
Abstract
In multiagent systems (MASs), each agent makes individual decisions but all contribute globally to the system’s evolution. Learning in MASs is difficult since each agent’s selection of actions must take place in the presence of other co-learning agents. Moreover, the environmental stochasticity and uncertainties increase exponentially with the number of agents. Previous works borrow various multiagent coordination mechanisms for use in deep learning architectures to facilitate multiagent coordination. However, none of them explicitly consider that different actions can have different influence on other agents, which we call the action semantics. In this paper, we propose a novel network architecture, named Action Semantics Network (ASN), that explicitly represents such action semantics between agents. ASN characterizes different actions’ influence on other agents using neural networks based on the action semantics between them. ASN can be easily combined with existing deep reinforcement learning (DRL) algorithms to boost their performance. Experimental results on StarCraft II micromanagement and Neural MMO show that ASN significantly improves the performance of state-of-the-art DRL approaches, compared with several other network architectures. We also successfully deploy ASN to a popular online MMORPG game called Justice Online, which indicates a promising future for ASN to be applied in even more complex scenarios.


















Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Notes
More details can be found at https://sites.google.com/view/asn-intro, the source code is at https://github.com/wwxFromTju/ASN_cloud
Our ASN is compatible with extensions of QMIX since these methods follow the QMIX structure and we select QMIX as an representative baseline.
The implementation details are not public since this is a commercial game and all details are close-sourced.
References
Sutton, R. S., & Barto, A. G. (2018). Reinforcement learning: An introduction. MIT press.
Mnih, V., Kavukcuoglu, K., Silver, D., Rusu, A. A., Veness, J., Bellemare, M. G., Graves, A., Riedmiller, M., Fidjeland, A. K., & Ostrovski, G. (2015). Human-level control through deep reinforcement learning. Nature, 518(7540), 529.
Lillicrap, T. P., Hunt, J. J., Pritzel, A., Heess, N., Erez, T., Tassa, Y., Silver, D., & Wierstra, D. (2016). Continuous control with deep reinforcement learning. In Proceedings of the 4th international conference on learning representations.
Silver, D., Schrittwieser, J., Simonyan, K., Antonoglou, I., Huang, A., Guez, A., Hubert, T., Baker, L., Lai, M., Bolton, A., Chen, Y., Lillicrap, T. P., Hui, F., Sifre, L., van den Driessche, G., Graepel, T., & Hassabis, D. (2017). Mastering the game of go without human knowledge. Nature, 550(7676), 354–359.
Claus, C., & Boutilier, C. (1998). The dynamics of reinforcement learning in cooperative multiagent systems. In Proceedings of the fifteenth national conference on artificial intelligence and tenth innovative applications of artificial intelligence conference (pp. 746–752).
Hu, J., Wellman, M. P. (1998). Multiagent reinforcement learning: Theoretical framework and an algorithm. In Proceedings of the fifteenth international conference on machine learning (pp. 242–250).
Bu, L., Babu, R., & De Schutter, B. (2008). A comprehensive survey of multiagent reinforcement learning. IEEE Transactions on Systems, Man, and Cybernetics, Part C (Applications and Reviews), 38(2), 156–172.
Hauwere, Y. D., Devlin, S., Kudenko, D., & Nowé, A. (2016). Context-sensitive reward shaping for sparse interaction multi-agent systems. The Knowledge Engineering Review, 31(1), 59–76.
Yang, T., Wang, W., Tang, H., Hao, J., Meng, Z., Mao, H., Li, D., Liu, W., Chen, Y., & Hu, Y. (2021). An efficient transfer learning framework for multiagent reinforcement learning. In Advances in neural information processing systems (vol. 34, pp. 17037–17048).
Lowe, R., Wu, Y., Tamar, A., Harb, J., Abbeel, O. P., & Mordatch, I. (2017). Multi-agent actor-critic for mixed cooperative-competitive environments. In Advances in neural information processing systems (pp. 6379–6390).
Foerster, J. N., Farquhar, G., Afouras, T., Nardelli, N., & Whiteson, S. (2018). Counterfactual multi-agent policy gradients. In Proceedings of the thirty-second AAAI conference on artificial intelligence.
Yang, Y., Luo, R., Li, M., Zhou, M., Zhang, W., & Wang, J. (2018). Mean field multi-agent reinforcement learning. In Proceedings of the 35th international conference on machine learning (pp. 5567–5576).
Stanley, H. E. (1971). Phase transitions and critical phenomena. Clarendon Press.
Sunehag, P., Lever, G., Gruslys, A., Czarnecki, W. M., Zambaldi, V., Jaderberg, M., Lanctot, M., Sonnerat, N., Leibo, J. Z., & Tuyls, K. (2018). Value-decomposition networks for cooperative multi-agent learning based on team reward. In Proceedings of the 17th international conference on autonomous agents and multiagent systems (pp. 2085–2087).
Rashid, T., Samvelyan, M., Witt, C. S., Farquhar, G., Foerster, J., & Whiteson, S. (2018). QMIX: Monotonic value function factorisation for deep multi-agent reinforcement learning. In Proceedings of the 35th international conference on machine learning (pp. 4292–4301).
Sukhbaatar, S., Szlam, A., & Fergus, R. (2016). Learning multiagent communication with backpropagation. In Advances in neural information processing systems (vol. 29, pp. 2244–2252).
Singh, A., Jain, T., & Sukhbaatar, S. (2019). Individualized controlled continuous communication model for multiagent cooperative and competitive tasks. In Proceedings of the 7th international conference on learning representations.
Zambaldi, V. F., Raposo, D., Santoro, A., Bapst, V., Li, Y., Babuschkin, I., Tuyls, K., Reichert, D. P., Lillicrap, T. P., Lockhart, E., Shanahan, M., Langston, V., Pascanu, R., Botvinick, M., Vinyals, O., & Battaglia, P. W. (2019). Deep reinforcement learning with relational inductive biases. In Proceedings of the 7th international conference on learning representations.
Tacchetti, A., Song, H. F., Mediano, P. A. M., Zambaldi, V.F., Kramár, J., Rabinowitz, N. C., Graepel, T., Botvinick, M., Battaglia, P. . (2019). Relational forward models for multi-agent learning. In Proceedings of the 7th international conference on learning representations.
Pachocki, J., Brockman, G., Raiman, J., Zhang, S., Pondé, H., Tang, J., Wolski, F., Dennison, C., Jozefowicz, R., Debiak, P., et al. (2018). OpenAI five, 2018. URL https://blog.openai.com/openai-five
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., & Klimov, O. (2017). Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347
Samvelyan, M., Rashid, T., de Witt, C. S., Farquhar, G., Nardelli, N., Rudner, T. G. J., Hung, C., Torr, P. H. S., Foerster, J. N., & Whiteson, S. (2019). The starcraft multi-agent challenge, pp. 2186–2188.
Suarez, J., Du, Y., Isola, P., & Mordatch, I. (2019). Neural MMO: A massively multiagent game environment for training and evaluating intelligent agents. arXiv preprint arXiv:1903.00784
Wang, W., Yang, T., Liu, Y., Hao, J., Hao, X., Hu, Y., Chen, Y., Fan, C., & Gao, Y. (2020). Action semantics network: Considering the effects of actions in multiagent systems. In Proceedings of the 8th international conference on learning representations.
Littman, M. L. (1994). Markov games as a framework for multi-agent reinforcement learning. In Proceedings of the Eleventh International Conference on Machine Learning (pp. 157–163).
Hansen, E. A., Bernstein, D. S., & Zilberstein, S. (2004). Dynamic programming for partially observable stochastic games. In Proceedings of the nineteenth national conference on artificial intelligence (pp. 709–715).
Watkins, C. J. C. H., & Dayan, P. (1992). Technical note Q-learning. Machine Learning, 8, 279–292.
van Hasselt, H., Guez, A., & Silver, D. (2016). Deep reinforcement learning with double Q-learning. In Proceedings of the thirtieth AAAI conference on artificial intelligence (pp. 2094–2100).
Anschel, O., Baram, N., & Shimkin, N. (2017). Averaged-DQN: Variance reduction and stabilization for deep reinforcement learning. In Proceedings of the 34th international conference on machine learning (pp. 176–185).
Bellemare, M. G., Dabney, W., & Munos, R. (2017). A distributional perspective on reinforcement learning. In Proceedings of the 34th international conference on machine learning (pp. 449–458).
Dabney, W., Rowland, M., Bellemare, M. G., & Munos, R. (2018). Distributional reinforcement learning with quantile regression. In Proceedings of the thirty-second AAAI conference on artificial intelligence (pp. 2892–2901).
Wang, Z., Schaul, T., Hessel, M., Hasselt, H., Lanctot, M., & Freitas, N. (2016). Dueling network architectures for deep reinforcement learning. In Proceedings of the 33rd international conference on machine learning (pp. 1995–2003).
Schaul, T., Quan, J., Antonoglou, I., & Silver, D. (2016). Prioritized experience replay. In Proceedings of the 4th international conference on learning representations.
Hessel, M., Modayil, J., van Hasselt, H., Schaul, T., Ostrovski, G., Dabney, W., Horgan, D., Piot, B., Azar, M. G., & Silver, D. (2018). Rainbow: Combining improvements in deep reinforcement learning. In Proceedings of the thirty-second AAAI conference on artificial intelligence (pp. 3215–3222).
Sosic, A., KhudaBukhsh, W. R., Zoubir, A. M., & Koeppl, H. (2017). Inverse reinforcement learning in swarm systems. In Proceedings of the 16th conference on autonomous agents and multiagent systems (pp. 1413–1421).
Oh, K.-K., Park, M.-C., & Ahn, H.-S. (2015). A survey of multi-agent formation control. Automatica, 53, 424–440.
Wang, W., Yang, T., Liu, Y., Hao, J., Hao, X., Hu, Y., Chen, Y., Fan, C., & Gao, Y. (2020). From few to more: Large-scale dynamic multiagent curriculum learning. In Proceedings of the AAAI conference on artificial intelligence (vol. 34, pp. 7293–7300).
Jiang, J., & Lu, Z. (2018). Learning attentional communication for multi-agent cooperation. In Advances in neural information processing systems (pp. 7254–7264).
Subramanian, S. G., Taylor, M. E., Crowley, M., & Poupart, P. (2021). Decentralized mean field games. arXiv preprint arXiv:2112.09099
Wolpert, D. H., & Tumer, K. (2001). Optimal payoff functions for members of collectives. Advances in Complex Systems, 4(2–3), 265–280.
Foerster, J. N., de Witt, C. A. S., Farquhar, G., Torr, P. H. S., Boehmer, W., & Whiteson, S. (2018). Multi-agent common knowledge reinforcement learning. arXiv preprint arXiv:1810.11702
Du, Y., Han, L., Fang, M., Liu, J., Dai, T., & Tao, D. (2019). LIIR: Learning individual intrinsic reward in multi-agent reinforcement learning. In Advances in neural information processing systems (pp. 4405–4416).
Son, K., Kim, D., Kang, W. J., Hostallero, D., & Yi, Y. (2019). QTRAN: Learning to factorize with transformation for cooperative multi-agent reinforcement learning. In Proceedings of the 36th International Conference on Machine Learning (pp. 5887–5896).
Rashid, T., Farquhar, G., Peng, B., & Whiteson, S. (2020). Weighted QMIX: Expanding monotonic value function factorisation for deep multi-agent reinforcement learning. In Advances in neural information processing systems.
Yang, Y., Hao, J., Liao, B., Shao, K., Chen, G., Liu, W., & Tang, H. (2020). Qatten: A general framework for cooperative multiagent reinforcement learning. arXiv preprint arXiv:2002.03939
Wang, J., Ren, Z., Liu, T., Yu, Y., & Zhang, C. (2021) QPLEX: Duplex dueling multi-agent Q-learning. In Proceedings of the International Conference on Learning Representations.
Panait, L., Luke, S., & Wiegand, R. P. (2006). Biasing coevolutionary search for optimal multiagent behaviors. IEEE Transactions on Evolutionary Computation, 10(6), 629–645.
Mahajan, A., Rashid, T., Samvelyan, M., & Whiteson, S. (2019). MAVEN: Multi-agent variational exploration. In Advances in neural information processing systems (pp. 7611–7622).
Wang, T., Wang, J., Wu, Y., & Zhang, C. (2020). Influence-based multi-agent exploration. In Proceedings of the 8th international conference on learning representations.
Yoo, B., Ningombam, D. D., Yi, S., Kim, H. W., Chung, E., Han, R., & Song, H. J. (2022). A novel and efficient influence-seeking exploration in deep multiagent reinforcement learning. IEEE Access, 10, 47741–47753.
Pieroth, F. R., Fitch, K., & Belzner, L. (2022). Detecting influence structures in multi-agent reinforcement learning systems.
Hu, S., Zhu, F., Chang, X., & Liang, X. (2021). UPDeT: Universal multi-agent RL via policy decoupling with transformers. In proceedings of the 9th international conference on learning representations.
Zhou, T., Zhang, F., Shao, K., Li, K., Huang, W., Luo, J., Wang, W., Yang, Y., Mao, H., Wang, B., & Li, D. (2021). Cooperative multi-agent transfer learning with level-adaptive credit assignment. arXiv preprint arXiv:2106.00517
Chai, J., Li, W., Zhu, Y., Zhao, D., Ma, Z., Sun, K., & Ding, J. (2021). UNMAS: Multiagent reinforcement learning for unshaped cooperative scenarios. IEEE Transactions on Neural Networks and Learning Systems. https://doi.org/10.1109/TNNLS.2021.3105869
Wang, T., Gupta, T., Mahajan, A., Peng, B., Whiteson, S., & Zhang, C. (2021). RODE: Learning roles to decompose multi-agent tasks. In Proceedings of the international conference on learning representations.
Cao, J., Yuan, L., Wang, J., Zhang, S., Zhang, C., Yu, Y., & Zhan, D. (2021). LINDA: Multi-agent local information decomposition for awareness of teammates. arXiv preprint arXiv:2109.12508
Hao, X., Wang, W., Mao, H., Yang, Y., Li, D., Zheng, Y., Wang, Z., & Hao, J. (2022). API: Boosting multi-agent reinforcement learning via agent-permutation-invariant networks. arXiv preprint arXiv:2203.05285
Palmer, G., Tuyls, K., Bloembergen, D., & Savani, R. (2018). Lenient multi-agent deep reinforcement learning. In Proceedings of the 17th international conference on autonomous agents and MultiAgent systems (pp. 443–451).
Gupta, J. K., Egorov, M., & Kochenderfer, M. (2017). Cooperative multi-agent control using deep reinforcement learning. In Proceedings of the 16th international conference on autonomous agents and multiagent systems, workshops (pp. 66–83).
David, H., Andrew, D., & Quoc, V. (2016). Hypernetworks. arXiv preprint arXiv 1609.
Tampuu, A., Matiisen, T., Kodelja, D., Kuzovkin, I., Korjus, K., Aru, J., Aru, J., & Vicente, R. (2017). Multiagent cooperation and competition with deep reinforcement learning. PloS one, 12(4), 0172395.
Moritz, P., Nishihara, R., Wang, S., Tumanov, A., Liaw, R., Liang, E., Elibol, M., Yang, Z., Paul, W., & Jordan, M.I. (2018). Ray: A distributed framework for emerging AI applications. In Proceedings of the 13th USENIX symposium on operating systems design and implementation (OSDI 18) (pp. 561–577).
Wu, Y., Mansimov, E., Grosse, R. B., Liao, S., & Ba, J. (2017). Scalable trust-region method for deep reinforcement learning using Kronecker-factored approximation. In Advances in Neural Information Processing Systems (vol. 30, pp. 5279–5288).
Mnih, V., Badia, A. P., Mirza, M., Graves, A., Lillicrap, T. P., Harley, T., Silver, D., & Kavukcuoglu, K. (2016) Asynchronous methods for deep reinforcement learning. In Proceedings of the 33nd international conference on machine learning (pp. 1928–1937).
Yu, C., Velu, A., Vinitsky, E., Wang, Y., Bayen, A. M., & Wu, Y. (2021). The surprising effectiveness of MAPPO in cooperative, multi-agent games. arXiv preprint arXiv:2103.01955
Sarafian, E., Keynan, S., & Kraus, S. (2021). Recomposing the reinforcement learning building blocks with hypernetworks. In International Conference on Machine Learning (pp. 9301–9312). PMLR.
Fu, J., Kumar, A., Soh, M., & Levine, S. (2019). Diagnosing bottlenecks in deep Q-learning algorithms. In International Conference on Machine Learning (pp. 2021–2030).
Andrychowicz, M., Raichuk, A., Stanczyk, P., Orsini, M., Girgin, S., Marinier, R., Hussenot, L., Geist, M., Pietquin, O., Michalski, M., Gelly, S., & Bachem, O. (2021). What matters for on-policy deep actor-critic methods? A large-scale study. In Proceedings of the 9th international conference on learning representations.
NetEase: Justice Online. (2018). https://n.163.com/index.html, https://www.mmobomb.com/news/netease-looks-to-bring-justice-online-west-this-year
Espeholt, L., Soyer, H., Munos, R., Simonyan, K., Mnih, V., Ward, T., Doron, Y., Firoiu, V., Harley, T., & Dunning, I. (2018). IMPALA: Scalable distributed Deep-RL with importance weighted actor-learner architectures. In International conference on machine learning (pp. 1407–1416).
Acknowledgements
This work is supported by the Major Program of the National Natural Science Foundation of China(Grant No. 92370132) and the National Key R&D Program of China (Grant No. 2022ZD0116402). Part of this work has taken place in the Intelligent Robot Learning (IRL) Lab at the University of Alberta, which is supported in part by research grants from the Alberta Machine Intelligence Institute (Amii); a Canada CIFAR AI Chair, Amii; Compute Canada; Huawei; Mitacs; and NSERC.
Author information
Authors and Affiliations
Contributions
TY wrote the main manuscript text. WW and TY prepared all experimental results. All authors reviewed the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix A: environmental settings
1.1 A.1 StarCraft II
State Description In StarCraft II, we follow the settings of previous works [15, 22]. The local observation of each agent is drawn within their field of view, which encompasses the circular area of the map surrounding units and has a radius equal to the sight range. Each agent receives as input a vector consisting of the following features for all units in its field of view (both allied and enemy): distance, relative x, relative y, and unit type. More details can be found at https://github.com/wwxFromTju/ASN_cloud or https://github.com/oxwhirl/smac.
1.2 A.2 Neural MMO
State Description In a 10 × 10 tile (where each tile can be set as different kinds, e.g., rocks, grass), there are two teams of agents (green and red), each of which has 3 agents. At the beginning of each episode, each agent appears on any of the 10 × 10 tiles. The observation of an agent is in the form of a 43-dimensional vector, in which the first 8 dimensions are: time to live, HP, remaining foods (set 0), remaining water (set 0), current position (x and y), the amount of damage suffered, frozen state (1 or 0); the rest of 35 dimensions are divided equally to describe the other 5 agents’ information. The first 14 dimensions describe the information of 2 teammates, followed by the description of 3 opponents’ information. Each observed agent’s information includes the relative position (x and y), whether it is a teammate (1 or 0), HP, remaining foods, remaining water, and the frozen state.
Each agent chooses an action from a set of 14 discrete actions: stop, move left, right, up or down, and three different attacks (“Melee”, the attack distance is 2, the damage is 5; “Range”, the attack distance is 4, the damage is 2; “Mage”, the attack distance is 10, the damage is 1) against one of the three opponents.
Each agent gets a penalty of \(-0.1\) if the attack fails. They get a \(-0.01\) reward for each tick and a \(-10\) penalty for being killed. The game ends when a group of agents dies or the time exceeds a fixed period, and agents belonging to the same group receive the same reward, which is the difference of the total number of HPs between itself and its opposite side.
Appendix B: Network structure and parameter settings
1.1 B.1 StarCraft II
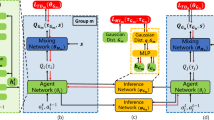
Network Structure The details of different network structures for StarCraft II are shown in Fig. 19. The vanilla network (Fig. 19a) of each agent i contains two fully-connected hidden layers with 64 units and one GRU layer with 64 units, taking \(o_t^i\) as input. The output layer is a fully-connected layer that outputs the Q-values of each action. The attention network (Fig. 19b) of each agent i contains two isolated fully-connected layers with 64 units, taking \(o_t^i\) as input and computing the standard attention value for each dimension of the input. The following hidden layer is a GRU with 64 units. The output contains the Q-values of each action. The entity-attention network (Fig. 19c) is similar to that in Fig. 19b, except that the attention weight is calculated on each \(o_t^{i,j}\). The dueling network (Fig. 19d) is the same as vanilla except for the output layer that outputs the advantages of each action and also the state value. Our homogeneous ASN (Fig. 19e) of each agent i contains two sub-modules, one is the \(O2A^i\) which contains two fully-connected layers with 32 units, taking \(o_t^i\) as input, followed by a GRU layer with 32 units; the other is a parameter-sharing sub-module which contains two fully-connected layers with 32 units, taking each \(o_t^{i,j}\) as input, following with a GRU layer with 32 units; the output layer outputs the Q-values of each action.

Various network structures on a StartCraft II 8m map
Parameter Settings Here we provide the hyperparameters for StarCraft II as shown in Table 4, more details can be found at https://github.com/wwxFromTju/ASN_cloud.
1.2 Neural MMO
Network structure The details of vanilla, attention, and entity-attention networks for Neural MMO are shown in Fig. 20a–c which contains an actor network, and a critic network. All actors are similar to those for StarCraft II in Fig. 19, except that the GRU layer is excluded and the output is the logic probability of choosing each action. All critics are the same as shown in Fig. 20a. Since in Neural MMO, each agent has multiple actions that have a direct influence on each other agent, i.e., three kinds of attack actions, we test two kinds of ASN variants: one (Fig. 20d) is the Multi-action ASN we mentioned in the previous section that shares the first layer parameters among multiple actions; the other (Fig. 20e) is the basic homogeneous ASN that does not share the first layer parameters among multiple actions.

Various network structures on Neural MMO
Parameter settings Here we provide the hyperparameters for Neural MMO shown in Table 5.
Appendix C: Environmental results
The following results present the performance of QMIX-ASN and vanilla QMIX under different StarCraft II maps by adding the manual rule (forbids the agent to choose the invalid actions) (Fig. 21).

Win rates of QMIX-ASN and vanilla QMIX on 5 m and 8 m StarCraft II maps
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Yang, T., Wang, W., Hao, J. et al. ASN: action semantics network for multiagent reinforcement learning. Auton Agent Multi-Agent Syst 37, 45 (2023). https://doi.org/10.1007/s10458-023-09628-3
Accepted:
Published:
DOI: https://doi.org/10.1007/s10458-023-09628-3