
Abstract
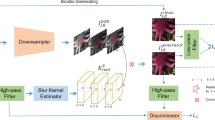
Recently, Real-World Super-Resolution has become one of the most popular research fields in the scope of Single Image Super-Resolution, as it focuses on real-world applications. Due to the lack of paired training data, developing real-world super-resolution is considered a more challenging problem. Previous works intended to model the real image degradation process so that paired training images could be obtained. Specifically, some methods attempt to explicitly estimate degradation kernels and noise patterns, while others introduce degradation networks to learn maps from high-resolutions (HRs) to low-resolutions (LRs), which is a more direct and practical way. However, previous degradation networks take only one HR image as an input and therefore can hardly learn the real sensor noise contained in LR samples. In this paper, we propose a novel dual-input degradation network that takes a real LR image as an additional input to better learn the real sensor noise. Furthermore, we propose an effective self-supervised learning method to synchronously train the degradation network along with the reconstruction network. Extensive experiments showed that our dual-input degradation network can better simulate the real degradation process, thereby indicating that the reconstruction network outperforms state-of-the-art methods. Original codes and most of the testing data can be found on our website.








Similar content being viewed by others


Data availability
The data that support the findings of this study are openly available in Codalab at https://competitions.codalab.org/competitions/22220#participate.
Notes
Peak Signal-to-Noise Ratio (PSNR) is a classical metric calculated from the \(L_2\) distance between two images.
CycleGAN [15] was designed to solve the Image-to-Image Translation problem, which is very different from Image Super-Resolution. However, their idea of cycle-consistency loss is so inspiring that many Real-SR methods adopt this idea (the implementations are very different).
References
Dong C, Loy CC, He K, Tang X (2016) Image Super-Resolution Using Deep Convolutional Networks. IEEE Transactions on Pattern Analysis and Machine Intelligence 38(2): 295–307. https://doi.org/10.1109/TPAMI.2015.2439281. Conference Name: IEEE Transactions on Pattern Analysis and Machine Intelligence
Lim B, Son S, Kim H, Nah S, Lee KM (2017) Enhanced Deep Residual Networks for Single Image Super-Resolution. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pp. 1132–1140. https://doi.org/10.1109/CVPRW.2017.151. ISSN: 2160-7516
Ledig C, Theis L, Huszár F, Caballero J, Cunningham A, Acosta A, Aitken A, Tejani A, Totz J, Wang Z, Shi W (2017) Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 105–114. https://doi.org/10.1109/CVPR.2017.19. ISSN: 1063-6919
Wang X, Yu K, Wu S, Gu J, Liu Y, Dong C, Qiao Y, Loy CC (2019) ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks. In: Leal-Taixé L, Roth S (eds.) Computer Vision – ECCV 2018 Workshops. Lecture Notes in Computer Science, pp. 63–79. Springer, Cham. https://doi.org/10.1007/978-3-030-11021-5_5
Cai J, Zeng H, Yong H, Cao Z, Zhang L (2019) Toward Real-World Single Image Super-Resolution: A New Benchmark and a New Model. In: 2019 IEEE/CVF International Conference on Computer Vision (ICCV), pp. 3086–3095. IEEE, Seoul, Korea (South). https://doi.org/10.1109/ICCV.2019.00318. https://ieeexplore.ieee.org/document/9009805/ Accessed 2021-03-14
Blau Y, Mechrez R, Timofte R, Michaeli T, Zelnik-Manor L (2019) The 2018 PIRM Challenge on Perceptual Image Super-Resolution. In: Leal-Taixé L, Roth S (eds.) Computer Vision – ECCV 2018 Workshops vol. 11133, pp. 334–355. Springer, Cham. https://doi.org/10.1007/978-3-030-11021-5_21. Series Title: Lecture Notes in Computer Science. http://link.springer.com/10.1007/978-3-030-11021-5_21 Accessed 2021-07-19
Ji X, Cao Y, Tai Y, Wang C, Li J, Huang F (2020) Real-World Super-Resolution via Kernel Estimation and Noise Injection. In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pp. 1914–1923. https://doi.org/10.1109/CVPRW50498.2020.00241. ISSN: 2160-7516
Lugmayr A, Danelljan M, Timofte R, Ahn N, Bai D, Cai J, Cao Y, Chen J, Cheng K, Chun S, Deng W, El-Khamy M, Ho CM, Ji X, Kheradmand A, Kim G, Ko H, Lee K, Lee J, Li H, Liu Z, Liu Z-S, Liu S, Lu Y, Meng Z, Michelini PN, Micheloni C, Prajapati K, Ren H, Seo YH, Siu W-C, Sohn K-A, Tai Y, Umer RM, Wang S, Wang H, Wu TH, Wu H, Yang B, Yang F, Yoo J, Zhao T, Zhou Y, Zhuo H, Zong Z, Zou X (2020) NTIRE 2020 Challenge on Real-World Image Super-Resolution: Methods and Results. In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pp. 2058–2076. https://doi.org/10.1109/CVPRW50498.2020.00255. ISSN: 2160-7516
Bell-Kligler S, Shocher A, Irani M (2019) Blind super-resolution kernel estimation using an internal-GAN. Advances in Neural Information Processing Systems 32
Choi J-H, Zhang H, Kim J-H, Hsieh C-J, Lee J-S (2019) Evaluating Robustness of Deep Image Super-Resolution Against Adversarial Attacks. In: 2019 IEEE/CVF International Conference on Computer Vision (ICCV), pp. 303–311. https://doi.org/10.1109/ICCV.2019.00039. ISSN: 2380-7504
Lugmayr A, Danelljan M, Timofte R (2019) Unsupervised Learning for Real-World Super-Resolution. In: 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), pp. 3408–3416. https://doi.org/10.1109/ICCVW.2019.00423. ISSN: 2473-9944
Chen S, Han Z, Dai E, Jia X, Liu Z, Liu X, Zou X, Xu C, Liu J, Tian Q (2020) Unsupervised Image Super-Resolution with an Indirect Supervised Path. In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pp. 1924–1933. IEEE, Seattle, WA, USA. https://doi.org/10.1109/CVPRW50498.2020.00242. https://ieeexplore.ieee.org/document/9151023/ Accessed 2021-06-05
Kim G, Park J, Lee K, Lee J, Min J, Lee B, Han DK, Ko H (2020) Unsupervised Real-World Super Resolution with Cycle Generative Adversarial Network and Domain Discriminator. In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pp. 1862–1871. https://doi.org/10.1109/CVPRW50498.2020.00236. ISSN: 2160-7516
Sun W, Gong D, Shi Q, van den Hengel A, Zhang Y (2021) Learning to Zoom-In via Learning to Zoom-Out: Real-World Super-Resolution by Generating and Adapting Degradation. IEEE Transactions on Image Processing 30:2947–2962. https://doi.org/10.1109/TIP.2021.3049951. Conference Name: IEEE Transactions on Image Processing
Zhu J-Y, Park T, Isola P, Efros AA (2017) Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In: 2017 IEEE International Conference on Computer Vision (ICCV), pp. 2242–2251. https://doi.org/10.1109/ICCV.2017.244. ISSN: 2380-7504
Zhang Y, Li K, Li K, Wang L, Zhong B, Fu Y (2018) Image Super-Resolution Using Very Deep Residual Channel Attention Networks. In: Ferrari V, Hebert M, Sminchisescu C, Weiss Y (eds.) Computer Vision – ECCV 2018 vol. 11211, pp. 294–310. Springer, Cham. https://doi.org/10.1007/978-3-030-01234-2_18. Series Title: Lecture Notes in Computer Science. http://link.springer.com/10.1007/978-3-030-01234-2_18 Accessed 2021-06-06
Goodfellow I, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, Courville A, Bengio Y (2014) Generative adversarial networks. Adv Neural Inf Process Syst 3:87
Zhao T, Ren W, Zhang C, Ren D, Hu Q (2018) Unsupervised degradation learning for single image super-resolution. arXiv:1812.04240 [cs]. arXiv: 1812.04240. Accessed 15 June 2021
Zhang R, Isola P, Efros AA, Shechtman E, Wang O (2018) The unreasonable effectiveness of deep features as a perceptual metric. In: 2018 IEEE/CVF conference on computer vision and pattern recognition, pp 586–595. https://doi.org/10.1109/CVPR.2018.00068. ISSN: 2575-7075
Bulat A, Yang J, Tzimiropoulos G (2018) To learn image super-resolution, use a GAN to learn how to do image degradation first. In: Ferrari V, Hebert M, Sminchisescu C, Weiss Y (eds.) Computer vision–ECCV 2018. Lecture Notes in Computer Science, pp 187–202. Springer, Cham. https://doi.org/10.1007/978-3-030-01231-1_12
Simonyan K, Zisserman A (2015) Very deep convolutional networks for large-scale image recognition. arXiv:1409.1556 [cs]. arXiv: 1409.1556. Accessed 05 June 2021
Timofte R, Agustsson E, Gool LV, Yang M-H, Zhang L, Lim B, Son S, Kim H, Nah S, Lee KM, Wang X, Tian Y, Yu K, Zhang Y, Wu S, Dong C, Lin L, Qiao Y, Loy CC, Bae W, Yoo J, Han Y, Ye JC, Choi J-S, Kim M, Fan Y, Yu J, Han W, Liu D, Yu H, Wang Z, Shi H, Wang X, Huang TS, Chen Y, Zhang K, Zuo W, Tang Z, Luo L, Li S, Fu M, Cao L, Heng W, Bui G, Le T, Duan Y, Tao D, Wang R, Lin X, Pang J, Xu J, Zhao Y, Xu X, Pan J, Sun D, Zhang Y, Song X, Dai Y, Qin X, Huynh X-P, Guo T, Mousavi HS, Vu TH, Monga V, Cruz C, Egiazarian K, Katkovnik V, Mehta R, Jain AK, Agarwalla A, Praveen CVS, Zhou R, Wen H, Zhu C, Xia Z, Wang Z, Guo Q (2017) NTIRE 2017 challenge on single image super-resolution: methods and results. In: 2017 IEEE conference on computer vision and pattern recognition workshops (CVPRW), pp 1110–1121. https://doi.org/10.1109/CVPRW.2017.149. ISSN: 2160-7516
Agustsson E, Timofte R (2017) NTIRE 2017 challenge on single image super-resolution: dataset and study. In 2017 IEEE conference on computer vision and pattern recognition workshops (CVPRW), pp 1122–1131. https://doi.org/10.1109/CVPRW.2017.150. ISSN: 2160-7516
Ignatov A, Kobyshev N, Timofte R, Vanhoey K (2017) DSLR-quality photos on mobile devices with deep convolutional networks. In: 2017 IEEE international conference on computer vision (ICCV), pp 3297–3305. https://doi.org/10.1109/ICCV.2017.355. ISSN: 2380-7504
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of Interest
We declare that we do not have any commercial or associative interest that represents a conflict of interest in connection with the work submitted.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix A: Convolution with Zero-padding
In the scope of SISR, deep-learning-based models always use zero padding to ensure that the convolution outputs have the same size as inputs. We consider a single-input CNN-based network G (as used in most existing unsupervised/self-supervised methods) containing n convolution layers, and an input image x of size \(h \times w\), with all pixel values set to be the same (e.g., full-white color). We set G with random weights and random bias values; then, we calculate G(x), we will obtain an output with a patch size \((h-n) \times (w-n)\) having the same pixel value (Fig. 9).

Results of a single-input CNN-based network G with zero-padding. If G is a shallow network, most of the pixels in the output will have the same value. The input image has a typical size of \(32 \times 32\), and ‘n’ is the number of convolution layers
This could be a fatal weakness. First, all the hidden outputs of which patch size \((h-n) \times (w-n)\) is positive will contain no noise at all. In addition, zero padding is completely artificial, which is a very low-efficiency way for training. Based on our observation, those single-input CNN-based networks can hardly learn the real sensor noise. We have shown this phenomenon in our ablation study (Sect. 4.5).
Appendix B: Cleaned-up result
As mentioned in Sect. 4.2, the clean-up method was helpful. We adopted this method in Track2 and evaluated it above. On the one hand, this method could help our model reconstruct more details (Fig. 8). On the other hand, it will introduce unnecessary noise if we look at the reconstruction results carefully.

The perceptual quality of the cleaned-up results are still blurry and noisy. It is notable that images in the same row are cropped from the same scene but are not fully matched
In Fig. 10, we show some of the cleaned-up results compared with the original noisy LR images and the target images. As we can see, the cleaned-up image is not completely clean since the bicubic algorithm is not an ideal clean-up algorithm.
Appendix C: Full-reference metrics of Track1
We used only the \(L_2\) loss as the loss function instead of Eq. (2) for the reconstruction network, trained two independent models, and calculated the PSNR, SSIM, and LPIPS [19] values on the 100 validation image pairs.
As shown in Table 3, \(L_2\) loss could lead to a higher PSNR and SSIM value, which is a common phenomenon that appeared in many other works. In the context of Image Super-Resolution, there is no persuasive measurement of the image quality yet. Thus, we provided these results for reference only.
Appendix D: Full results on both tracks

Full result on Track1. The left part is the LR image upscaled by a 4 × 4 factor, the right part is the SR result generated by our DDNSR model

Full results on Track2. The left part is the LR image upscaled by a 4 × 4 factor, the right part is the SR result generated by our DDNSR model
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Li, Y., Chen, H., Li, T. et al. DDNSR: a dual-input degradation network for real-world super-resolution. Pattern Anal Applic 26, 875–888 (2023). https://doi.org/10.1007/s10044-023-01150-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10044-023-01150-2