
Abstract
Providing a timely output is one of the important criteria in applications of time series classification. Recent studies have been motivated to explore models of early prediction, prediction based on truncated temporal observations. The truncation of input improves the response time, but generally reduces the reliability of the prediction. The trade-off between the earliness and the accuracy is an inherent challenge of learning an early prediction model. In this paper, we present an optimization-based approach for learning an ensemble model for timely prediction with an intuitive objective function. The proposed model is comprised of time series classifiers with different response time, and a sequential aggregation procedure to determine the single timing of its output. We formalize the training of the ensemble classifier as a quadratic programming problem and present an iterative algorithm which minimizes an empirical risk function and the response time required to achieve the minimal risk simultaneously. We conduct an empirical study using a collection of behavior and time series datasets to evaluate the proposed algorithm. In the comparisons of the traditional and time-sensitive performance measures, the ensemble framework showed significant advantages over the existing methods on early prediction.






Similar content being viewed by others

Notes
The codes and the instructions for generating the above datasets are provided at http://www.rs.tus.ac.jp/ando/expdat_sdm13.html.
References
Anderson H, Parrish N, Tsukida K, Gupta M (2012) Reliable early classification of time series. In: IEEE international conference on Acoustics, speech and signal processing (ICASSP), pp 2073–2076
Ando S, Suzuki E (2011) Role-behavior analysis from trajectory data by cross-domain learning. In: Proceedings of the 2011 IEEE 11th international conference on data mining, ICDM ’11, pp 21–30
Ando S, Suzuki E (2013) Time-sensitive classification of behavioral data. In: Proceedings of the 13th SIAM international conference on data mining, pp 458–466
Ando S, Thanomphongphan T, Hoshino D, Seki Y, Suzuki E (2011) ACE: anomaly clustering ensemble for multi-perspective anomaly detection in robot behaviors. In: Proceedings of the tenth SIAM international conference on data mining, pp 1–12
Ando S, Thanomphongphan T, Seki Y, Suzuki E (2013) Ensemble anomaly detection from multi-resolution trajectory features. Data Min Knowl Discov 29:39–84
Bache K, Lichman M (2013) UCI machine learning repository. http://archive.ics.uci.edu/ml
Bartlett PL, Wegkamp MH (2008) Classification with a reject option using a hinge loss. J Mach Learn Res 9:1823–1840
Buza K, Nanopoulos A, Schmidt-Thieme L (2011) INSIGHT: efficient and effective instance selection for time-series classification. In: Proceedings of the 15th Pacific-Asia conference on advances in knowledge discovery and data mining, volume part II, PAKDD’11. Springer, Berlin, pp 149–160
Boyd S, Vandenberghe L (2004) Convex optimization. Berichte über verteilte messysteme. Cambridge University Press, Cambridge
Buza K, Nanopoulos A, Schmidt-Thieme L (2011) IQ estimation for accurate time-series classification. In: IEEE symposium on computational intelligence and data mining (CIDM), pp 216–223
Cao L, Yu PS (2012) Behavior computing: modeling, analysis, mining and decision. Springer, Berlin
Du J, Ni EA, Ling CX (2010) Adapting cost-sensitive learning for reject option. In: Proceedings of the 19th ACM international conference on information and knowledge management, CIKM ’10, pp 1865–1868
Elkan C (2001) The foundations of cost-sensitive learning. In: Proceedings of the 17th international joint conference on artificial intelligence, vol 2, pp 973–978
Forsgren A, Gill P, Wright M (2002) Interior methods for nonlinear optimization. SIAM Rev 44(4):525–597
Freund Y, Schapire RE (1997) A decision-theoretic generalization of on-line learning and an application to boosting. J Comput Syst Sci 55(1):119–139
Ghalwash M, Obradovic Z (2012) Early classification of multivariate temporal observations by extraction of interpretable shapelets. BMC Bioinform 13:1–12
Hanczar B, Dougherty ER (2008) Classification with reject option in gene expression data. Bioinformatics 24(17):1889–1895
Hatami N, Chira C (2013) Classifiers with a reject option for early time-series classification. In: IEEE symposium on computational intelligence and ensemble learning (CIEL), pp 9–16
Hoai M (2012) Max-margin early event detectors. In: Proceedings of the 2012 IEEE conference on computer vision and pattern recognition (CVPR), CVPR ’12, pp 2863–2870
Joachims T, Finley T, Yu CNJ (2009) Cutting-plane training of structural SVMs. Mach Learn 77:27–59
Kaluz̆a B, Mirchevska V, Dovgan E, Lus̆trek M, Gams M (2010) An agent-based approach to care in independent living. In: de Ruyter B, Wichert R, Keyson D, Markopoulos P, Streitz N, Divitini M, Georgantas N, Mana Gomez A (eds) Ambient intelligence, Lecture Notes in Computer Science, vol 6439. Springer, Berlin, pp 177–186
Kelley JE Jr (1960) The cutting-plane method for solving convex programs. J Soc Ind Appl Math 8(4):703–712
Kouno A, Takano S, Suzuki E (2010) Constructing low-cost swarm robots that march in column formation. In: Proceedings of the 7th international conference on swarm intelligence, ANTS’10, pp 556–557
Kumar S, Nguyen HT, Suzuki E (2010) Understanding the behaviour of reactive robots in a patrol task by analysing their trajectories. In: Proceedings of the 2010 IEEE/WIC/ACM international conference on web intelligence and intelligent agent technology, vol 02, WI-IAT ’10, pp 56–63
Liu H, Motoda H (2002) On issues of instance selection. Data Min Knowl Discov 6(2):115–130
Mehrotra S (1992) On the implementation of a primal-dual interior point method. SIAM J Optim 2(4):575–601
Mori A, Uchida S, Kurazume R, Taniguchi R, Hasegawa T, Sakoe H (2006) Early recognition and prediction of gestures. In: Proceedings of the 18th international conference on pattern recognition, vol 03, ICPR ’06, pp 560–563
Pham DT, Chan AB (1998) Control chart pattern recognition using a new type of self-organizing neural network. Proc Inst Mech Eng I J Syst Control Eng 212(2):115–127
Reinartz T (2002) A unifying view on instance selection. Data Min Knowl Discov 6(2):191–210
Roddick JF, Spiliopoulou M (2002) A survey of temporal knowledge discovery paradigms and methods. IEEE Trans Knowl Data Eng 14(4):750–767
Saito N (1994) Local feature extraction and its applications using a library of bases. Ph.D. thesis, Yale University, New Haven, CT, USA
Salvador S, Chan P (2007) Toward accurate dynamic time warping in linear time and space. Intell Data Anal 11(5):561–580
Serrà J, Arcos JL (2014) An empirical evaluation of similarity measures for time series classification. Knowl Based Syst 67:305–314
Sheng VS, Ling CX (2006) Thresholding for making classifiers cost-sensitive. In: Proceedings of the 21st national conference on artificial intelligence, AAAI’06, vol 1, pp 476–481
Tsochantaridis I, Joachims T, Hofmann T, Altun Y (2005) Large margin methods for structured and interdependent output variables. J Mach Learn Res 6:1453–1484
Uchida S, Amamoto K (2008) Early recognition of sequential patterns by classifier combination. In: Proceedings of the 19th international conference on pattern recognition (ICPR’08), pp 1–4
Wang X, Mueen A, Ding H, Trajcevski G, Scheuermann P, Keogh E (2013) Experimental comparison of representation methods and distance measures for time series data. Data Min Knowl Discov 26(2):275–309
Xi X, Keogh E, Shelton C, Wei L, Ratanamahatana CA (2006) Fast time series classification using numerosity reduction. In: Proceedings of the 23rd international conference on machine learning, ICML ’06, pp 1033–1040
Xing Z, Pei J, Dong G, Yu PS (2008) Mining sequence classifiers for early prediction. In: Proceedings of the SIAM international conference on data mining, SDM 2008, pp 644–655
Xing Z, Pei J, Keogh E (2010) A brief survey on sequence classification. SIGKDD Explor Newsl 12:40–48
Xing Z, Pei J, Yu P (2012) Early classification on time series. Knowl Inf Syst 31(1):105–127
Xing Z, Pei J, Yu P, Wang K (2011) Extracting interpretable features for early classification on time series. In: Proceedings of the 11th SIAM international conference on data mining (SDM11), pp 247–258
Xing Z, Pei J, Yu PS (2009) Early prediction on time series: a nearest neighbor approach. In: Proceedings of the 21st international joint conference on artificial intelligence, pp 1297–1302
Yuan M, Wegkamp M (2010) Classification methods with reject option based on convex risk minimization. J Mach Learn Res 11:111–130
Acknowledgments
The authors would like to thank the handling editor and the anonymous reviewers for their valuable and insightful comments. Parts of this study are supported by the Strategic International Cooperative Program funded by Japan Science and Technology Agency and the Grant-in-Aid for Scientific Research on Fundamental Research (B) 21300053, (B) 25280085, and (C) 25730127 by the Japanese Ministry of Education, Culture, Sports, Science, and Technology.
Author information
Authors and Affiliations
Corresponding author
Additional information
A portion of this paper has been published in 2013 in Proceedings of the 13th SIAM International Data Mining Conference (Ref. [3]).
Appendices
Appendix 1: Proofs of theorems
1.1 Proof of Theorem 1
Proof
For any given \(\varTheta \), the smallest sum of \(\xi _{t,k}\) gives the largest violation among all \(Z\in \mathbf {Z}\). That is,
Since the largest \(V(Z,\varTheta )\) is given by the optimal solution, Problem 4 can be viewed as an optimization problem for the loss \(V(Z,\varTheta )\), regularized by the sum of the scaled margins.
Given that \(\mathbf {w}^*\) is fixed, \(\xi _{t,k}\) can be minimized individually.
When \(\mathbf {v}_k(t)\) is correctly classified, \(\xi _{t,k}\) reduces to 0. It is, thus, constrained by (17) that \(z_{j,t}\) is 0 for all \(j>k\), ensuring that the solution \(Z^*\) is feasible.
1.2 Proof of Theorem 2
Proof
For every \(\mathbf {w}\), the smallest feasible \(\xi \) for Problem 3 is the maximum violation over \(\mathbf {Z}\). That is,
At fixed \(\mathbf {w}\) and \(\varTheta \), the summation in (21) can be taken individually for each \(k\), that is,
It follows that for any \(\mathbf {w}=(\mathbf {w}_1,\ldots ,\mathbf {w}_\lambda )\), the objective values of Problems 3 and 5 are equivalent with the optimal \(\xi \) and \(\{\xi _k\}_{k=1}^\lambda \). Subsequently, their minima are equivalent as well.
1.3 Proof of Theorem 3
Proof
Problem 4 maximizes \(V(Z,\varTheta )\) and subsequently its first term in (14),
From (13), \(\xi '\) is the minimum slack needed to satisfy all constraints of Problem 3 for the tentative \(\mathbf {w}\). Upon the convergence of \(V(Z,\varTheta )\), \(\mathbf {w}\) is, therefore, the optimal solution of Problem 3 for the tentative \(\varTheta \). If \((Z,\varTheta )\) is locally optimal for the tentative \(\mathbf {w}\), the solution to Problem 4 is identical to \(Z\) in the integer domain.
For the objective to improve in each iteration, it suffices that the constraint corresponding to the newly added \(Z\) is violated by the tentative solution and satisfied by the desired solution. In Problem 4, (17) constrains \(z_{t,k}\) to 0 when the margin for \(\mathbf {v}_k(t)\) is above the threshold. Conversely, among the elements of \(Z\), only those corresponding to incorrectly classified instances take nonzero values. When substituting such \(Z\) into (13), the left-hand side of the inequality becomes the average margin for such instances and violates the tentative upper-bound. Meanwhile, the solution which gives the correct prediction at earliest possible timing can trivially satisfy (13).
Appendix 2: Adopted optimization procedures
This section describes the optimization procedures we adopted from existing algorithms for addressing subproblems in the proposed method.
Problem 5 is a quadratic programming problem for training a linear SVM. In our experiment, we adopted the algorithm from [20] and used an implementation described in Algorithm 3.
Next, we describe the outline of the Interior Point Method we implemented for solving Problem 4. First, Problem 4 is reformulated into a centering problem of the following form.
where variable \(X\) represents the parameters and \(f\) is the objective function of Problem 4, i.e.,


while \(g\) and \(h\) are barrier functions converted from the inequality constraints (16) and (17), respectively.
The first term in (22), \(pf(X)\) can be interpreted as the potential of a force field \(F(X)=-t\nabla {f}(X)\), and similarly, \(-\log (-g_{t,k}(X))\) and \(-\log (-h_j(X))\) the potentials of force fields \(G_{t,k}(X)=\frac{1}{g(X)}\nabla {g}(X)\) and \(H_{j}(X)=\frac{1}{h(X)}\nabla {h}(X)\), respectively.
Let \(X_p^*\) denote the solution of the centering problem for a given \(p\). The forces are balanced at \(X_p^*\) such that
The barrier method in the following procedure approaches the minimum of the original problem by moving along the balancing center of the force fields by iteratively updating \(t\) [9].
Appendix 3: Baseline methods
1.1 Early Classification of Time Series
The state-of-the-art ECTS method [41] is an extension of the nearest neighbor algorithm which constructs the nearest neighbor rules using the prefix, i.e., the truncated segments, of the time series. The prefix of a test instance is classified using the prefixes of the training instances of the same lengths.
ECTS has a set of parameters called the minimum prediction lengths (MPL), assigned to each training instance. The MPL adds a restriction on the nearest neighbor rule regarding the number of observed points so as to avoid premature errors. The restriction is that a prefix of a test instance can be classified only when the \(MPL\) of the nearest training instance is smaller than its length. The MPL of each training instance is determined by testing a condition of consistency of called serial on the class clusters in the single-linkage clustering of training data.
ECTS can be directly applied to the early window classification problem which is the special case of the early prediction problem. The prediction window of ECTS is naturally given by the smallest prediction window in \(\fancyscript{L}\) that is larger than \(MPL\). ECTS is subject to overfitting to noise due to its dependence on the nearest neighbor rule, as noted in [41]. It has a parameter \(MinSup\) which can be adjusted to control overfitting, and \(MinSup=0\) is suggested when there is no risk. In our empirical study, we presumed the risk of overfitting and tested the values \(\{5,10,20\}\) for \(MinSup\). The performances were similar among these values.
1.2 Empirical thresholding
Empirical Thresholding [34] is a meta-learning framework for cost-sensitive classification. ET combines an existing classifier with an empirically learned threshold parameter to make a prediction.
ET uses the scores of an external classifier to make a meta-prediction with the minimal cost given the classifier. It is assumed that the problem is a binary classification and the output of the classifier is the numerical score which reflects the likelihood that each instance is assigned to the positive class. The training of a ET model requires a training set and a validation set. The classifier is trained with the training data, the scores over the validation data are computed, and a threshold for minimizing the cost is chosen. To select \(\theta \) for an ensemble of classifiers, it requires a combinatorial search of an exponential order.
In order to train a classifier \(f\) and a corresponding threshold \(\theta \), ET conducts a \(p\)-fold cross-validation using the training data. The training data are divided into \(p\) pairs of training and validation sets. \(f\) is learned from each training set, the cost is evaluated over the validation set with all candidates of \(\theta \), and those achieving the least cost are chosen.
For our empirical study, we construct an ensemble of classifiers for early window classification using ET. A set of classifiers \(\{f_k\}_{k=1}^\lambda \) are trained individually, and a threshold \(\theta _k\) is chosen for each \(k\). Choosing a combination of \(k\) thresholds by cross-validation is infeasible as the order of the grid search is exponential. Alternatively, we implemented ET to choose one threshold in a step in the ascending order of the prediction window \(\ell _k\). At step \(k\), one chooses \(\theta _k\) while the values of \(\{\theta _{k'}:k'<k\}\) are fixed to those chosen in prior steps. \(\{\theta _{k'}:k'<k\}\) are fixed to the values such that their predictions are reserved for all instances. In our empirical study in Sect. 5.6, the error rate is employed as the cost when evaluating the standard performance measures, and AER is used as the cost when evaluating the adjusted measures.
Appendix 4: Performance measure comparisons
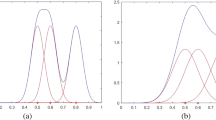
Figure 7 illustrates the error, rejection, and adjusted error rates of GET, which were excluded from Fig. 7a, b in Sect. 5.7. The rejection rate is much smaller, and the error and adjusted error rates are on a significantly larger scale than the other two.

Performance measure comparisons with GET. a Control Chart, b CBF
Rights and permissions
About this article

Cite this article
Ando, S., Suzuki, E. Minimizing response time in time series classification. Knowl Inf Syst 46, 449–476 (2016). https://doi.org/10.1007/s10115-015-0826-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10115-015-0826-7