
Abstract
Because the data in practical applications usually satisfy the assumption of mixing subspaces and contain multiple features, multi-view subspace clustering has attracted extensive attention in recent years. In previous work, multi-view information can be utilized comprehensively by considering consistency. However, they often treat the information from different views equally. Because it is difficult to ensure that the information of all views is well mined, difficult view will reduce the performance. In this paper, we propose a novel multi-view subspace clustering method named consistent auto-weighted multi-view subspace clustering (CAMVSC) to overcome the above limitation by weighting automatically the representation matrices of each view. In our model, the density and sparsity are both considered to ensure the learning effect of each view. Although simultaneously using the self-representation and the auto-weighting strategy will bring difficulties to solve the model, we successfully design a special updating scheme to obtain the numerical algorithm, and prove its convergence theoretically. Extensive experimental results demonstrate the effectiveness of our proposed method.






Similar content being viewed by others

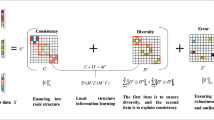
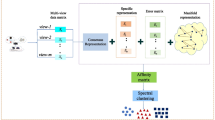
References
Vidal R (2011) Subspace clustering. IEEE Signal Process Mag 28(2):52–68
Liu G, Yan S (2011) Latent low-rank representation for subspace segmentation and feature extraction. In: ICCV, pp 1615–1622
Rao SR, Tron R, Vidal R, Ma Y (2010) Motion segmentation in the presence of outlying, incomplete, or corrupted trajectories. IEEE Trans Pattern Anal Mach Intell 32(10):1832–1845
Ma Y, Derksen H, Hong W, Wright J (2007) Segmentation of multivariate mixed data via lossy data coding and compression. IEEE Trans Pattern Anal Mach Intell 29(9):1546–1562
Peng X, Feng J, Xiao S, Yau W, Zhou JT, Yang S (2018) Structured autoencoders for subspace clustering. IEEE Trans Image Process 27(10):5076–5086
Zhang S, You C, Vidal R, CL (2021) Learning a self-expressive network for subspace clustering. In: CVPR, pp 12393–12403
Dong W, Wu X, Kittler J, Yin H (2019) Sparse subspace clustering via nonconvex approximation. Pattern Anal Appl 22(1):165–176
Wei L, Zhou R, Zhu C, Zhang X, Yin J (2020) Adaptive graph-regularized fixed rank representation for subspace segmentation. Pattern Anal Appl 23(1):443–453
Li S, Li K, Fu Y (2015) Temporal subspace clustering for human motion segmentation. In: ICCV, pp 4453–4461
Elhamifar E, Vidal R (2013) Sparse subspace clustering: algorithm, theory, and applications. IEEE Trans Pattern Anal Mach Intell 35(11):2765–2781
Liu G, Lin Z, Yan S, Sun J, Yu Y, Ma Y (2013) Robust recovery of subspace structures by low-rank representation. IEEE Trans Pattern Anal Mach Intell 35(1):171–184
Shi J, Malik J (2000) Normalized cuts and image segmentation. IEEE Trans Pattern Anal Mach Intell 22(8):888–905
Lin Z, Chen M, Wu L, Ma Y (2009)The augmented lagrange multiplier method for exact recovery of corrupted low-rank matrices. UIUC Technical Report, UILU-ENG-09-2215
Chen Y, Li C, You C (2020) Stochastic sparse subspace clustering. In: CVPR, pp 4154–4163
Tang K, Su Z, Liu Y, Jiang W, Zhang J, Sun X (2019) Subspace segmentation with a large number of subspaces using infinity norm minimization. Pattern Recognit 89:45–54
Tang K, Liu R, Su Z, Zhang J (2014) Structure-constrained low-rank representation. IEEE Trans Neural Netw Learn Syst 25(12):2167–2179
Lu C, Min H, Zhao Z, Zhu L, Huang D, Yan S (2012) Robust and efficient subspace segmentation via least squares regression. In: ECCV, vol. 7578, pp 347–360
Zhu C, Chen C, Zhou R, Wei L, Zhang X (2020) A new multi-view learning machine with incomplete data. Pattern Anal Appl 23(3):1085–1116
Tao Z, Liu H, Li S, Ding Z, Fu Y (2017) From ensemble clustering to multi-view clustering. In: IJCAI, pp 2843–2849
Tao Z, Liu H, Li S, Ding Z, Fu Y (2020) Marginalized multiview ensemble clustering. IEEE Trans Neural Netw Learn Syst 31(2):600–611
de Sa VR (2005) Spectral clustering with two views. In: ICML Workshop, pp 20–27
Kumar A, Rai P, III HD (2011) Co-regularized multi-view spectral clustering. In: NIPS, pp 1413–1421
Zhang C, Fu H, Liu S, Liu G, Cao X (2015) Low-rank tensor constrained multiview subspace clustering. In: ICCV, pp 1582–1590
Cao X, Zhang C, Fu H, Liu S, Zhang H (2015) Diversity-induced multi-view subspace clustering. In: CVPR, pp 586–594
Zhang C, Liu Y, Fu H (2019) Ae2-nets: autoencoder in autoencoder networks. In: CVPR, pp 2577–2585
Zhang C, Fu H, Wang J, Li W, Cao X, Hu Q (2020) Tensorized multi-view subspace representation learning. Int J Comput Vis 128(8):2344–2361
Abavisani M, Patel VM (2018) Deep multimodal subspace clustering networks. IEEE J Sel Top Signal Process 12(6):1601–1614
Li R, Zhang C, Fu H, Peng X, Zhou JT, Hu Q (2019) Reciprocal multi-layer subspace learning for multi-view clustering. In: ICCV, pp 8171–8179
Zhang C, Fu H, Hu Q, Cao X, Xie Y, Tao D, Xu D (2020) Generalized latent multi-view subspace clustering. IEEE Trans Pattern Anal Mach Intell 42(1):86–99
Gao H, Nie F, Li X, Huang H (2015) Multi-view subspace clustering. In: ICCV, pp 4238–4246
Wang X, Guo X, Lei Z, Zhang C, Li SZ (2017) Exclusivity-consistency regularized multi-view subspace clustering. In: CVPR, pp 1–9
Luo S, Zhang C, Zhang W, Cao X (2018) Consistent and specific multi-view subspace clustering. In: AAAI, pp 3730–3737
Wang H, Yang Y, Liu B (2020) GMC: graph-based multi-view clustering. IEEE Trans Knowl Data Eng 32(6):1116–1129
Nie F, Li J, Li X (2016) Parameter-free auto-weighted multiple graph learning: a framework for multiview clustering and semi-supervised classification. In: IJCAI, pp 1881–1887
Zhu P, Hui B, Zhang C, Du D, Wen L, Hu Q (2019) Multi-view deep subspace clustering networks. CoRR arXiv:1908.01978
Zhang X (2004) Matrix analysis and applications. Tsinghua University Press, Beijing
Liu G, Lin Z, Yu Y (2010) Robust subspace segmentation by low-rank representation. In: ICML, pp 663–670
Dalal N, Triggs B (2005) Histograms of oriented gradients for human detection. In: CVPR, pp 886–893
Lades M, Vorbrüggen JC, Buhmann JM, Lange J, von der Malsburg C, Würtz RP, Konen W (1993) Distortion invariant object recognition in the dynamic link architecture. IEEE Trans Comput 42(3):300–311
Ojansivu V, Heikkilä J (2008) Blur insensitive texture classification using local phase quantization. In: ICISP, vol. 5099, pp 236–243
Acknowledgements
This work was supported in part by the National Natural Science Foundation of China under Grant 62076115, in part by the LiaoNing Revitalization Talents Program under Grant XLYC1907169, and in part by the Program of Star of Dalian Youth Science and Technology under Grant 2019RQ033, 2020RQ053.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declared that they have no conflicts of interest to this work.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix A Proof of Theorems
Appendix A Proof of Theorems
The Proof of Theorem 1
For presentation purposes, we ignore the superscript of \(Z^{(v)}\) for the moment. When we replace the model (11) with the model (13), since \(Z_{m:}^{k+1}\) is the optimal solution of the model (13), we can get
where \(\widetilde{Z_M^k}\) represents the representation matrix which has been updated the first \(m-1\)-th row in the \(k+1\)-th iteration, \(\widetilde{Z_{M+1}^k}\) represents the representation matrix which has been updated the first m-th row in the \(k+1\)-th iteration, \(g(\widetilde{Z_M^k})\) is the objective function value of \(\widetilde{Z_M^k}\) in Eq. (13). Because \(a-\frac{a^2}{2b}\le b-\frac{b^2}{2b}\), we have
By adding (A2) to (A1), we can get
where \(f(\widetilde{Z_M^k})\) is the objective function value of \(\widetilde{Z_M^k}\) in Eq. (11). And since \(\widetilde{Z_1^k}=Z^k\), we can get
where N denotes the number of samples, so Theorem 1 is proved. \(\square \)
The Proof of Theorem 2
For \(E^{(v)}\), since the optimal solution will minimize the objective function, we can obtain
For F, similarly, by using \(a-\frac{a^2}{2b}\le b-\frac{b^2}{2b}\), we can obtain
where \(v=1, \ldots , V\). According to the model (16), we know that \(\phi (F^{k+1})\le \phi (F^{k})\), where \(\phi (F^{k})\) denotes the objective function value of F with the k-th iteration in the model (16). Utilizing \(\alpha ^{(v),k}=\frac{1}{2\sqrt{{\rm Tr}((F^k)^T)L^{(v),k+1}F^{k}}}\), we can get
Adding (A7) to (A6), we can obtain
Hence, by updating \(Z^{(v)}\), \(E^{(v)}\) and F step by step, we can obtain
Hence, \(\varphi (Z^{(v),k+1},E^{(v),k+1},F^{k+1})\le \varphi (Z^{(v),k},E^{(v),k},F^{k})\). Theorem 2 is proved. In summary, CAMVSC is also convergent in theory. \(\square \)
Rights and permissions
About this article

Cite this article
Tang, K., Cao, L., Zhang, N. et al. Consistent auto-weighted multi-view subspace clustering. Pattern Anal Applic 25, 879–890 (2022). https://doi.org/10.1007/s10044-022-01085-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10044-022-01085-0