
Abstract
In an era where cybersecurity threats are evolving at an unprecedented pace, this paper introduces a methodology for near real-time risk assessment of high-profile, high security infrastructures, where data security and operational continuity inherently limits observability. Our approach addresses the challenges of this limited observability and minimized disruption, offering a new perspective on processing and evaluating cybersecurity knowledge. We present an innovative method that leverages attack graphs and attacker behavior analysis to assess risks and vulnerabilities. Our research includes the development of an automated risk assessment mechanism, graphical security modeling, and a Markov chain-based model for attacker behavior. Our methodology utilizes a blend of direct and indirect event sources, incorporating an attacker behavioral model based on a random walk method akin to Google’s PageRank. The proof-of-concept solution calculates potential risk according to the actual threat landscape, providing a more accurate and timely assessment.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The scope and nature of potential cybersecurity threats that an individual, an organization, or a system might face is commonly known as the threat landscape. It involves a wide range of potential risks, including cyber threats such as malware, phishing attacks, ransomware, data breaches, and other malicious activities that could compromise the security and integrity of computer systems, networks, and sensitive information. The threat landscape continuously and dynamically evolves as cyber attackers develop new methods and techniques. Understanding the threat landscape is crucial for cybersecurity professionals and organizations to implement effective security measures, stay informed about potential threats, and proactively protect against existing and evolving vulnerabilities. Analyzing the threat landscape helps develop strategies to mitigate risks and respond to security incidents.
Risk assessment is the process of identifying, analyzing, and evaluating potential risks and vulnerabilities that could impact an organization’s infrastructure, assets, and data. The goal is to assess the likelihood and the impact of the risks. Real-time risk assessment has several advantages. First, it allows for proactive threat detection. If potential threats can be identified before—or as they occur, or before they are fully manifested—it not only allows professionals to take immediate action that can mitigate the threat, but also facilitates a faster response time that can minimize the damage in the event of a security breach or infrastructure failure. Second, it can also help identify potential problems that could lead to downtime and damage the company’s reputation. Third, it can improve the security posture of an infrastructure, as identifying and mitigating potential risks keeps the network resilient to evolving attack vectors (surfaces).
Information systems are often evolving in the course of several decades with involvement of several independent architects, integrators and operators. Although it is generally formally required, overall documentation of the system architecture is often not well maintained or even missing in many cases. This is true especially for systems that are maintained in a distributed or federative model of custody.
Knowledge of the broad architecture plays an even more important role in extensive risk analysis and risk mitigation efforts.
The complete discovery of system architecture also depends on availability of deployment information such as run-time configuration of various system components. From the perspective of a production system, the described situation can be labelled as a “white box” approach presuming high privilege access to major system components with availability of configuration settings and optionally even source code. Besides having a potentially high impact on the investigated infrastructure, this level of observability is often not attainable due to various factors such as missing or confidential information, conflict of interests amongst different independent actors or prohibitive policies.
As an alternative a low-impact reverse engineering method would minimize potential effects on both dependability and security attributes of a system. It is important to note that this definition allows for an offset compared to “zero” impact. This can also be perceived as a risk of measurement regarding the legacy system under observation. As it is more realistic to presume only a limited level of access that is expected to be available to different system components, “white box” situations excluded, practical observability limitations are described as either “black box” or “gray box” for the purpose of this paper by the following attributes:
-
Assets: information on significant system components is available so that they are identifiable together with major revisions (e.g. software versions). Information on minor revisions, patch levels and specific configuration options can be limited.
-
Configuration: machine readable configuration attributes in the form of files or an unprivileged or read-only user accounts are available on significant system components, including read access to (critical) infrastructure components and APIs. Access to highly critical components can still be limited.
-
Communication: data flows between significant components are observable to at least the level of source, destination, type and quantity properties. Content of communication might not be available. Access to critical, separated or internal communication channels can still be limited.
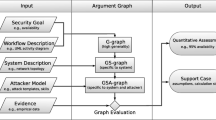
This paper presents our automated method for performing near real-time risk assessment with a “gray-box” approach assuming partial observability, primarily targeting clients of the National Cybersecurity Center (NCC) of Hungary. These include high-security IT systems that are characterized by restricted external monitoring due to stringent data security and privacy requirements, limited or no access to centralized management, configurations, or logs and challenges in information sharing, often due to operational, regulatory, or security considerations.
The contribution of our work is the low-impact nature of the observability of the assessed system, the newly introduced RiskRank attackers’ behavior model and the automated risk assessment method supported by an attack graph based visualization method.
This paper makes a significant contribution to the field of cybersecurity by addressing the automated and near real-time risk assessment of high-profile infrastructures, which are recognized as critical from both security and data protection perspectives. Due to their high sensitivity, these infrastructures allow only limited observability, posing unique challenges. To the best of our knowledge, no prior research has specifically targeted these aspects or demonstrated comparable results, making this work a valuable advancement in this vital area.
The structure of the paper is as follows, Sect. 2 summarizes relevant research field and their results in the fields of Model driven reverse engineering, risk assessment, graphical security modelling, security analysis based on attack graphs and attacker’s behavioral model. Section 3 introduces our solution for the graph data collection, attack graph generation, attackers’ behavior analyses and risk assessment calculation. In Sect. 4 we present our test result and in section 5 we evaluate the advantages and limitations of our algorithm. Finally, section 6 concludes our work and mentions potential future research directions.
2 Related work
2.1 Risk assessment
Discovering vulnerabilities is crucial, but the ability to assess the associated risk to the business is equally important. This can be achieved through various means, including threat modeling early in the development cycle, code review, penetration testing, or even post-production compromises. The ISO 31000 risk management standard mandates regular risk analysis to assess and mitigate risks, comprising several consecutive steps.
Risk assessment includes processes such as risk identification, analysis, and evaluation. Risk identification means recognizing sources of risks, events, and their potential consequences. One widely used approach for identifying threats is the STRIDE methodology [1], which categorizes threats into six types: Spoofing, Tampering, Repudiation, Information Disclosure, Denial of Service, and Elevation of Privilege. STRIDE provides a structured framework for systematically identifying potential risks and aligns well with automated risk assessment workflows by serving as a foundational step for vulnerability analysis and attack modeling. Risk analysis involves comprehending and determining causes and the likelihood that the consequences can occur. In risk evaluation, the various risks should be evaluated, and decision making occurs about the potential order or priority of how the identified risks should be treated.
The various internet-available risk assessment methodologies fall into two basic categories: human interaction-based, where humans define targets and risks, and automated ones, requiring minimal human intervention, particularly in selecting security metrics.
One of the human intervention-based methods was developed within the CORAS project [2] which offers a model-driven risk analysis approach, aligning with the ISO 31000 Risk Management standard. Comprising eight steps, it utilizes diagrams to visualize, evaluate, and treat risks, emphasizing viewpoint-oriented semiformal modeling. CORAS addresses security-critical systems, mainly focusing on IT security aspects. Its pillars include a Risk Documentation Framework, a Risk Management Process, an Integrated Risk Management and System Development Process, and a platform for tool inclusion. An extension of the CORAS project in [3] targets continuous risk assessment and critical infrastructures, emphasizing change and dependency handling.
An alternative approach, detailed by Keramati et al. in [4] introduces an attack graph-based security metric. Unlike CVSS, it quantitatively evaluates risks by considering interdependencies between vulnerabilities and assesses the impact on network security parameters. Chen et al. in [5] propose a quantitative threat modeling method for commercial off-the-shelf systems. Utilizing UML class diagrams, it models steps in an Attack Path involving Access, Vulnerability, Target Asset, and Affected Value, aligning with the Common Vulnerability Scoring System (CVSS) attributes.
As human intervention-based risk assessment is cumbersome, error-prone, and labor-intensive, a growing demand have also emerged for automated solutions.
The authors in [6] introduced an automated penetration testing framework tailored for cloud environments. While not explicitly utilizing attack graphs, their approach relies on a graph-based architecture description to organize and assess vulnerabilities, combining tools like OWASP Risk Rating [7], OpenVAS, and Metasploit to automate risk analysis and testing. Also authors in work [8] proposed a security assessment framework that employs Hierarchical Attack Representation Models (HARMs), integrating attack graphs as part of a layered approach to model vulnerabilities and node reachability in dynamic cloud systems.
These works served as an inspiration for our approach, which leverages reachability and vulnerability data to automatically generate risk metrics applicable to the entire infrastructure, aligned with the current threat landscape, and with minimal human intervention.
2.2 Graphical security modelling
One key aspect of risk analysis is the graphical modeling of security assessment. Graphical Security Models (GrSMs) play a crucial role, with Attack Graphs (AGs) and Attack Trees (ATs) being fundamental structures. These models have been continuously refined to enhance security assessment capabilities. The above-mentioned two basic structures of GrSMs—Graph-based and Tree-based approaches -, both involve phases like preprocessing, generation, visualization, evaluation, and modification to assess network security comprehensively [9].
Attack Trees were first formalized by Schneier [10] provide a systematic and formal way to describe potential attacks against a system. They are structured as trees, where the root node represents the attacker’s goal and paths from leaf to root nodes represent different methods to achieve that goal. While Attack Trees excel in modeling attack scenarios, they do not explicitly account for countermeasure events. This limitation led to the development of variations like Defense Trees (DT) [9], Protection Trees (PT) [11], and Attack Countermeasure Trees (ACT) [12], each addressing specific aspects of security mitigation. Additionally, models like OWA (Ordered Weighted Averaging) [13] introduce probabilistic security analysis based on weighted averaging operators, allowing for a more detailed evaluation. These models offer a comprehensive approach to understanding and mitigating security risks.
On the other hand, Attack Graphs (AGs) are instrumental in understanding the interdependencies among vulnerabilities and actions that can lead to a security breach in a network. They visually represent potential attack paths, outlining the various aspects involved, such as vulnerabilities, network configuration, and exploits. This graphical representation is valuable in comprehending the possible attack vectors from potential attackers to target hosts.
While AGs offer a powerful tool for visualizing attack scenarios, they face a scalability challenge, especially when dealing with large networks. Jha et al. [14] have proposed a greedy algorithm to address this, enabling security administrators to analyze and prioritize attack paths more cost-effectively. The advantage of AGs lies in their ability to show the relationship between different attack steps and vulnerabilities, providing a comprehensive view of the attack surface. This allows for a more holistic assessment of network security, as it considers the sequence of attacks, which is essential in understanding the potential impact of a breach. Despite scalability challenges, AGs remain a crucial component in the arsenal of security measures, providing a visual framework for analyzing and mitigating security risks.
Attack graph models can be classified mainly into three major groups: State-based attack graphs are built on state nodes, where a state can model a static state of the investigated network. A state can represent a specific vulnerability or a product on a network host, the attacker’s privilege gained on a host, the existence of some kind of reachability relationship between nodes in the network, or the impacts of a leveraged exploit on network performance [15]. Host-based attack graphs are built up from nodes representing the network host under investigation. Host-based attack graphs cannot represent certain attack types well like privilege escalation attacks carried out on the same node or man-in-the-middle attacks. The third type of attack graph is a vulnerability-based attack graph. As their names suggest, they contain vulnerability nodes and provide the possibility to represent the connection between vulnerabilities in the system. The most frequently used ones are vulnerability-based or state-based graphs, but different hybrid solutions exist in the literature based on the use cases [16].
In addition to Attack Trees (ATs) and Attack Graphs (AGs), researchers have recognized the need for more scalable and adaptable models for assessing network security. This led to the development of Hierarchical Attack Representation Models (HARMs) [17]. HARMs are designed to be more scalable than AGs, as they focus on modeling the reachability of nodes in a networked system separately from the vulnerability information of each node. By adopting a layered approach, HARMs can incorporate different security models in each layer, such as AGs in the upper and ATs in the lower layer. This adaptability to changes in the networked system makes HARMs a promising tool for dynamic environments.
The Temporal Hierarchical Attack Representation Model (Ti-HARM) [18] is a notable advancement in the direction modelling dynamically changing network configurations over time, which is a critical consideration for modern enterprise networks.
2.3 Graph generation tools
The literature mentions several attack graph generation tools, in the following the most notable ones are going to be introduced.
MulVAL [19] is an open-source linux-based tool that uses Datalog, a subset of Prolog, to describe node configurations, vulnerabilities, and attack exploitation rules formally. It generates a logical attack graph illustrating the causality relationship between some facts that can be deducted from system configuration, topology, and potential attacker privileges information. The tool encodes data from vulnerability databases, machine configurations, and network details as Datalog facts, distinguishing between fact nodes and derivation nodes. MulVAL has several advantages, including various extensions [20,21,22] to the original one and the possibility to connect information from MITRE  [23] and datalog rules, but the implementation is rather complex and includes python, Java, and datalog codes. Moreover, only one ultimate goal can be defined as a starting point for the attack graph, and Nessus or Oval vulnerability scanners’ outputs should be thoroughly converted to serve as input for the tool.
[23] and datalog rules, but the implementation is rather complex and includes python, Java, and datalog codes. Moreover, only one ultimate goal can be defined as a starting point for the attack graph, and Nessus or Oval vulnerability scanners’ outputs should be thoroughly converted to serve as input for the tool.
NetSPA [24] constructs attack graphs by analyzing firewall rules and vulnerabilities. It represents the network using vulnerability scans, databases, firewall rules, and topology information. The tool computes reachability, classifies vulnerabilities, and employs machine learning techniques for pattern classification. Additionally, it provides prioritized recommendations to enhance defense. NetSPA was designed to serve as a fast and efficient visualization tool for attack relationships, but it also has some limitations: it is controlled by command line inputs that determine a critical goal state, trust relationships between hosts, and maximum recursive depth [25].
TVA (Topological Vulnerability Analysis) [26] is also an open-source attack graph generation tool developed by George Mason University based on topology information. It can analyze network vulnerability automatically and extract data for the generation. It also establishes a state transition diagram, which supports scalable vulnerability analysis. The most significant disadvantage of TVA is the manual intervention in creating the rule set.
The Attack Graph Toolkit [25], developed at Carnegie Mellon University, operates on Linux with open-source code but faces challenges due to poor scalability and a complex, exponential attack graph generation algorithm. The state diagram design uses nodes representing network system states and edges for state transitions. Its architecture includes three modules: network modeling tools, a scene attack graph builder, and a graphical user interface. Despite its graphical interface and open-source nature, the scalability issues of the toolkit limits its applicability to large and medium-sized networks.
2.4 Graph simplification
As it was already mentioned in previous sections, attack graphs suffer from scalability issues. While the generation of the attack graph represents a polynomial complexity the evaluation of the graphs poses a scalability problem due to the space explosion when investigating all the possible attack paths in the network [9].
One simplification method that aims to avoid the state-explosion problem is attack path-based pruning method. Kaynar et al. [15] thoroughly investigate and classify pruning methods. According to their work, attack paths can be pruned based on depth limitation, probability information, or goal orientation.
Xie et al. in [27] use predefined probability thresholds and key-states to control the graph generation in space.
There are also other techniques to control the space complexity of an attack graph generation. One of them is graph node grouping. Ma et al. in [28] have focused on the two main issues related to attack graph generation. The first one is the time complexity of the algorithm, and the other one is the space complexity of it. They have already incorporated a grouping method considering reachability conditions in the given infrastructure. According to it reachability information is not stored independently if two nodes reside in the same subnetwork.
Zhang et al. [29] use a three-step-based network model abstraction to avoid the scalability problem. The first step is grouping based on reachability information. Hosts whose reachability information is the same, also from and to, are grouped together. The second step is vulnerability-based grouping, where vulnerabilities on the same host can be grouped based on similarities. The third one is configuration-based grouping, where hosts in the same reachability group are further grouped based on their configuration. Yousefi et al. in [30] used a so-called transition graph. After creating a logical attack graph with MulVAL, they refined the generated graph. This transition graph reveals the attackers’ possible steps through the existing vulnerabilities in the system, creating a vulnerability graph. This simplified graph allows evaluation complexity to be controlled more easily.
According to our goal, providing an automatized, general risk assessment methods the focus of our simplification method is mostly based on reachability information and structure simplification without loosing information about the system.
2.5 Attackers’ behavioral model
In all attack graph generation methods, the most challenging subtasks include modelling attacker behaviour and discovering the relationship between certain preconditions and the actual attacks.
Determining what is required for an attack to succeed is often referred to as defining the attack template, and this is the phase that is most often done manually. For example, if attackers are able to access a particular server with user privileges, they will not be able to execute arbitrary code, but if they are able to gain root privileges, they will be able to do whatever they want. Even the already mentioned and widely used open source MulVAL graph generator using Prolog requires the manual definition of attack templates.
The role of the attacker model is also crucial in attack modelling, and even in prediction and risk analysis tasks. Several existing approaches consider different characteristics of attackers when modelling attacks. Some studies use only the high-level goal of the attackers, others incorporate information such as the complexity of the attack they are trying to exploit, the tools they use, their motivation, the location of the attackers, and finally their preference to remain hidden and undetected [31].
There are several existing methods in the literature to characterise the behaviour of attackers. The behaviour of attackers can mainly be classified into the following classes: Markov chain based models capture behavioral aspects and vary based on the available information and decision-making processes [32].
Game theoretic models: In these models cybersecurity is considered as a game between attackers and defenders. It can help determine the best strategies with optimizing costs and profits [32].
Random walk based models: This is a realistic assumption, since many known attacks use a brute force probe-scan approach. Mehta et al. in [33], proposed two different methods for ranking the nodes of an attack graph. The first algorithm uses the Google’s PageRank algorithm, while the other uses a random walk model to indicate the probability of the attackers to reach that node. The authors proved that both algorithms can work well even when the exact transition probabilities are not known.
In our work we adopt this realistic random walk-based assumption, while also considering both the complexity of the attack and the user privileges.
3 The proposed model
For the purpose of our research, a low impact, “gray box” level of infrastructure access is presumed. This condition is also posing a severely limiting factor in the aspect of instrumentation possibilities. In this section we introduce our generated model, starting with the description of our data sources in 3.1 followed by our graph generation module in 3.2. Our algorithm for preparing the vulnerability graph for risk assessment is detailed in 3.3 and finally the risk calculation method is presented in 3.4.
3.1 Data and information used for risk assessment
According to our basic model risk-related information can be obtained from several distinct sources as:
-
Direct event sources operating within the critical infrastructure: these can include log sources, such as perimeter defense devices, including firewalls or intrusion detection systems (IDSes). In several rare cases, existing log emission or log collection capabilities can also be utilized as direct event sources and also observation of communication patterns of critical infrastructure components may be enabled. For the purpose of our research we are processing netflow [34] data obtained from routers within the observed infrastructure. The feasibility of utilizing sflow [35] as a network data source was also examined for the testbed but later dropped primarily due to technical reasons.
-
Networked services operating within the critical infrastructure: as the primary purpose of networked services is to provide a communication interface between the critical infrastructure and the outside world, we expect that automated survey of these will not violate our original goal of low impact data collection. For the purpose of the research, automated vulnerability scanning of public network services was conducted in the testbed environment using OpenVAS [36]. It shall be noted that the impact of this data collection activity could be finetuned by adjusting both the intensity and the origination points of these scans.
-
Asset and configuration information of the critical infrastructure under observation: as described in Sect. 1 we presume that there is no technical data source present in this aspect. For the purpose of the research, we aim at a minimal level of information represented as implicit knowledge built into the data processing environment in the form of configuration and thresholds. For further aiding this effort, a survey targeted at the critical infrastructure operators from the constituency of NCC Hungary was conducted, the resulting asset inventory information then was utilized as a data source during processing configuration.
-
Incident event sources pertaining the system under observation: these include publicly available information that is relevant to the critical infrastructure under observation, such as cyber threat information (CTI) feed elements pertaining asset and configuration items identified in the infrastructure by previous data collection steps. These event sources may also fall into the category of open-source intelligence gathering (OSINT), describing manual or semi-automated research conducted against a specific critical infrastructure operator or infrastructure. During our research we have processed social media feeds (most prominently from security related subreddits of the Reddit platform [37]), as well as collection of Common Vulnerabilities and Exposures from the US National Vulnerability Database (NVDCVE) [38].
From the perspective of risk assessment, the severity of threats, that is, the conditions for their exploitation and their impact on infrastructure, is critically important. This severity attribute of the threat entity can be calculated involving many factors from which the Common Vulnerability Scoring System (CVSS [39]) is considered a dominant source of truth in our case. The attribute then can be later adjusted based on related public data sources, for example on social media posts involving description of the specific vulnerability.
The set of surface attributes can be used for describing platforms or software where a threat is relevant. For this purpose, the Common Platform Enumeration (CPE) [40] scheme was selected. Besides platform aspects, other factors from the common vulnerability scoring system (CVSS) might also be applied, most prominently those that are describing attack conditions, like attack locality or attack complexity. Availability of tooling (for example ready-made exploit scripts) or privilege requirements for access or execution of the exploit (user access, administrative access, none) can also be extracted from CVSS or keyword-based analysis of related OSINT sources. In order to keep our research focused, we are currently implementing a naive approach to severity and attack surface calculation by extracting attributes primarily from NVDCVE and CVSS data, we believe that this imposes no practical limitations on our results further discussed in upcoming sections.
Vulnerability knowledge represents specific information directly affecting the critical infrastructure under observation. This vulnerabality information is represented in the graph by relations (edges) between nodes that represent infrastructural assets. A vulnerability relation is temporal in the sense that there is a specific time window where it should be considered relevant. This time window is practically related to the frequency of vulnerability information events received from the observed critical infrastructure. In our simulation environment, we chose to define this expiration period to be 30 days in order to ensure the sufficient size of the attack surface considered during graph generation steps.
Our anonymized input data used in this study are available at [41].
3.2 Graph generation module
Today, attackers usually face a complex challenge to compromise the target system, with or without prior knowledge of how to attack the network. However, they can use various tools to launch an attack and try to corrupt the system in some way.
During our work, we investigated several open-source graph generation applications as it was already mentioned in subSect. 2.3. Ultimately, we found a relatively simple method for discovering the potential attacks and their relationships on the given infrastructure. This solution in [42] can be found on GitHub, which was based on the authors’ work in [43]. The implementation is based on python3, MongoDB, and SPLUNK.
This original solution uses a StateNode and VulnerabilityNode-based attack graph. The StateNode refers to a host in the network (end device, network device, server, ...) with a privilege level representing the attacker’s gained privileges on that specific host and the vulnerability node refers to a vulnerability maintained in the NVD database. Directed edges connecting a StateNode and a VulnerabilityNode represent the fact that the host can reach another host on a port where a vulnerability exists, assuming the obtained privilege level is enough for the exploitation. Edges leading from a VulnerabilityNode to a StateNode represent the consequences of exploiting the vulnerabaility on that host, whereby by exploiting those vulnerabilities, the attacker can gain the StateNode privileges that this Edge is pointing to.
The graph generation tool takes different simple structured input files (specifically .csv files), which provide information about the analyzed network, for example, reachability information, i.e., which devices can reach which other devices on specific ports with specific protocols, vulnerability information, i.e., what kind of vulnerabilities do exist in the network and which ports and protocols are related to that vulnerability.
When executing the code, it takes these input files and asks for additional information like the starting nodes for calculating the Attack Graphs extending from the starting nodes as root nodes. Based on these data, it generates the attack graph.
This solution can also correlate Splunk information to the attack graph based on CVE-to-Event mapping, which is also taken as input for the program. When crown jewels (the most critical resources in the system) are defined, the generated graph gives back the actual attack paths starting from the start nodes pointing to the crown jewels and passing through the notable events correlated to the node of the attack graph. Thus, it can reverse engineer the actual events to the causes or preconditions.
In our solution, we used the code mentioned above as a starting point but carried out some significant modifications as described in the following:
-
Our graph has an even more simplified structure since the only node type in the graph is a StateNode, which is a tuple (host, level) also representing the actual host of the infrastructure with the highest gained privilege on that node. The directed edges represent the vulnerability. The edges have a Name that refers to the vulnerability of the endpoint node on a given port. Therefore, two StateNodes are connected with an edge if a vulnerability exists, and leveraging this vulnerability can move the attacker to the other StateNode. This simplification served both easy interpretability and reduced structural complexity which inherently influences time complexity of the algorithm executed on the graph. Meanwhile the simplifications did not result in any data loss concerning the risk analysis of the entire infrastructure.
-
The starting node in our implementation is explicitly defined in the graph and called StateNode(EXT, 0), where ’EXT’ refers to the fact that the attackers before starting their attacks reside outside of our network somewhere connected to the Internet. The ’0’ refers to the fact that the attacker does not have any special privileges yet. This external node will also indicate that the attackers have discontinued their attack. It was an important modification since our graph was to be extended into a Markov chain based representation incorporating attackers movement.
-
Crown jewels (most critical resources that should be defended) are not defined at this point in our solution, which means there is no ultimate goal to reach in the network, but we would like to investigate all the attack steps, possibilities, and relationships in the whole topology. This modification broadens the scope of our work not limiting the focus on pathways leading to high-value assets but enabling analyses of all possible movements.
-
The input data for our vulnerability graph generation module are obtained from sources described in Sect. 3.1.
Figure 1 illustrates an attack graph for a hypothetical network using sample data. The StateNodes (e.g.: (A, 0, state) ) in the graph represent states within the network. According to the sample data, attackers initially possess ’0’ privileges, indicating that no special privileges have been acquired at this stage. This is indicated by the middle 0 in the triplet. The edges in the graph denote vulnerabilities, with their corresponding CVE identifiers labeled. Edges exist between StateNodes when vulnerabilities are present, allowing attackers to transition to the end node of the edge upon successful exploitation of the vulnerability.
The figure also highlights the initial node, labeled as (EXT, 0, state), and an initial vulnerability, CVE-2016-3169, which can be exploited by attackers to gain entry into the target system. This vulnerability was derived from the initial dataset that was fed into the system and was based on two criteria: 1. The connected node to the starting node must have a vulnerability with a NETWORK attack vector, ensuring that the exploitation does not require local access. 2. The privileges required for exploiting the node must be ’0’ at this stage.
This representation provides a clear visualization of the potential attack paths within the network, emphasizing the critical vulnerabilities that can be exploited by attackers with minimal privileges.

Sample vulnerability (attack) graph
3.3 Attackers’ behavioral model
The previous section introduced our attack graph generation module. To assess the security level of the examined network, calculating the probability of the attackers being in the individual states is crucial. To calculate this probability, it is foremost important to model the attackers’ behavior. As mentioned above in Sect. 2.5, several solutions exist to model how an attacker can proceed in the network. Our aim was to have a realistic behavior description where attackers employ trial and error methods, often lacking a well-defined action plan. Initial attack steps typically involve reconnaissance activities, utilizing OSINT technologies and various scanning methods. On the other hand, the success of the hacking attempts, depends on multiple factors. These include the attackers’ knowledge, the tools employed, the time invested, the devotion of the attackers, and finally, the difficulty of executing the attack.
To address both the difficulty of executing the attack step and the random manner in which an attacker attempts, we created a Markov chain-based model and have created a novel risk ranking algorithm (RiskRank) based on Google’s original PageRank [44] algorithm which was invented to rank the web pages and to model the random behavior of a web surfer.
In the following the generation of the Markov chain is explained and the RiskRank algorithm is introduced.
For the initial attack graph (as represented in Fig. 1) initial probabilities were assigned to the edges. These initial probabilities, representing exploitability values, are derived from the CVSS exploitability subscore and calculated using Eq. (1). The values range from 0 to 1, where a higher value indicates a vulnerability that is easier to exploit. These values, referred to as probability values (P_exp), reflect the difficulty of executing the actual attack step.
where AV, AC, PR refer to AttackVector, AttackComplexity and PrivilegedRequired subscores respectively.
As an example this (P_exp) value is calculated by equation (2) for the vulnerability CVE-2016-3169, as AV=NETWORK, AC=HIGH, and PR=NONE according to NVD.
In order to assess the risk of the whole network infrastructure we have to make some modifications to the above generated simple vulnerability graph making it suitable to also model attackers’ behaviour.
In the following the five steps of our algorithm and their explanations are introduced:
-
1. Step Simplifying the graph
-
2. Step Modifying the exploitability values for the edges
-
3. Step Extension of the attack graph to a Markov chain
-
4. Step Simplification of the graph
-
5. Step Execution of the RiskRank algorithm
Step 1. First simplification in the graph
In actual networks, it is common to encounter multiple parallel edges in the preliminary attack graph with identical start and end points. This occurs because a host or device can possess several vulnerabilities associated with the same communication protocols and ports. To simplify this initially generated graph, we replaced parallel edges with a single vulnerability edge. This consolidated edge is assigned the average of all the exploitability probabilities of the original edges and is labeled with a list of the CVE identifiers for all substituted vulnerabilities. This method significantly simplifies subsequent calculations and enhances the transparency of the algorithm.
Step 2. Modifying the exploitability values for the edges:
Until now, we had a simplified graph with just one node type, the StateNodes, which can be also considered as \(<<\)after exploitation states\(>>\). The edges were defined as vulnerabilities, and the values assigned to the edges represent the exploitability derived from CVSS for the respective vulnerability. In this 2. step we modify the original values according to the graph structure to fully model the random behaviour logic of the attacker. To account for uncertainty, it is assumed that the attacker may randomly select from the available vulnerabilities to exploit. Each edge originating from a node is assigned a number, which represents the probability of choosing that vulnerability to be exploited by the attacker. Since we try to create a general model, we do not want to take into account all the different factors that can lead to a successful attack (knowledge, intention, tools used, etc.), but in general, we say that the attacker chooses one of the available vulnerabilities originating from that state randomly and the success of the exploitation is based on the probability values derived from CVSS.
In practice for example, according to Fig. 1 it means that attackers in StateNode A can choose between two existing vulnerabilities to exploit. They can decide to exploit vulnerability CVE-2013-1534, leading to StateNode B, or choose vulnerability CVE-2002-0392, leading to StateNode C. The selection is randomized; thus, the probability of selecting either is p=0.5. This probability is calculated for all edges and then it is multiplied by the exploitability value of that attack.
Step 3. Extension of the attack graph to a Markov chain:
It is crucial to recognize that the behavior of attackers, in their attempts to compromise our system, can be modeled as a Markov process. In this context, each state is transitional; the model assumes that the attackers’ decisions on how to proceed are based solely on their current position, without considering their past actions. We do not distinguish between terminal and non-terminal states. The RiskRank algorithm should be applied to a Markov chain. Given that the original PageRank algorithm is iterative, it is necessary to demonstrate that the probabilities will converge to a stationary distribution.
To ensure a stationary distribution, it is imperative to construct an irreducible and aperiodic Markov chain. Consequently, we extend our graph in this step to create a Markov chain that accurately represents the attacker’s behavior with associated probabilities. The pseudo-algorithm for the graph extension process is presented in Algorithm 1.

The simplified graph stemming from the previous step only contains vulnerability edges. As it can be seen, two new types of edges were defined in this step. The first type represents the so-called “damping factor” of the attacks. This factor is important to model real scenarios. The choice of the damping factor can be configured according to the specific environments investigated. We incorporated a damping factor into the model to account for the diminishing motivation of attackers over a series of consecutive attack steps. This factor reduces the attackers’ incentive by a certain percentage with each additional attempt. In our simulations attackers continue to attack with a damping factor of \(d=0.85\). That means being in either state there is \(P_{Exit=0.15}\) for the attacker to quit and stop attacking. It can be visualized with edges that connect each node with the EXT state (lines 7–10). In line 7 EXIT edges refer to this event. The probability assigned to these edges is 0.15 at this stage in our work (lines 8–9) but are later fine-tuned.
Introducing these edges suggests that all the already modified exploitability probabilities assigned to edges representing vulnerabilities in the system should be multiplied by 0.85.
On the other hand, it can also happen that attackers residing in any state have already attempted to exploit all the vulnerabilities stemming from that state without any success. Without giving up their attempts, they can move backward to the previous state and start a new attempt from there in another direction. For this reason, it is necessary to introduce so-called Backward edges for all vulnerability edges. These Backward edges lead from the end node to the start node of the actual vulnerability edge (lines 18–23).
The following method was used to calculate the probability for the newly introduced Backward edges: First, the probabilities for all of the vulnerability edges stemming from the node should be summed up, and the \(P_{Exit}\) should be added. The sum of it should be extracted from 1, and this residual probability (calculated in lines 11–17) should be distributed equally among all the backward edges stemming from the same node (lines 30–34). The equations for the calculation can be seen in (3) and (4). This calculation ensures that the sum of the probabilities for all outgoing edges will be 1 for each node.
where \(P_{backward\_prob}\) is the assigned probability of the actual Backward edge, \(P_{residual}\) is the residual probability after summarizing the probabilities of the vulnerability edges and the exiting probability, \(n_{backward}\) is the number of the outgoing Backward edges on that node, d is the damping factor (exiting probability) and \(P_{Succ_{expl} } (u;v)\) is the probability of selecting (u; v) vulnerability and exploiting it successfully.
Step 4. Simplification of the graph:
The resulted extended graph (Markov chain) may have several parallel edges stemming from the same start node and leading to the same end node, however their probabilities must sum up to 1. To simplify the graph and eliminate all the parallel edges, we can substitute the groups of parallel edges leading to the same node with only one edge having a summarized probability. The extended and simplified graph with the calculated probabilities assigned to the edges can be seen in Fig. 2.
Figure 2 shows already the Exit edges and Backward edges with assigned probabilities according to the detailed algorithm. It can be clearly seen, that from StateNodes (C, 0, state) and (B, 0, state) Exit edges pointing towards the StateNode (EXT, 0, state) with an assigned probability (damping factor) of \(d= 0.85\). From StateNode (A, 0, state) there is no direct Exit edge pointing towards (Ext, 0, state), because it would create a parallel edge with the initial vulnerability (CVE- 2016-3169) shown in Fig. 1. During the second simplification step these edges were replaced by a single edge with a cumulative probability. Additionally, the figure illustrates that the sum of all outgoing probabilities from any given node is always equal to 1.

Resulted Markov chain for our sample graph
From the deduction below it can be easily seen that this graph corresponds to an aperiodic and irreducible Markov chain, where the probabilities assigned to the edges represent the state transitions between the different states.
A Markov chain is considered irreducible if any state can be reached from any other state, possibly in multiple steps. In other words, a Markov chain is irreducible if there are no "absorbing states" that cannot be left once entered.
In the context of Markov chains, a chain is said to be aperiodic if the greatest common divisor (GCD) of the lengths of all cycles in the chain is 1. In simpler form, a Markov chain is aperiodic if it has no regular, repeating patterns in its state transitions.
Both irreducibility and aperiodicity are true in our case. A chain is aperiodic if it is irreducible and if all states are aperiodic, which is ensured by one state being aperiodic. Since (EXT,0,state) is aperiodic, because starting from this node, returns can happen in 1,2,3 or more steps. Thus, the greatest common denominator is 1. Any finite, irreducible, and aperiodic Markov chain P (i.e., regular) has a unique stationary distribution [45].
Step 5. Execution of the RiskRank algorithm:
The original PageRank algorithm was modified with the following conditions:
-
the edges do not have identical but weighted values
-
the starting probability of StateNode (EXT,0,state) is 1, and for all other nodes, it is 0. This corresponds to the fact that the attacker initially resides somewhere on the internet with a network connection to the investigated network.
The pseudo algorithm for the RiskRank algorithm can be seen in Algorithm 2. Executing the algorithm will converge to the stationary distribution of the Markov chain and will give the probability of the attacker being in the different StateNodes. The convergence criteria were defined as follows: The algorithm is stopped if the average difference of the probabilities calculated for all nodes in two consecutive iterations is less than a predefined threshold. In our case this threshold was \(t = 0.001\).
The converged values represent the probability for the attackers being in the individual states after arbitrary number of attack steps, and these values are used in the risk calculations described in the following subsection.

3.4 Risk calculation
The risk is generally calculated based on the probability of the occurrence of the individual risk and the impacts of it. Similarly, in our work, we followed almost the same approach; at first identifying the individual risks as attackers being in the different StateNodes then calculating the probabilities of the occurrences of these risks connected to the various states and lastly examining their impacts on key security indicators.
Since CVSS (Common Vulnerability Scoring System) treats them separately, during our research, we also considered individually the effects of each event or vulnerability exploitation on confidentiality, integrity, and availability. Therefore, for each node in the graph, we examined all paths leading from the EXT (external) node to that StateNode. Traversing these paths, we identified the maximum confidentiality, availability, and integrity values for each node, storing these values for the corresponding states. As a result, for each node, we obtained the value of its impact on network security indicators. Naturally, this provides a pessimistic estimate of the risk at each StateNode in the network. However, it can calculate the maximal risk at each node.
Finally we characterized the security level of the investigated system by calculating the aggregated risk over all network nodes, providing an overall picture of the network’s security posture. The resulted risk level is between 0 and 1, with lower values indicating a more reliable and resistant infrastructure, while higher values provisioning high security risk.
According to the CVSS values, the impact on confidentiality, integrity and availability has three different ranges, namely None, Low, High. The overall level of security can also be characterised in the same way, with very low (almost none), low or high security-related risk in the network.

Markov chain for our network
4 Testing the algorithm for real network
We successfully tested our algorithm on a designated VLAN within our network, which consisted of 12 communicating nodes. The resulting Markov chain is depicted in Fig. 3. For improved transparency and ease of reference, the probability values (rounded to four decimal places) calculated for the edges in the Markov chain have been represented in Table 1. In both the diagram and the table, actual IP addresses are replaced by integers, numbered sequentially from 0 for better readability. According to Fig. 3 and Table 1 the external stateNode (’EXT’, 0, state) is node 2, and node 1 is considered as the most vulnerable node in our system. Node 2 has the most vulnerabilities and all the other nodes that communicate with it on ports 443 and 80 according to our netflow data can initiate attack against it. Our netflow data is gathered from the last 30 days and were aggregated and transformed to a simple structure.csv file where source IP addresses and destination IP addresses with port numbers were given and was generated from the netflow statistics. Our vulnarability data were also transformed to a simple structure.csv file where host IP addresses, CVE catalog ID numbers and associated portnumbers were given.
These results underwent thorough verification, confirming their accuracy. The aperiodicity and irreducibility of the Markov chain were straightforward to demonstrate since the Markov chain is aperiodic as it contains self-loops (edges that loop back to the same state at the external node) and cycles of various lengths (e.g., length 2 and length 3 cycles). These features ensure that the chain does not get trapped in any periodic cycle, thus meeting the condition for aperiodicity.
Additionally, the chain is irreducible, meaning that it is possible to reach any state from any other state. This property was verified by ensuring that there exists a path (direct or indirect) between every pair of states in the chain.
As the irreducibility and periodicity conditions are met, the convergence of the algorithm is ensured.
For calculating the stationary distribution of the RiskRank algorithm we used the threshold t = 0.001 which yielded the following probabilities: for the external node \(p_2\) = 0.6020, for the vulnerable node (node 1) is \(p_1\) = 0.064, for the internal node (node 3) it \(p_3\) = 0.180 and for the other nodes the rounded probability values are equally p = 0.05. Thus it can be concluded that it is more likely that the attacker resides outside the network.
After calculating the impact values (integrity, availability and confidentiality impact values) for all the nodes we can calculate the overall risk which was considered according to the method described in 3.4 resulted in \(R_i\) = 0.31752 \(R_a\) = 0.3076 and \(R_i\) = 0.3136 respectively. As a result we can state there is not a huge risk in our network considering the actual landscape. Of course, it is important to revise these values from time to time as the threat landscape or the configuration of the network changes.
5 Evaluation of the algorithm
The rigorous validation of the above results confirms the algorithm’s robustness and correctness. The aperiodicity and irreducibility properties are critical for ensuring that the Markov chain model provides reliable and accurate insights into the network’s behavior.
5.1 Time complexity
The algorithm’s complexity arises from multiple stages of processing. Initially, constructing the vulnerability graph requires an exhaustive examination of the netflow data. This process can reach a complexity of \(O(n^2)\) (n representing the number of nodes) in scenarios where every node communicates with every other node. Furthermore, assessing the vulnerabilities associated with each connection between nodes involves an additional complexity of O(n), leading to an overall complexity of \(O(n^3)\).
Subsequently, transforming the vulnerability graph into a Markov chain necessitates further operations on the vulnerability graph. This step involves multiple iterations, each with a maximum complexity of \(O(n^2)\).
Lastly, the complexity of our RiskRank algorithm is \(O(k(n+m))\), where n is the number of nodes (StateNodes), m is the number of edges, and k is the number of iterations until convergence.
Our algorithm’s deterministic nature ensures that it can be consistently reproduced and its processes clearly elucidated. However, the current iteration of the algorithm exhibits significant computational complexity, specifically O(n\(^{3}\)). This level of complexity was deemed acceptable for our proof-of-concept implementation, acknowledging that it is not optimized yet for scalability.
5.2 Limitations and future directions
In practical terms, the above detailed lack of scalability is evident in the time required to construct the Markov chain, which exceeded one minute when applied to our network. This performance limitation underscores the need for further graph simplifications like grouping nodes with similar reachability or nodes with similar vulnerabilities.
Our algorithm have also some other weaknesses. First, due to the "gray-box" approach, we do not have reachability information for every node pair, protocol, and port. The algorithm operates on partial data; a 30-day netflow does not reveal all possible connections. This is a contextual constraint inherent to critical infrastructures, which we have taken into account during the development and evaluation of the algorithm. The data rely on the most frequent communications and vulnerability data from the last 30 days of network activity in our example network. This interval is adjustable, but it is important to note that this information is not timeless, as traffic patterns and the threat landscape continuously evolve.
Given these considerations, several future development directions have emerged. First, integrating information about the privileges acquired through vulnerability exploitation. This data is not yet available in a standardized format in the NVD database. However, by studying detailed vulnerability descriptions and monitoring social media feeds from platforms like Reddit, we can enhance our algorithm.
The current algorithm is implemented in Python, using several for loops, resulting in suboptimal execution and running time. As a future research direction, we aim to create a basic knowledge graph where all required information could be stored and periodically updated in Neo4j. This graph would allow for the continuous generation of the attack graph, adapting to changes in the network infrastructure and the evolving threat landscape. This approach can be easily incorporated into the current algorithm; for instance, if a vulnerability in the attack graph is mitigated, the corresponding edge can be removed, thereby reducing the probabilities associated with all other nodes in the network.
By implementing these enhancements, our method will become more robust and capable of adapting to the dynamic nature of network infrastructures and threat landscapes.
6 Conclusion
This paper contributes to the development of a novel methodology for low-impact, near real-time risk assessment of high-profile infrastructures, addressing challenges posed by limited observability due to data security or operational continuity. The research introduces a new perspective on processing and evaluating cybersecurity knowledge, leveraging attack graphs and attacker behavior analysis to assess risks and vulnerabilities. A naive approach to severity and attack surface calculation is implemented by extracting attributes primarily from NVD-CVE and CVSS data.
The method represents vulnerability knowledge in a graph through relations (edges) between nodes that represent infrastructural assets. A vulnerability relation is temporal, considered relevant within a specific time window related to the frequency of vulnerability information events received from the observed critical infrastructure.
Our solution also integrates an attacker behavioral model based on a random walk method similar to Google’s PageRank. This model considers the difficulty of exploiting vulnerabilities, the prerequisites for exploitation, and their impact on the network’s key nodes.
Despite its complexity, our algorithm has been validated for robustness and correctness. We acknowledge its limitations and propose future developments, including the integration of privilege acquisition data, optimization for scalability, and continuous risk assessment adaptation to network changes and the evolving threat landscape.
References
Archiveddocs. The STRIDE Threat Model. en-us. Nov. 2009. url: https://learn.microsoft.com/en-us/previous-versions/commerce-server/ee823878(v=cs.20)
Stolen, K. et al.: Model-based risk assessment–the CORAS approach. In: iTrust Workshop. Citeseer. (2002)
Solhaug, B., Seehusen, F.: Model-driven risk analysis of evolving critical infrastructures. J. Ambient Intell. Humaniz. Comput. 5(2), 187–204 (2014). https://doi.org/10.1007/s12652-013-0179-6
Keramati, M., Akbari, A.: An attack graph based metric for security evaluation of computer networks. In: 6th International Symposium on Telecommunications (IST). 6th International Symposium on Telecommunications (IST). (2012), pp. 1094–1098. https://doi.org/10.1007/11909033_20
Chen, Y., Boehm, B., Sheppard, L.: Value driven security threat modeling based on attack path analysis. In: 2007 40th Annual Hawaii International Conference on System Sciences (HICSS’07). Proceedings of the 40th Annual Hawaii International Conference on System Sciences. Waikoloa, HI: IEEE, Jan. (2007), 280a–280a. isbn: 978-0-7695-2755-0.https://doi.org/10.1109/HICSS.2007.601 (Visited on 12/03/2024)
Casola, V. et al.: Towards automated penetration testing for cloud applications. In: 2018 IEEE 27th International Conference on Enabling Technologies: Infrastructure for Collaborative Enterprises (WETICE). 2018 IEEE 27th International Conference on Enabling Technologies: Infrastructure for Collaborative Enterprises (WETICE). Paris: IEEE, June (2018), pp. 24–29. isbn: 978-1-5386-6916-7. https://doi.org/10.1109/WETICE.2018.00012
OWASP risk rating methodology. url: https://owasp.org/www-community/OWASP_Risk_Rating_Methodology (visited on 12/03/2024)
Alavizadeh, H. et al.: An automated security analysis framework and implementation for cloud. In: arXiv:1904.01758 [cs] (Dec. 3, 2024)
Hong, J.B., et al.: A survey on the usability and practical applications of graphical security models. Comput. Sci. Rev. 26, 1–16 (2017). https://doi.org/10.1016/j.cosrev.2017.09.001
Schneier, B.: Attack trees. Dr. Dobb’s J. 24, 21–29 (1999)
Edge, K.S.: A framework for analyzing and mitigating the vulnerabilities of complex systems via attack and protection trees. Air Force Institute of Technology, (2007)
Roy, A., Kim, D.S., Trivedi, K.S.: Cyber security analysis using attack countermeasure trees. In: Proceedings of the Sixth Annual Workshop on Cyber Security and Information Intelligence Research - CSIIRW ’10. the Sixth Annual Workshop. Oak Ridge, Tennessee: ACM Press, (2010), p. 1. isbn: 978-1-4503-0017-9. https://doi.org/10.1145/1852666.1852698 (Visited on 12/03/2024)
Roy, A., Kim, D.S., Trivedi, K.S.: Cyber security analysis using attack countermeasure trees. In: Proceedings of the Sixth Annual Workshop on Cyber Security and Information Intelligence Research - CSIIRW ’10. the Sixth Annual Workshop. Oak Ridge, Tennessee: ACM Press, (2010), p. 1. isbn: 978-1-4503-0017-9. https://doi.org/10.1145/1852666.1852698 (Visited on 12/03/2024)
Jha, S., Sheyner, O., Wing, J.: Two formal analyses of attack graphs. In: Proceedings 15th IEEE Computer Security Foundations Workshop. CSFW-15. 15th IEEE Computer Security Foundations Workshop CSFW-15. Cape Breton, NS, Canada: IEEE Comput. Soc, 2002, pp. 49–63. isbn: 978-0-7695-1689-9. https://doi.org/10.1109/CSFW.2002.1021806
Kaynar, K.: A taxonomy for attack graph generation and usage in network security. J. Inf. Secur. Appl. 29, 27–56 (2016). https://doi.org/10.1016/j.jisa.2016.02.001
Ghosh, S.K., Bhattacharya, P.: Analytical framework for measuring network security using exploit dependency graph. IET Inf. Secur. 6, 264–270 (2012). https://doi.org/10.1049/iet-ifs.2011.0103
Hong, J., Kim, D.-S.: HARMs: Hierarchical attack representation models for network security analysis. In: 10th Australian Information Security Management Conference (2012). https://doi.org/10.4225/75/57B559A3CD8DA (Visited on 12/03/2024)
Enoch, S.Y., Hong, J.B., Kim, D.S.: Time independent security analysis for dynamic networks using graphical security models. In: 2018 17th IEEE International Conference On Trust, Security And Privacy In Computing And Communications/12th IEEE International Conference On Big Data Science And Engineering (TrustCom/BigDataSE). IEEE. (2018), pp. 588–595
Ou, X., Govindavajhala, S., Appel, A.W., et al.: MulVAL: A logic-based network security analyzer. USENIX security symposium 8, 113–128 (2005)
Sembiring, J., Ramadhan, M., Gondokaryono, Y.S., Arman, A.A.: Network security risk analysis using improved MulVAL Bayesian attack graphs. Int. J. Electr. Eng. Inf. 7(4), 735 (2015). https://doi.org/10.15676/ijeei.2015.7.4.15
Jing, J.T.W. et al.: Augmenting MulVAL with automated extraction of vulnerabilities descriptions. In: TENCON 2017 - 2017 IEEE Region 10 Conference. (2017), pp. 476–481
Tayouri, D., et al.: A survey of MulVAL extensions and their attack scenarios coverage. IEEE Access 11, 27974–27991 (2023)
MITRE ATT &CK®. url: https://attack.mitre.org/ (visited on 12/03/2024)
Lippmann, R. et al.: Validating and restoring defense in depth using attack graphs. MILCOM 2006. Washington, DC, USA: IEEE, Oct (2006), pp. 1–10. https://doi.org/10.1109/MILCOM.2006.302434
Yi, S. et al.: Overview on attack graph generation and visualization technology. In: 2013 International Conference on Anti-Counterfeiting, Security and Identification (ASID). 2013 International Conference on Anti-Counterfeiting, Security and Identification (ASID). Shanghai, China: IEEE, Oct. 2013, pp. 1–6. isbn: 978-1-4799-1111-0. https://doi.org/10.1109/ICASID.2013.6825274 (Visited on 12/03/2024)
Jajodia, S., Noel, S., O’berry, B.: Topological analysis of network attack vulnerability. In: Managing Cyber Threats: Issues, Approaches, and Challenges (2005), pp. 247–266
Xie, A. et al.: A probability-based approach to attack graphs generation. In: 2009 Second International Symposium on Electronic Commerce and Security. 2009 Second International Symposium on Electronic Commerce and Security. Nanchang City, China: IEEE, (2009), pp. 343–347. isbn: 978-0-7695-3643-9. https://doi.org/10.1109/ISECS.2009.113
Ma, J. et al.: A scalable, bidirectional-based search strategy to generate attack graphs. In: 2010 10th IEEE International Conference on Computer and Information Technology. 2010 IEEE 10th International Conference on Computer and Information Technology (CIT). Bradford, United Kingdom: IEEE, June (2010), pp. 2976–2981. isbn: 978-1-4244-7547-6. https://doi.org/10.1109/CIT.2010.496. (Visited on 12/03/2024)
Zhang, S., Ou, X., Homer, J.: Effective network vulnerability assessment through model abstraction. In: Detection of Intrusions and Malware, and Vulnerability Assessment: 8th International Conference, DIMVA 2011, Amsterdam, The Netherlands, July 7-8, 2011. Proceedings 8. (2011), pp. 17–34
Yousefi, M. et al.: A novel approach for analysis of attack graph. In: 2017 IEEE International Conference on Intelligence and Security Informatics (ISI). IEEE. (2017), pp. 7–12
Doynikova, E., Novikova, E., Kotenko, I.: Attacker behaviour forecasting using methods of intelligent data analysis: a comparative review and prospects. Information 11, 168 (2020)
Zeng, J., et al.: Survey of attack graph analysis methods from the perspective of data and knowledge processing. Secur. Commun. Netw. (2019). https://doi.org/10.1155/2019/2031063
Mehta, V. et al.: Ranking attack graphs. In: International Workshop on Recent Advances in Intrusion Detection. Springer, pp. 127–144 (2006)
Claise, B.: Cisco systems NetFlow services export version 9. Request for Comments RFC 3954. Num Pages: 33. Internet Engineering Task Force, (2004). https://doi.org/10.17487/RFC3954 (Visited on 12/03/2024)
About sFlow Overview @ sFlow.org. url: https://sflow.org/about/index.php (visited on 12/03/2024)
OpenVAS - Open vulnerability assessment scanner. url: https://www.openvas.org/ (visited on 12/03/2024)
Reddit—dive into anything. Nov. 28, 2023. url: https://www.reddit.com/ (visited on 12/03/2024)
NVD—Home. url: https://nvd.nist.gov/ (visited on 12/03/2024)
NVD—CVSS v3 Calculator. url: https://nvd.nist.gov/vuln-metrics/cvss/v3-calculator (visited on 12/03/2024)
NVD—CPE. url: https://nvd.nist.gov/products/cpe (visited on 11/28/2023)
Rigó, E.: Anonymized netflow and security scan data. Version V1. 2024. DOI: 21.15109/ARP/FBIIOZ https://hdl.handle.net/21.15109/ARP/FBIIOZ
Tan, R.: Automating cyber incident response. original-date: 2019-07-10T02:37:22Z. Jan. 18, (2023). url: https://github.com/rebstan97/AttackGraphGeneration (visited on 12/03/2024)
Ingols, K., Lippmann, R., Piwowarski, K.: Practical attack graph generation for network defense. In: 2006 22nd Annual Computer Security Applications Conference (ACSAC’06). ISSN: 1063-9527. Miami Beach, FL, USA: IEEE, Dec. 2006, pp. 121–130. isbn: 978-0-7695-2716-1. https://doi.org/10.1109/ACSAC.2006.39 (Visited on 12/03/2024)
Haveliwala, T., Kamvar, S., Jeh, G.: An analytical comparison of approaches to personalizing pagerank. Tech. rep, Stanford (2003)
Freedman, A.: Convergence theorem for finite Markov chains. In: Proc. Reu (2017)
Héder, M. et al.: The past, present and future of the ELKH Cloud. Információs Társadalom (Information Society) XXII.2 (2022). issn: 1587-8694. https://doi.org/10.22503/inftars.XXII.2022.2.8
Acknowledgements
Project no. NKFIH-3568-1/2022 has been implemented with the support provided by the Ministry of Culture and Innovation of Hungary from the National Research, Development and Innovation Fund, financed under the 2022\(-\)2.1.1-NL funding scheme. The authors express their gratitude for computational resources provided by the HUN-REN Cloud [46].
Funding
Open access funding provided by Óbuda University.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Kail, E., Riethné Nagy, A., Fleiner, R. et al. Low-impact, near real-time risk assessment for legacy IT infrastructures. Int. J. Inf. Secur. 24, 67 (2025). https://doi.org/10.1007/s10207-024-00971-4
Published:
DOI: https://doi.org/10.1007/s10207-024-00971-4