
Abstract
We propose a formulation of the distributionally robust variational inequality (DRVI) to deal with uncertainties of distributions of the involved random variables in variational inequalities. Examples of the DRVI are provided, including the optimality conditions for distributionally robust optimization and distributionally robust games (DRG). The existence of solutions and monotonicity of the DRVI are discussed. Moreover, we propose a sample average approximation (SAA) approach to the DRVI and study its convergence properties. Numerical examples of DRG are presented to illustrate solutions of the DRVI and convergence properties of the SAA approach.


Similar content being viewed by others
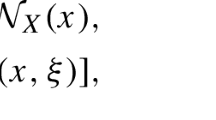
Notes
The notation \(P_1 \times \ldots \times P_r\) stands for the product of measures \(P_1, \dots , P_r\).
For the sake of simplicity we consider here just one constraint; of course this can be extended to a finite number of such constraints in a straightforward way.
For convenience, we use the same notation \({\mathbb {P}}\) for the true distribution and the reference measure. We can distinguish them by context.
Banach spaces \({{\mathcal {Z}}}\) and \({{\mathcal {Z}}}^*\), equipped with the respective weak and weak\(^*\) topologies, are paired topological vector spaces with respect to the bilinear form \(\langle \zeta , Z\rangle =\int _\Xi \zeta Zd{\mathbb {P}}\), \(Z\in {{\mathcal {Z}}}\), \(\zeta \in {{\mathcal {Z}}}^*\). Note that the weak topology of \({{\mathcal {Z}}}\) and weak\(^*\) topology of \({{\mathcal {Z}}}^*\), restricted to respective bounded sets, are metrizable and hence can be described in terms of convergent sequences. The weak convergence \(Z_{k}{\mathop {\rightarrow }\limits ^{w}}{\bar{Z}}\) means that \(\langle \zeta ,Z_k\rangle \) converges to \(\langle \zeta , {\bar{Z}}\rangle \) for any \(\zeta \in {{\mathcal {Z}}}^*\). The weak\(^*\) convergence \(\zeta _k{\mathop {\rightarrow }\limits ^{w^*}}{\bar{\zeta }}\) means that \(\langle \zeta _k,Z\rangle \) converges to \(\langle {\bar{\zeta }},Z\rangle \) for any \(Z\in {{\mathcal {Z}}}\).
That is, if \(x_k\in X\) converges to \({\bar{x}}\) and \(\zeta _k\in {\bar{{{\mathfrak {A}}}}}_{x_k}\) is such that \(\zeta _k{\mathop {\rightarrow }\limits ^{w^*}}{\bar{\zeta }}\), then \({\bar{\zeta }}\in {\bar{{{\mathfrak {A}}}}}_{{\bar{x}}}\).
Any \(Z:\{\xi ^1,\ldots ,\xi ^N\}\rightarrow {\mathbb {R}}\) can be identified with N-dimensional vector \((Z(\xi _1),\ldots ,Z(\xi _N))\), and hence the empirical risk measure can be viewed as defined on \({\mathbb {R}}^N\).
Note that \(\zeta \) is a density on \(\{\xi ^1,\ldots ,\xi ^N\}\) if \(\zeta \ge 0\) and \(N^{-1}\sum _{i=1}^N \zeta _i=1\), i.e., \(N^{-1}\zeta \in \Delta _N\).
By the law invariance of \({{\mathcal {R}}}(Z)\) it can be considered as a function of \(H_Z\).
In Step 4 of Algorithm 1, we do not specify how to solve the monotone VI: \(0\in F^k(z) + {{\mathcal {N}}}_{X_1\times X_2\times {\mathbb {R}}_+}(z)\). We can solve it by any suitable method, such as the extragradient method.
Recall that a sequence \(P_N\) of probability measures converges weakly to a probability measure P if \(\int gdP_N\rightarrow \int g dP\) for any bounded continuous function \(g:\Xi \rightarrow {\mathbb {R}}\), see e.g., Billingsley [3] for a discussion of weak convergence of probability measures.
References
Bayraksan, G., Love, D.K.: Data-driven stochastic programming using phi-divergences. In: Tutorials in Operations Research. INFORMS, Catonsville, MD (2015)
Ben-Tal, A., Teboulle, M.: Penalty functions and duality in stochastic programming via phi-divergence functionals. Math. Oper. Res. 12, 224–240 (1987)
Billingsley, P.: Convergence of Probability Measures. Wiley, New York (1999)
Bertsimas, D., Sim., M.: The price of robustness. Oper. Res. 52, 35–53 (2004)
Bonnans, J.F., Shapiro, A.: Perturbation Analysis of Optimization Problems. Wiley Series in Probability and Statistics. Wiley, New York (2000)
Chen, X., Fukushima, M.: Expected residual minimization method for stochastic linear complementarity problems. Math. Oper. Res. 30, 1022–1038 (2005)
Chen, X., Pong, T.K., Wets, R.: Two-stage stochastic variational inequalities: an ERM-solution procedure. Math. Program. 165, 71–112 (2015)
Chen, X., Wets, R., Zhang, Y.: Stochastic variational inequalities: residual minimization smoothing sample average approximations. SIAM J. Optim. 22, 649–673 (2012)
Chen, X., Sun, H., Xu, H.: Discrete approximation of two-stage stochastic and distributionally robust linear complementarity problems. Math. Program. 177, 255–289 (2019)
Chen, X., Shapiro, A., Sun, H.: Convergence analysis of sample average approximation of two-stage stochastic generalized equations. SIAM J. Optim. 29, 135–161 (2019)
Chen, Y., Sun, H., Xu, H.: Decomposition and discrete approximation methods for solving two-stage distributionally robust optimization problems. Comput. Optim. Appl. 28, 205–238 (2021)
Chen, Y., Lan, G., Ouyang, Y.: Accelerated schemes for a class of variational inequalities. Math. Program. 165, 113–149 (2017)
Chieu, N.H., Trang, N.T.Q.: Coderivative and monotonicity of continuous mappings. Taiwan. J. Math. 16, 353–365 (2012)
Csiszár, I.: Eine informationstheoretische ungleichung und ihre anwendung auf den beweis der ergodizitat von markoffschen ketten, Magyar. Tud. Akad. Mat. Kutato Int. Kozls 8 (1963)
Dommel, P., Pichler, A.: Convex risk measures based on divergence. Optimization (2020)
Facchinei, F., Pang, J.S.: Finite-Dimensional Variational Inequalities and Complementarity Problems. Springer, New York (2003)
Hadjisavvas, H., Komlósi, S., Schaible, S.: Handbook of Generalized Convexity and Generalized Monotonicity. Springer, New York (2005)
Krebs, V., Schmidt, M.: \(\Gamma \)-Robust linear complementarity problems. Optim. Methods Softw. (2020)
Morimoto, T.: Markov processes and the h-theorem. J. Phys. Soc. Jpn. 18, 328–333 (1963)
Milz, J., Ulbrich, M.: An approximation scheme for distributionally robust nonlinear optimization. SAIM J. Optim. 30, 1996–2025 (2020)
Morton, S.: Lagrange multipliers revisited, Cowles Commission Discussion Paper No. 403 (1950)
Pardo, L.: Statistical Inference Based on Divergence Measures. Chapman and Hall/CRC, Boca Raton (2005)
Römisch, W.: Stability of Stochastic Programming Problems. In: Ruszczyński, A., Shapiro, A. (eds.) Stochastic Programming. Elsevier, Amsterdam (2003)
Rockafellar, R.T., Wets, R.J.-B.: Stochastic variational inequalities: single-stage to multistage. Math. Program. 165, 331–360 (2017)
Rockafellar, R.T., Sun, J.: Solving monotone stochastic variational inequalities and complementarity problems by progressive hedging. Math. Program. 174, 453–471 (2018)
Shapiro, A.: Consistency of sample estimates of risk averse stochastic programs. J. Appl. Probab. 50, 533–541 (2013)
Shapiro, A., Dentcheva, D., Ruszczyński, A.: Lectures on Stochastic Programming: Modeling and Theory, 2nd edn. SIAM, Philadelphia (2014)
Shapiro, A.: Distributionally robust stochastic programming. SIAM J. Optim. 27, 2258–2275 (2017)
Shanbhag U. V.: Stochastic variational inequality problems: applications, analysis, and algorithms. INFORMS Tutor. Oper. Res. 71–107 (2013)
Sun, H., Xu, H.: Convergence analysis for distributionally robust optimization and equilibrium problems. Math. Oper. Res. 41, 377–401 (2016)
Sun, H., Chen, X.: Two-stage stochastic variational inequalities: theory, algorithms and application. J. Oper. Res. Soc. China 9, 1–32 (2019)
Wu, D., Han, J.Y., Zhu, J.H.: Robust solutions to uncertain linear complementarity problems. Acta Math. Sin. (Engl. Ser.) 27, 339–352 (2011)
Xu, H., Liu, Y., Sun, H.: Distributionally robust optimization with matrix moment constraints: Lagrange duality and cutting plane methods. Math. Program. 169, 489–529 (2018)
Xie, Y., Shanbhag, U.V.: On robust solutions to uncertain linear complementarity problems and their variants. SIAM J. Optim. 26(4), 2120–2159 (2016)
Acknowledgements
We would like to thank the editor and referees for their helpful comments and suggestions.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
H. Sun: Research of this author was partly supported by National Natural Science Foundation of China 12122108 and 11871276. A. Shapiro: Research of this author was partly supported by NSF Grant 1633196. X. Chen: Research of this author was partly supported by Hong Kong Research Grant Council PolyU15300219.
7 Appendix
7 Appendix
In this Appendix, we give some proofs and necessary results used in this paper.
Example 8
Consider the Average Value-at-Risk,
Here \({{\mathcal {Z}}}=L_1(\Xi ,{{\mathcal {B}}},{\mathbb {P}})\) and a minimizer in the right hand side of (A1) is \({\bar{\tau }}=H_Z^{-1}(\alpha )\). The empirical estimate of \(\mathsf{AV@R}_{1-\alpha }(\phi ^x)\) is then
We have that \(\partial \mathsf{AV@R}_{1-\alpha }(Z)\) is a singleton iff \({\mathbb {P}}\{Z=\kappa \}=0\), where \(\kappa _\alpha :=H_Z^{-1}(\alpha )\). Suppose that \(\partial \mathsf{AV@R}_{1-\alpha }(Z)=\{{\bar{\zeta }}\}\) is a singleton. Then
(cf. [27, eq. (6.80), p. 292]). For \(x\in X\) and \(Z:=\phi ^x\) let \(\{{\bar{\zeta }}^x\}\) be the corresponding subdifferential. The subdifferential \({\hat{\zeta }}^x=(\zeta ^x_1,\ldots ,\zeta ^x_N)\) of the corresponding empirical estimate is obtained by replacing \(\kappa _\alpha \) with their empirical estimates. That is \(\zeta ^x_j=(1-\alpha )^{-1}\) if \(\phi ^x(\xi ^j)> \kappa _{\alpha , N}\) and \(\zeta ^x_j=0\) if \(\phi ^x(\xi ^j)<\kappa _{\alpha ,N}\), where \(\kappa _{\alpha ,N}\) is the empirical estimate of \(\kappa _\alpha \). Note that because of the assumption \({\mathbb {P}}\{Z=\kappa \}=0\), the empirical estimate \(\kappa _{\alpha ,N}\) converges w.p.1 to \(\kappa _\alpha \).
Consider the probability distribution \(P^x_{N}\) on \(\{\xi ^1,\ldots ,\xi ^N\}\) associated with density \({\hat{\zeta }}^x\), i.e., with \(\xi ^j\) being assigned probability \(1/((1-\alpha ) N)\) if \(\phi ^x(\xi ^j)>\kappa _{\alpha ,N}^x\), and 0 otherwise. We view \(P^x_{N}\) as the empirical counterpart of \(P^x\), where \(P^x\) is the probability measure absolutely continuous with respect to \({\mathbb {P}}\) and having density \({\bar{\zeta }}^x\), i.e.,
Consider a continuous bounded function \(g:\Xi \rightarrow {\mathbb {R}}\). Since \(g(\cdot )\) is bounded and continuous, \(\kappa _{\alpha ,N}^x\rightarrow \kappa _\alpha ^x\) w.p.1 and \({\mathbb {P}}\{\phi ^x(\xi )=\kappa _\alpha ^x\}=0\), we have that
converges w.p.1 to
That is \(P^x_{N}\) converges weaklyFootnote 11 to \(P^x\). Moreover, by Proposition 6 in the Appendix, we have if \(\{x_N\}\) is a sequence in X converging to x, then \(\int _\Xi g(s) dP^{x_N}_{N}(s)\) converges to \(\int _{\phi ^x(\xi )>\kappa } g(s)d{\mathbb {P}}(s)\) w.p.1, and hence \(P^{x_N}_{ N}\) converges weakly to \(P^x\).
Proposition 6
Suppose (i) \(\phi (\cdot ,\xi )\) is Lipschitz continuous in \(x\in X\) with a uniform Lipschitz modules \(k_\phi \), (ii) the CDF of \(\phi ^{{\bar{x}}}\) is strictly monotone, and (iii) \(\{x_N\}\) is a sequence in X converging to \({\bar{x}}\), (iv) \(|\kappa ^{x'}_\alpha |\) is bounded by a constant number for all \(x'\in {{\mathcal {B}}}(x)\cap X\). Then for any bounded and continuous function g, \(\int _\Xi g(s) dP^{x_N}_{N}(s)\) converges to \(\int _{\phi ^{{\bar{x}}}(\xi )>\kappa _{\alpha }^{{\bar{x}}}} g(s)d{\mathbb {P}}(s)\).
Proof
For any continuous and bounded function g(s),
We first prove that \(\kappa _{\alpha ,N}^{x_N}\) converges to \(\kappa _{\alpha }^{{\bar{x}}}\) w.p.1. To see this, by condition (ii), we have \({\mathbb {P}}\{\phi ^{{\bar{x}}}(\xi )=\kappa _{\alpha }^{{\bar{x}}}\}=0\), then
and
It is easy to observe that \((\phi ^{{\bar{x}}}(\xi ) -\tau )_+\) is continuous w.r.t. x and dominated by an integrable function, then by uniform law of large numbers [27, Theorem 7.48]
as \(N\rightarrow \infty \) w.p.1. Then by conditions (i)–(iv) and [5, Proposition 4.4], we have that \(\kappa _{\alpha ,N}^{x_N}\) converges to \(\kappa _{\alpha }^{{\bar{x}}}\) w.p.1.
Then we prove the convergence of first part in the right side of (A5). Let
and
Then
where \({\mathbb {P}}_N\) is an empirical estimation of \({\mathbb {P}}\). Note that \(\kappa ^{x_N}_{\alpha ,N}\rightarrow \kappa ^{{\bar{x}}}_\alpha \) and \(x_N\rightarrow {\bar{x}}\), \(A^1_N\subset A^3_N\) and \(A^2_N\subset A^4_N\), and \( A^3_N\) and \( A^4_N\) converge to singleton sets. Then by condition (i) and (ii), \({\mathbb {P}}_N(A^1_N\cup A^2_N)\le {\mathbb {P}}_N(A^3_N\cup A^4_N) \rightarrow 0\) as \(N\rightarrow \infty \) w.p.1, which implies
as \(N\rightarrow \infty \) w.p.1.
Then we consider the second part in the right side of (A5). Since g is continuous and bounded, by classical law of large numbers, as \(N\rightarrow \infty \) w.p.1,
Combining discussion above, we have the conclusion. \(\square \)
Then we derive a kind of uniform Glivenko-Cantelli theorem which we need in the proof of Lemma 2. Let \(f(x,\xi )\) be a random function and \(\{x_N\}\rightarrow x\) as \(N\rightarrow \infty \). Moreover, suppose \(f(x, \xi )\) is Lipschitz continuous w.r.t. x and \(\xi \), and the Lipschitz modules \(\kappa (\xi )\) of \(f(\cdot , \xi )\) is integrable. We use \(H_{x_N}(t)\) and \(H_{x}(t)\) to denote the CDF of \(f(x_N, \xi )\) and \(f(x, \xi )\) w.r.t. \({\mathbb {P}}\) and \(H^N_{x_N}(t)\) and \(H^N_{x}(t)\) are used to denote the CDF of their empirical distributions i.i.d samples \(\{\xi ^1, \ldots , \xi ^N\}\).
Lemma 3
Suppose \(f(x, \xi )\) is integrable and continuous w.r.t. x, and \({\mathbb {P}}\) is a continuous distribution. Then for each \(\epsilon >0\), there exists a finite partition of the real line of the form \(-\infty =t_0<t_1<\cdots <t_k=\infty \) such that for \(0\le j\le k-1\), \(H(x_N, t_{j+1}) - H(x_N, t_j)\le \epsilon \) for all N sufficiently large.
Proof
Since \({\mathbb {P}}\) is a continuous distribution, \(H_{x}(t)\) is a CDF of continuous distribution and then, for any \(\epsilon >0\) there exists \(-\infty =t_0<t_1<\cdots <t_k=\infty \) such that for \(0\le j\le k-1\), \(H_x(t_{j+1}) - H_x(t_j)\le \frac{\epsilon }{2}\). Moreover, since \(f(x, \xi )\) is integrable and continuous w.r.t. x, by Lebesgue’s dominated convergence theorem, for any continuous and bounded function h,
Then \(f(x, \cdot )\) converges to \(f(x_N, \cdot )\) weakly, which is equivalent to \(\lim _{N\rightarrow \infty }|H_{x_N}(t) - H_{x}(t)|=0\) for any \(t\in {\mathbb {R}}\). Then there exists sufficiently large N such that \(\sup _{j\in \{0, \ldots , k\}}|H_{x_N}(t_j) - H_x(t_j)|\le \frac{\epsilon }{4}\). Then we have
\(\square \)
Theorem 3
Suppose \(f(x, \xi )\) is Lipschitz continuous w.r.t. x and \(\xi \), and the Lipschitz modules \(\kappa (\xi )\) of \(f(\cdot , \xi )\) is integrable, \(f(x, \cdot )\in {{\mathcal {L}}}_P(\Xi , {{\mathcal {F}}}, {\mathbb {P}})\) and \({\mathbb {P}}\) is a continuous distribution. Then w.p.1
and \((H^N_{x_N})^{-1}\) converges w.p.1 to \(H_{x}^{-1}\) in the norm topology of \({{\mathcal {L}}}_p\) as \(N\rightarrow \infty \).
Proof
Note that
It is sufficient to show that for any \(\epsilon >0\),
and
We consider (A8) firstly. By Lemma 3, there exists \(-\infty =t_0<t_1<\cdots <t_k=\infty \) such that for \(0\le j\le k-1\), \(H_{x_N}(t_{j+1}) - H_{x_N}(t_j)\le \frac{\epsilon }{2}\) for all n sufficiently large. For any t, there exists j such that \(t_j\le t \le t_{j+1}\). For such j,
which implies
Then we have
and
Note that by Lemma 3 and by uniform law of large numbers [27, Theorem 7.48], \(H_{x_N}(t_{j+1}) - H_{x_N}(t_j)\le \frac{\epsilon }{2}\) and \(|H^N_{x_N}(t_{j+1}) - H_{x_N}(t_j)|\le \frac{\epsilon }{4}\) for all N sufficiently large and \(j=0, \ldots , k\), then we have (A8). Now we consider (A9). Similar as the procedure above, For any t, there exists j such that \(t_j\le t \le t_{j+1}\). For such j,
Then by continuous distribution of \({\mathbb {P}}\), Lipschitz continuity of \(f(x, \xi )\) w.r.t. x and Lemma 3, for any \(t\in {\mathbb {R}}\),
Combining (A8) and (A9), we have (A7).
Moreover, (A7) implies that \((H^N_{x_N})^{-1}\) pointwise converges to \(H^{-1}_{x}\) on the set [0, 1]. Then, if the sequence \(\{|(H^N_{x_N})^{-1}(s) - H^{-1}_{x}(s)|^p\}\) is uniformly integrable, \((H^N_{x_N})^{-1}\) converges w.p.1 to \(H_{x}^{-1}\) in the norm topology of \({{\mathcal {L}}}_p\) as \(N\rightarrow \infty \), that is w.p.1
where the first equality comes from the Lebesgue’s dominated convergence theorem.
Let us show that the uniform integrability indeed holds. By triangle inequality,
Then we only need to show the uniform integrability of \( |(H^N_{x_N})^{-1}(s)|^p \). Note that
Since the Lipschitz continuity of \(f(x, \xi )\) with Lipschitz modules \(\kappa (\xi )\),
Moreover, by the law of large numbers and \(x_N\rightarrow x\), \(\frac{1}{N}\sum _{i=1}^N\kappa (\xi )\rightarrow {\mathbb {E}}_{\mathbb {P}}[\kappa (\xi )]\), \(|\frac{1}{N}\sum _{i=1}^N\kappa (\xi )(x-x_N) |^p\rightarrow 0\) and \( |\frac{1}{N}\sum _{i=1}^N|f(x, \xi ^i)|^p - {\mathbb {E}}_{\mathbb {P}}[|f(x, \xi )|^p]|\rightarrow 0\) as \(N\rightarrow \infty \) w.p.1. It follows that \( |(H^N_{x_N})^{-1}(s)|^p \) converges w.p.1 to a finite limit, which implies that w.p.1 \( |(H^N_{x_N})^{-1}(s)|^p \) is uniformly integrable. \(\square \)
Proof of Proposition 4
For any continuous and bounded function \(g:\Xi \rightarrow {\mathbb {R}}\), we have that
where \({\bar{\mu }}\) is corresponding to \({\bar{\sigma }}\). Moreover,
Then
We first prove
as \(N\rightarrow \infty \). From condition (iii), \(g(\xi )\) is continuous and bounded and \(\phi ^{{\bar{x}}}(\xi )\) is continuous w.r.t. \(\xi \). Then for any \(\alpha '\rightarrow \alpha \), \(\alpha ', \alpha \in [0, 1)\), we have
where \(A_\alpha = \{\xi : \phi ^{{\bar{x}}}(\xi )>\kappa _\alpha \}\) and \(A_{\alpha '} = \{\xi : \phi ^{{\bar{x}}}(\xi )>\kappa _{\alpha '}\}\). Note that \(a'\rightarrow a\) and the CDF of \(\phi ^{{\bar{x}}}\) is strictly monotone, \(A_{\alpha '}\rightarrow A_\alpha \) and \({\mathbb {P}}((A_{\alpha '} - A_\alpha )\cup (A_{\alpha } - A_{\alpha '}))\rightarrow 0\). Then we have that \(\frac{1}{1-\alpha }\int _{\phi ^{{\bar{x}}}(\xi )>\kappa _\alpha } g(s)d{\mathbb {P}}(s)\) is continuous and bounded w.r.t. \(\alpha \), and (11) is from the fact that \(\mu _N\) weak* converges to \(\mu \). Indeed, by Lemma 2, \(\sigma _N\) weak* converges to \({\bar{\sigma }}\), then for any continuous and bounded function g(t), \(\int _{[0,1)}g(t)\sigma _N(t)dt\rightarrow \int _{[0,1)}g(t){\bar{\sigma }}(t)dt\) as \(N\rightarrow \infty \). Note that \(\mu (\alpha ) = (1-\alpha )\sigma (\alpha ) + \int _{0}^\alpha \sigma (t)dt\). Then
as \(N\rightarrow \infty \), which implies that \(\mu _N\) weak* converges to \({\bar{\mu }}\).
Then we prove
Note that \(\phi ^{{\bar{x}}}(\xi )\) is Lipschitz continuous w.r.t. x, the given g is continuous and bounded function w.r.t. \(\xi \) and \(\{\xi ^j\}_{j=1}^N\) is i.i.d. samples from \({\mathbb {P}}\), both \(\frac{1}{(1-\alpha ) N}\sum _{\phi ^{x_N}(\xi ^j)>\kappa ^\alpha _{N,x_N}} g(\xi ^j)\) and \(\frac{1}{1-\alpha }\int _{\phi ^{{\bar{x}}}(\xi )>\kappa _\alpha } g(s)d{\mathbb {P}}(s)\) are bounded by \(\max _{s\in [0,1]} g(s)\) and by Proposition 6
We then have
where the second inequality is from condition (iii) and the third equality is from Lebesgue’s dominated convergence theorem.
Combining the above analysis, we have (A10), that is \(P^{x_N}_{N}\) converges weakly to \(P^{{\bar{x}}}\). \(\square \)
Proof of Theorem 2
By conditions (c)–(e),
Then we only need to prove that \({\bar{x}}\) is a solution of (22), which is equivalent to
Since \({\hat{x}}_N\rightarrow {\bar{x}}\),
Moreover,
Note that since \(P_N^{{\hat{x}}_N} \rightarrow P^{{\bar{x}}}\) weakly and by Assumption 3 (b), \(P_N^{{\hat{x}}_N} \rightarrow P^{{\bar{x}}}\) under Kantorovich metric [23]. Then by condition (b), we have for any N, \(\varPhi ({\hat{x}}_N, \cdot )\) is Lipschitz continuous and
where \({\bar{Z}}:=\{{\hat{x}}_N, N=1, 2, \cdots \}\). Moreover,
Combining (A14)–(A15), we have
Rights and permissions
Springer Nature or its licensor holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Sun, H., Shapiro, A. & Chen, X. Distributionally robust stochastic variational inequalities. Math. Program. 200, 279–317 (2023). https://doi.org/10.1007/s10107-022-01889-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10107-022-01889-2
Keywords
- Distributional robustness
- Variational inequalities
- Monotonicity
- Sample average approximation
- Stochastic games