
Abstract
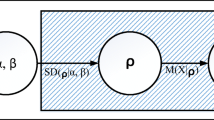
The blending of generative and discriminative approaches has been prevailed by exploring and adopting distinct characteristic of each approach toward constructing a complementar system combining the best of both. The majority of current research in classification and categorization does not completely address the true structure and nature of data for particular application at hand. In contrast to most previous research, our proposed work focuses on the modeling and classification of spherical data that are naturally generated in many data mining and knowledge discovery applications such as text classification, visual scenes categorization and gene expression analysis. This paper investigates a generative mixture model to cluster spherical data based on Langevin distribution. In particular, we formulate a unified probabilistic framework, where we build probabilistic kernels based on Fisher score and information divergences from mixture of Langevin distributions for Support Vector Machine. We demonstrate the effectiveness and the merits of the proposed learning framework through synthetic data and challenging applications involving spam filtering using both textual and visual email contents.










Similar content being viewed by others


Notes
In particular, the authors in [10] recommended strongly the normalization of data in feature space when considering SVM and have shown that normalization leads to considerably superior generalization performance.
More details and thorough discussions about the statistics of spherical data in particular and directional data in general can be found in [19].
Also known as the circular normal distribution [22].
Other approaches are possible also. For instance, in [35], the authors have used mixture of von Mises distributions learned using maximum likelihood for parameters estimation and bootstrap likelihood ratio approach to assess the optimal number of components and applied to study the problem of sudden infant death.
Using the superscript * to denote the optimal values of the cost function.
This localized data presentation alleviates many problems associated with representing data in complex applications (e.g. video categorization) such as data sparsity and curse of dimensionality.
(open source by Google) http://code.google.com/p/tesseract-ocr/.
In [64] the threshold (t) has been set to 0.5, 0.9, 0.999, respectively, where \(t= \frac{\lambda}{1 + \lambda}. \)
Available at http://www.princeton.edu/cass/spam/spam_bench/.
References
Podolak IT, Roman A (2011) Cores: fusion of supervised and unsupervised training methods for a multi-class classification problem. Pattern Anal Appl 14(4):395–413
Yang B, Chen S, Wu X (2011) A structurally motivated framework for discriminant analysis. Pattern Anal Appl 14(4):349–367
Vapnik VN (2000) The nature of statistical learning theory, 2nd edn. Springer, Berlin
Bishop CM (2006) Pattern Recognition and Machine Learning, 1st edn. Springer, Berlin
Jebara T, Kondor R, Howard A (2004) Probability product kernels. J Mach Learn Res 5:819–844
Ng AY, Jordan MI (2001) On discriminative vs generative classifiers: a comparison of logistic regression and naive Bayes. In: Proceedings of 4th conference on advances in neural information processing systems. MIT Press, Cambridge, pp 841–848
Raina R, Shen Y, Ng AY, McCallum A (2003) Classification with hybrid generative/discriminative models. In: Proceedings of 16th conference on advances in neural information processing systems. MIT Press
Bosch A, Zisserman A, Noz XM (2008) Scene classification using a hybrid generative/discriminative approach. IEEE Trans Pattern Anal Mach Intell 30(4):712–727
Prevost L, Oudot L, Moises A, Michel-Sendis C, Milgram M (2005) Hybrid generative/discriminative classifier for unconstrained character recognition. Pattern Recogn Lett 26(12):1840–1848
Herbrich R, Graepel T (2000) A PAC-Bayesian margin bound for linear classifiers: why SVMs work. In: Proceedings of advances in neural information processing systems (NIPS). pp 224–230
Wittel GL, Wu SF (2004) On attacking statistical spam filters. In: Proceedings of the first conference on email and anti-spam (CEAS). California, USA
Amayri O, Bouguila N (2010) A study of spam filtering using support vector machines. Artif Intell Rev 34(1):73–108
Graf AB, Smola AJ, Borer S (2003) Classification in a normalized feature space using support vector machines. IEEE Trans Neural Netw 14(3):597–605
Wallace CS (2005) Statistical and inductive inference by minimum message length. Springer, Berlin
Wallace CS, Dowe DL (2000) MML clustering of multi-state, Poisson, von Mises circular and Gaussian distributions. Stat Comput 10(1):73–83
Dowe D, Oliver J, Wallace C (1996) MML estimation of the parameters of the spherical fisher distribution. In: Arikawa S, Sharma A (eds) Proceedings of the conference on algorithmic learning theory (ALT). Lecture Notes in computer science, vol 1160. Springer, Berlin, pp 213–227
Leopold E, Kindermann J (2002) Text categorization with support vector machines. How to represent texts in input space? Mach Learn 46(13):423–444
Joachims T (1998) Text categorization with support vector machines: Learning with many relevant features. In: Nédellec C, Rouveirol C (eds) Proceedings of of ECML-98, 10th European conference on machine learning, number 1398. Chemnitz, DE. Springer, Berlin, pp 137–142
Mardia KV (1975) Statistics of directional data (with discussions). J R Stat Soc Series B (Methodol) 37(3):349–393
Mardia KV (1972) Statistics of directional data. Academic Press, Waltham
Watson GS (1983) Statistics on spheres. Wiley, New York
Fisher NI (1993) Statistical analysis of circular data, 1st edn. Cambridge University Press, Cambridge
Fisher NI, Embleton BJJ, Lewis T (1993) Statistical analysis of spherical data. Cambridge University Press, Cambridge
McGraw T, Vemuri BC, Yezierski B, Mareci T (2006) von Mises–Fisher mixture model of the diffusion ODF. In: Proceedings of 3rd IEEE international symposium on biomedical imaging: from nano to macro, Arlington, VA, pp 65–68
Tang H, Chu SM, Huang TS (2009) Generative model-based speaker clustering via mixture of von Mises–Fisher distributions. In: Proceedings of IEEE international conference on acoustics, speech, and signal processing, Los Alamitos, CA, USA. IEEE Computer Society, pp 4101–4104
Banerjee A, Dhillon IS, Ghosh J, Sra S (2005) Clustering on the unit hypersphere using von Mises–Fisher distributions. J Mach Learn Res 6:1345–1382
Mardia KV, Zemroch PJ (1975) Algorithm as 81: circular statistics. Appl Stat 24(1):147–150
Mardia KV, Zemroch PJ (1975) Algorithm as 80: spherical statistics. Appl Stat 24(1):144–146
McLachlan GJ, Peel D (2000) Finite mixture models. Wiley, New York
Dhillon IS, Modha DS (2001) Concept decompositions for large sparse text data using clustering. Mach Learn 42(1–2):143–175
Dhillon I, Fan J, Guan Y (2001) Efficient Clustering of very large document collections. Kluwer, New York
Akaike H (1974) A new look at the statistical model identification. IEEE Trans Automatic Control 19(6):716–723
Schwarz G (1978) Estimating dimension of a model. Ann Stat 6:461–464
Rissanen J (1987) Modeling by shortest data description. Automatica 14:465–471
Mooney JA, Helms PJ, Jolliffe IT (2003) Fitting mixtures of von Mises distributions: a case study involving sudden infant death syndrome. Comput Stat Data Anal 41:505–513
Bouguila N, Ziou D (2006) Unsupervised selection of a finite Dirichlet mixture model: an MML-based approach. IEEE Trans Knowl Data Eng 18(8):993–1009
Bouguila N, Ziou D (2007) High-dimensional unsupervised selection and estimation of a finite generalized Dirichlet mixture model based on minimum message length. IEEE Trans Pattern Anal Mach Intell 29(10):1716–1731
Mardia KV (1975) Distribution theory for the von Mises–Fisher distribution and its application. In: Kotz S, Patial GP, Ord JK (eds) Statistical distributions for scientific work, vol 1. pp 113–130
Agarwal A, Daumé H (2011) Generative kernels for exponential families. In: Proc. of the international conference on artificial intelligence and statistics (AISTAT)
Jaakkola TS, Haussler D (1998) Exploiting generative models in discriminative classifiers. In: Proceedings of advances in neural information systems (NIPS). MIT Press, Cambridge, pp 487–493
Chan AB, Vasconcelos N, Moreno PJ (2004) A family of probabilistic kernels based on information divergence. TechnicalReport SVCL-TR2004/01, University of California, SanDiego
Bouguila N (2012) Hybrid generative/discriminative approaches for proportional data modeling and classification. IEEE Trans Knowl Data Eng 24:2184–2202
Kullback S (1959) Information theory and statistics, 1st edn. Wiley, New York
Moreno PJ, Ho PP, Vasconcelos N (2003) A Kullback–Leibler divergence based kernel for SVM classification in multimedia applications. In: Proceedings of advances in neural information processing systems (NIPS). MIT Press, Cambridge
Hershey JR, Olsen PA (2007) Approximating the Kullback Leibler divergence between gaussian mixture models. In: Proceedings of IEEE international conference on acoustics, speech and signal processing (ICASSP), vol 4. pp 317–320
Lin J (1991) Divergence measure based on Shannon entropy. IEEE Trans Inf Theory 37(14):145–151
Rényi A (1960) On measures of entropy and information. In: Proceedings of Berkeley symposium mathematical statistics and probability. pp 547–561
Ulrich G (1984) Computer generation of distributions on the m-sphere. J Roy Stat Soc 33(2):158–163
Wood ATA (1994) Simulation of the von Mises Fisher distribution. Commun Stat Simul Comput 23(1):157–164
Blanzieri E, Bryl A (2008) A survey of learning-based techniques of email spam filtering. Artif Intell Rev 29:63–92
Zhu Y, Tan Y (2011) A local-concentration-based feature extraction approach for spam filtering. IEEE Trans Inf Forensics Secur 6(2):486–497
Özgür L, Güngör T (2012) Optimization of dependency and pruning usage in text classification. Pattern Anal Appl 15(1):45–58
Cormack GV, Lynam TR (2007) Online supervised spam filter evaluation. ACM Trans Inf Syst 25:1–29
Hershkop S, Stolfo SJ (2005) Combining email models for false positive reduction. In: Proceedings of the eleventh ACM SIGKDD international conference on Knowledge discovery in data mining (KDD). pp 98–107
Chang M, Yih W, Meek C (2008) Partitioned logistic regression for spam filtering. In: Proceedings of the 14th ACM SIGKDD international conference on knowledge discovery and data mining (KDD). pp 97–105
Yoshida K, Adachi F, Washio T, Motoda H, Homma T, Nakashima A, Fujikawa H, Yamazaki K (2004) Density-based spam detector. In: Proceedings of the tenth ACM SIGKDD international conference on knowledge discovery and data mining (KDD). pp 486–493
Chirita P, Diederich J, Nejdl W (2005) Mailrank: using ranking for spam detection. In: Proceedings of the 14th ACM international conference on Information and knowledge management (CIKM). pp 373–380
Tseng C, Huang J, Chen M (2007) Promail: using progressive email social network for spam detection. In: Zhou Z, Li H, Yang Q (eds) PAKDD. Lecture notes in computer science, vol 4426. Springer, Berlin, pp 833–840
Wu CH (2009) Behavior-based spam detection using a hybrid method of rule-based techniques and neural networks. Expert Syst Appl 36(3):4321–4330
Fumera G, Pillai I, Roli F (2006) Spam filtering based on the analysis of text information embedded into images. J Mach Learn Res 7:2699–2720
Konstantinidis K, Vonikakis V, Panitsidis G, Andreadis I (2011) A center-surround histogram for content-based image retrieval. Pattern Anal Appl 14(3):251–260
Lowe DG (2004) Distinctive image features from scale-invariant keypoints. Int J Comput Vision 60(2):91–110
Androutsopoulos I, Koutsias J, Cb KV, Spyropoulos CD (2000) An experimental comparison of naive Bayesian and keyword-based anti-spam filtering with personal e-mail messages. In: Proceedings of the 23rd annual international ACM SIGIR conference on research and development in information retrieval. ACM Press, New York, pp 160–167
Sahami M, Dumais S, Heckerman D, Horvitz E (1998) A Bayesian approach to filtering junk e-mail. In: Proceedings of National Conference on artificial intelligence
Cormack GV, Lynam TR (2005) Trec 2005 spam track overview. In: Proceedings of the fourteenth text retrieval conference (TREC05), Gaithersburg, MD
Mehta B, Nangia S, Gupta M, Nejdl W (2008) Detecting image spam using visual features and near duplicate detection. In: Proceedings of the 17th international conference on World Wide Web (WWW). pp 497–506
Dredze M, Gevaryahu R, Elias-Bachrach A (2007) Learning fast classifiers for image spam. In: Proceedings of the 4th Conference on Email and Anti-Spam (CEAS). pp 487–493
Kailath T (1967) The divergence and Bhattacharyya distance measures in signal selection. IEEE Trans Commun Technol 15(1):52–60
Acknowledgments
The completion of this research was made possible thanks to the Natural Sciences and Engineering Research Council of Canada (NSERC).
Author information
Authors and Affiliations
Corresponding author
Appendices
Appendix 1: Proof of Eq. 30
In the case of Langevin model, we can show that
The product of two Langevin can be written as
where
Using 48 and Langevin integral, we obtain
Appendix 2: Proof of Eq. 36
The KL divergence between two exponential distributions is presented by [68]
where E θ is the expectation with respect to \(p({\bf X}|\Uptheta), G(\theta)=(G_{1}(\theta), \ldots, G_{l}(\theta)),T({\bf X})= (T_{1}({\bf X}), \ldots, T_{l}({\bf X}))\) where l is the number of parameters of the distribution and T denotes transpose. Furthermore, we have the following:
Then by letting \(\Upphi_{\theta}= - a_{p}(\kappa)\) and \(G_{\theta}= \kappa{\varvec{\mu}}. \) Thus, the KL divergence between two Langevin distributions is given as
Appendix 3: Proof of Eq. 42
In the case of Langevin model, we can show the Shannon entropy is given by
Substitute Eq. 53 into Eq. 41 we obtain the Jensen–Shannon divergence for Langevin model.
Appendix 4: Proof of Eq. 44
We can show that the Rényi divergence between two Langevin distribution is given by
Assume that \(\zeta_{\kappa,\acute{\kappa}}= \sqrt{(\sigma\kappa)^2+((1-\sigma)\acute{\kappa})^2+2\sigma\kappa(1-\sigma)\acute{\kappa}({\varvec{\mu}}\cdot {\acute{\varvec{\mu}}})}\) and \(\psi_{{\varvec{\mu}},\acute{\varvec{\mu}}}= \frac{\sigma\kappa{\varvec{\mu}}+(1-\sigma)\acute{\kappa}{\acute{\varvec{\mu}}}}{\zeta_{\kappa,\acute{\kappa}}},\) and hence
By substituting Eq. 55 in Eq. 43 we obtain the symmetric Rényi divergence for two Langevin distributions.
Rights and permissions
About this article
Cite this article
Amayri, O., Bouguila, N. Beyond hybrid generative discriminative learning: spherical data classification. Pattern Anal Applic 18, 113–133 (2015). https://doi.org/10.1007/s10044-013-0323-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10044-013-0323-0