
Abstract
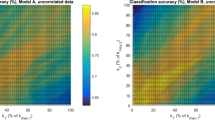
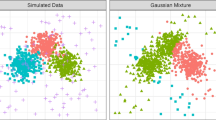
: Gaussian mixture modelling is used to provide a semi-parametric density estimate for a given data set. The fundamental problem with this approach is that the number of mixtures required to adequately describe the data is not known in advance. In our previous work , we described an algorithm, termed Predictive Validation, which attempted to automatically select the number of components. The aim of this paper is to investigate the influence of the various parameters in our model selection method in order to develop it into an operational tool. In this paper, we demonstrate the successful application of model validation to three applications in which the selected models are used for supervised classification, unsupervised classification and outlier detection tasks.
Similar content being viewed by others

Author information
Authors and Affiliations
Additional information
Received: 23 Novenber 2000, Received in revised form: 24 April 2001, Accepted: 21 May 2001
Rights and permissions
About this article
Cite this article
Kittler, J., Messer, K. & Sadeghi, M. Model Selection by Predictive Validation. Pattern Anal Appl 5, 245–260 (2002). https://doi.org/10.1007/s100440200022
Issue Date:
DOI: https://doi.org/10.1007/s100440200022