
Abstract
Semantic textual similarity (\(\mathcal {STS}\)) seeks to assess the degree of semantic equivalence between two sentences or snippets of texts. Most methods of \(\mathcal {STS}\) are based on word surface and deem words as meaning unrelated symbols, which makes these methods indiscriminative for ubiquitous conceptual association among words. Recently, concept transferred space (CTS) is proposed to solve word conceptual association problem. It is generated from the noun concepts with their IS-A relations in WordNet. However, the CTS-based model can only calculate nouns; as a result, a large number of words, i.e., verbs, adjectives, adverbs as well as out-of-vocabulary named entities (OOV NEs), are neglected, thus resulting in information loss in the semantic similarity evaluation. This paper presents ways to solve this problem: To involve words other than nouns, derivational links in WordNet are employed to associate verbs, adjectives, and adverbs with their corresponding noun concepts; to prevent information loss by OOV NEs, the increased quantity of information of them is predicted according to the tendency learned from known NEs. Moreover, to further improve the accuracy of the CTS-based model, we take the importance of different types of words into consideration by assigning corresponding weights for them. Experimental results suggest that the proposed comprehensive CTS-based model achieves significant improvement compared with the primitive one without the non-nominal words, OOV NEs, and word weights and also outperforms all the yearly state-of-the-art systems at the *SEM/SemEval 2013–2016 \(\mathcal {STS}\) tasks. Additionally, at the SemEval 2017 \(\mathcal {STS}\) task, our team with the comprehensive CTS-based model ranked the second and the first among all teams and on Track 1 dataset, respectively.



Similar content being viewed by others


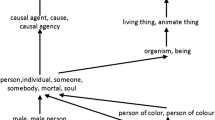
Notes
The tool is available at https://stanfordnlp.github.io/CoreNLP/.
The aligner is available at: https://github.com/ma-sultan/monolingual-word-aligner.
References
Agirre E, Banea C, Cardie C, Cer DM, Diab MT, Gonzalez-Agirre A, Guo W, Lopez-Gazpio I, Maritxalar M, Mihalcea R, Rigau G, Uria L, Wiebe J (2015) SemEval-2015 task 2: semantic textual similarity, English, Spanish and pilot on interpretability. In: Proceedings of the 9th international workshop on semantic evaluation, SemEval@NAACL-HLT 2015, Denver, Colorado, USA, pp 252–263
Agirre E, Banea C, Cardie C, Cer DM, Diab MT, Gonzalez-Agirre A, Guo W, Mihalcea R, Rigau G, Wiebe J (2014) SemEval-2014 task 10: multilingual semantic textual similarity. In: Proceedings of the 8th international workshop on semantic evaluation, SemEval@COLING 2014, Dublin, Ireland, pp 81–91
Agirre E, Banea C, Cer DM, Diab MT, Gonzalez-Agirre A, Mihalcea R, Rigau G, Wiebe J (2016) SemEval-2016 task 1: semantic textual similarity, monolingual and cross-lingual evaluation, In: Proceedings of the 10th international workshop on semantic evaluation, SemEval@NAACL-HLT 2016, San Diego, CA, USA, pp 497–511
Agirre E, Cer D, Diab M, Gonzalez-Agirre A, Guo W (2013) SemEval-2013 shared task: semantic textual similarity, including a pilot on typed-similarity. In: Proceedings of the second joint conference on lexical and computational semantics
Agirre E, Cer DM, Diab MT, Gonzalez-Agirre A (2012) SemEval-2012 task 6: a pilot on semantic textual similarity. In: Proceedings of the 6th international workshop on semantic evaluation, SemEval@NAACL-HLT 2012, Montréal, Canada, pp 385–393
Bär D, Biemann C, Gurevych I, Zesch T (2012) UKP: computing semantic textual similarity by combining multiple content similarity measures. In: Proceedings of the 6th international workshop on semantic evaluation, SemEval@NAACL-HLT 2012, Montréal, Canada, pp 435–440
Bird S (2006) NLTK: the natural language toolkit. In: Proceedings of the 21st international conference on computational linguistics and the 44th annual meeting of the association for computational linguistics, Sydney, Australia
Brychcín T, Svoboda L ( 2016) UWB at SemEval-2016 task 1: semantic textual similarity using lexical, syntactic, and semantic information. In: Proceedings of the 10th international workshop on semantic evaluation, SemEval@NAACL-HLT, San Diego, CA, USA, pp 588–594
Cer D, Diab M, Agirre E, Lopez-Gazpio I, Specia L (2017) SemEval-2017 task 1: semantic textual similarity multilingual and crosslingual focused evaluation. In: Proceedings of the 11th international workshop on semantic evaluation (SemEval-2017), Association for Computational Linguistics, pp 1–14
Fellbaum C (1998) Wordnet: an electronic lexical database. MIT Press, Cambridge
Ganitkevitch J, Van Durme B, Callison-Burch C (2013) PPDB: the paraphrase database. In: Conference of the North American chapter of the Association for Computational Linguistics, pp 758–764
Han L, Kashyap AL, Finin T, Mayfield J, Weese J (2013) UMBC\(_{-}\)EBIQUITY-CORE: semantic textual similarity systems. In: Proceedings of the second joint conference on lexical and computational semantics, pp 44–52
He H, Wieting J, Gimpel K, Rao J, Lin JJ (2016) UMD-TTIC-UW at SemEval-2016 task 1: attention-based multi-perspective convolutional neural networks for textual similarity measurement. In: Proceedings of the 10th international workshop on semantic evaluation, SemEval@NAACL-HLT 2016, San Diego, CA, USA, pp 1103–1108
Hill F, Cho K, Korhonen A (2016) Learning distributed representations of sentences from unlabelled data. In: NAACL HLT 2016, the 2016 conference of the North American chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego California, USA, June 12–17, 2016, pp 1367–1377
Islam A, Inkpen D (2008) Semantic text similarity using corpus-based word similarity and string similarity. ACM Trans Knowl Discov Data 2(2):10
Jiang JJ, Conrath DW (1997) Semantic similarity based on corpus statistics and lexical taxonomy. In: Proceedings of international conference research on computational linguistics
Jiménez S, Becerra CJ, Gelbukh AF (2012) Soft cardinality: a parameterized similarity function for text comparison. In: Proceedings of the 6th international workshop on semantic evaluation, pp 449–453
Le QV, Mikolov T (2014) Distributed representations of sentences and documents. In: Proceedings of the 31th international conference on machine learning, Beijing, China, pp 1188–1196
Li Y, McLean D, Bandar ZA, O’shea JD, Crockett K (2006) Sentence similarity based on semantic nets and corpus statistics. IEEE Trans Knowl Data Eng 18(8):1138–1150
Lin D (1997) Using syntactic dependency as local context to resolve word sense ambiguity. In: Proceedings of the 35th annual meeting of the Association for Computational Linguistics and eighth conference of the European chapter of the Association for Computational Linguistics, pp 64–71
Manning CD, Surdeanu M, Bauer J, Finkel JR, Bethard S, McClosky D (2014) The Stanford CoreNLP natural language processing toolkit. In: Proceedings of the 52nd annual meeting of the Association for Computational Linguistics, Baltimore, MD, USA, System Demonstrations, pp 55–60
Mihalcea R, Corley C, Strapparava C (2006) Corpus-based and knowledge-based measures of text semantic similarity. In: Proceedings of the twenty-first national conference on artificial intelligence and the eighteenth innovative applications of artificial intelligence conference, Boston, Massachusetts, USA, pp 775–780
Mikolov T, Chen K, Corrado G, Dean J (2013) Efficient estimation of word representations in vector space. CoRR. arXiv:1301.3781
Miller GA (1995) WordNet: a lexical database for English. Commun ACM 38(11):39–41
Oliva J, Serrano JI, del Castillo MD, Iglesias Á (2011) SyMSS: a syntax-based measure for short-text semantic similarity. Data Knowl Eng 70(4):390–405
Pagliardini M, Gupta P, Jaggi M (2017) Unsupervised learning of sentence embeddings using compositional n-gram features. CoRR. arXiv:1703.02507
Papineni K, Roukos S, Ward T, Zhu W (2002) BLEU: a method for automatic evaluation of machine translation. In: Proceedings of the 40th annual meeting on association for computational linguistics, pp 311–318
Plag I (2003) Word-formation in English. Cambridge University Press, Cambridge
Rada R, Mili H, Bicknell E, Blettner M (1989) Development and application of a metric on semantic nets. IEEE Trans Syst Man Cybern 19(1):17–30
Ravichandran D, Hovy EH (2002) Learning surface text patterns for a question answering system. In: Proceedings of the 40th annual meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, pp 41–47
Resnik P (1995) Using information content to evaluate semantic similarity in a taxonomy. In: Proceedings of the fourteenth international joint conference on artificial intelligence, Montréal Québec, Canada, pp 448–453
Rychalska B, Pakulska K, Chodorowska K, Walczak W, Andruszkiewicz P (2016) Samsung Poland NLP team at SemEval-2016 task 1: necessity for diversity; combining recursive autoencoders, wordnet and ensemble methods to measure semantic similarity. In: Proceedings of the 10th international workshop on semantic evaluation, SemEval@NAACL-HLT 2016, San Diego, CA, USA, pp 602–608
Salton G, Lesk ME (1968) Computer evaluation of indexing and text processing. J ACM 15(1):8–36
Saric F, Glavas G, Karan M, Snajder J, Basic BD (2012) TakeLab: systems for measuring semantic text similarity. In: Proceedings of the 6th international workshop on semantic evaluation, SemEval@NAACL-HLT 2012, Montréal, Canada, pp 441–448
Sultan MA, Bethard S, Sumner T (2014) Back to basics for monolingual alignment: exploiting word similarity and contextual evidence. Trans Assoc Comput Linguist 2:219–230
Sultan MA, Bethard S, Sumner T (2014), DLS@CU: sentence similarity from word alignment. In: Proceedings of the 8th international workshop on semantic evaluation, SemEval@COLING 2014, Dublin, Ireland, pp 241–246
Sultan MA, Bethard S, Sumner T (2015) DLS@CU: sentence similarity from word alignment and semantic vector composition. In: Proceedings of the 9th international workshop on semantic evaluation, SemEval@NAACL-HLT 2015, Denver, Colorado, USA, pp 148–153
Sun L, Guo C, Liu C, Xiong H (2017) Fast affinity propagation clustering based on incomplete similarity matrix. Knowl Inf Syst 51(3):941–963
Wieting J, Bansal M, Gimpel K, Livescu K (2015) Towards universal paraphrastic sentence embeddings. CoRR. arXiv:1511.08198
Wu H, Huang H (2016) Sentence similarity computational model based on information content. IEICE Trans Inf Syst 99(6):1645–1652
Wu H, Huang H (2017) Efficient algorithm for sentence information content computing in semantic hierarchical network. IEICE Trans Inf Syst 100(1):238–241
Yarowsky D (1995) Unsupervised word sense disambiguation rivaling supervised methods. In: Proceedings of the 33rd annual meeting of the Association for Computational Linguistics, MIT, Cambridge, Massachusetts, USA, pp 189–196
Yu H, Hsieh C, Si S, Dhillon IS (2014) Parallel matrix factorization for recommender systems. Knowl Inf Syst 41(3):793–819
Acknowledgements
The work described in this paper was mainly supported by State Program of National Natural Science Foundation of China under Grant 61751201 and Beijing Advanced Innovation Center for Imaging Technology under Grant BAICIT-2016007. The authors would like to thank the editor and the anonymous reviewers for their insightful comments to the improvement in technical contents and paper presentation.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Huang, H., Wu, H., Wei, X. et al. Mapping sentences to concept transferred space for semantic textual similarity. Knowl Inf Syst 60, 1353–1376 (2019). https://doi.org/10.1007/s10115-018-1261-3
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10115-018-1261-3