convolutional neural network for mobile devices. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 6848–6856 (2018)
Acknowledgements
This work was supported in part by Jiangsu Provincial Department of Science and Technology of China (Grant No. BE2020099).
Funding
This work was supported in part by Jiangsu Provincial Department of Science and Technology of China (Grant No. BE2020099).
Author information
Authors and Affiliations
Contributions
HL was contributed to conceptualization, methodology, software, investigation, formal analysis, funding acquisition, validation, writing—original draft; YZ was contributed to conceptualization, resources, supervision, writing—review and editing; CW was contributed to data curation, visualization, writing—editing. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Conflict of interests
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Lin, H., Zhan, Y. & Wu, C. BPFormNet: a lightweight block pyramid network for form segmentation and classification. IJDAR 27, 1–17 (2024). https://doi.org/10.1007/s10032-023-00440-z
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10032-023-00440-z