
Abstract
For a long time, experimental studies have been performed in a large number of fields of AI, specially in machine learning. A careful evaluation of a specific machine learning algorithm is important, but often difficult to conduct in practice. On the other hand, simulation studies can provide insights on behavior and performance aspects of machine learning approaches much more readily than using real-world datasets, where the target concept is normally unknown. Under decision tree induction algorithms an interesting source of instability that sometimes is neglected by researchers is the number of classes in the training set. This paper uses simulation to extended a previous work performed by Leo Breiman about properties of splitting criteria. Our simulation results have showed the number of best-splits grows according to the number of classes: exponentially, for both entropy and twoing criteria and linearly, for gini criterion. Since more splits imply more alternative choices, decreasing the number of classes in high dimensional datasets (ranging from hundreds to thousands of attributes, typically found in biomedical domains) can help lowering instability of decision trees. Another important contribution of this work concerns the fact that for \(<\)5 classes balanced datasets are prone to provide more best-splits (thus increasing instability) than imbalanced ones, including binary problems often addressable in machine learning; on the other hand, for five or more classes balanced datasets can provide few best-splits.




Similar content being viewed by others

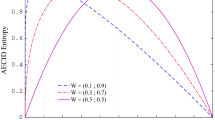

Notes
Impurity functions \(\phi (\mathbf p )\) must obey three properties: (i) it is convex in \(\mathbf p \); (ii) its maximum is achieved when all \(p_j=1/J\), and (iii) its minimum is achieved when one \(p_i=1\), and therefore all other \(p_j=0\) for all \(j \ne i\). Refer to Breiman et al. (1984) for more details.
Since the problem is symmetric for \(P_L\) and \(P_R\), a maximum for \({\alpha }\) is also a maximum for its complement.
Outliers are defined as any points larger than \(Q3+1.5(Q3-Q1)\) or lower than \(Q1-1.5(Q3-Q1)\), where \(Q1\) and \(Q3\) represent first and third quartiles, respectively.
References
Batista GEAPA, Prati RC, Monard MC (2004) A study of the behavior of several methods for balancing machine learning training data. SIGKDD Explor Newsl 6(1):20–29
Bousquet O, Elisseeff A (2002) Stability and generalization. J Mach Learn Res 2:499–526
Breiman L (1996a) Heuristics of instability and stabilization in model selection. Ann Stat 24(6):2350–2383
Breiman L (1996b) Technical note: some properties of splitting criteria. Mach Learn 24(1):41–47. doi:10.1023/A:1018094028462
Breiman L, Friedman J, Olshen R, Stone C (1984) Classification and regression tress. Wadsworth & Books, Pacific Grove, CA
Domingos P (1999) MetaCost: a general method for making classifiers cost-sensitive. ACM, San Diego, CA
Gamberger D, Lavrač N, Zelezný F, Tolar J (2004) Induction of comprehensible models for gene expression datasets by subgroup discovery methodology. J Biomed Inform 37(4):269–284
Li RH, Belford GG (2002) Instability of decision tree classification algorithms. In: Proceedings of the eighth ACM SIGKDD international conference on knowledge discovery and data mining, pp 570–575. ACM, New York, NY, USA, KDD ’02. doi:10.1145/775047.775131. http://doi.acm.org/10.1145/775047.775131
Perez PS, Baranauskas JA (2011) Analysis of decision tree pruning using windowing in medical datasets with different class distributions. In: Proceedings of the ECML PKDD workshop on knowledge discovery in health care and medicine (European conference on machine learning and principles and practice of knowledge discovery in databases), pp 28–39. Athens, Greece, ECML PKDD KD-HCM 2011. http://www.cs.gmu.edu/~hrangwal/kd-hcm/proc/papers/3-Perez-Baranauskas.pdf
Polo JL, Berzal F, Cubero JC (2008) Class-oriented reduction of decision tree complexity. In: Proceedings of the 17th international conference on foundations of intelligent systems, pp 48–57. Springer, Berlin, Heidelberg, ISMIS’08. http://portal.acm.org/citation.cfm?id=1786474.1786481
Quinlan JR (1993) C4.5: programs for machine learning. Morgan Kaufmann, San Francisco, CA
Rosenfeld N, Aharonov R, Meiri E, Rosenwald S, Spector Y, Zepeniuk M, Benjamin H, Shabes N, Tabak S, Levy A et al (2008) Micrornas accurately identify cancer tissue origin. Nat Biotechnol 26(4):462–469
Souto M, Bittencourt V, Costa J (2006) An empirical analysis of under-sampling techniques to balance a protein structural class dataset. In: King I, Wang J, Chan L, Wang D (eds) Neural information processing, Lecture notes in computer science, vol 4234, pp 21–29. Springer, Berlin. http://dx.doi.org/10.1007/11893295_3
Weiss GM, Provost F (2003) Learning when training data are costly: the effect of class distribution on tree induction. J Artif Intell Res 19:315–354
Weiss SM, Indurkhya N, Zhang T, Damerau F (2004) Text mining: predictive methods for analyzing unstructured information. Springer, Berlin
Author information
Authors and Affiliations
Corresponding author
Additional information
Research founded by National Research Council (CNPq) and Foundation for Research Support of the State of Sao Paulo (FAPESP)
Rights and permissions
About this article
Cite this article
Baranauskas, J.A. The number of classes as a source for instability of decision tree algorithms in high dimensional datasets. Artif Intell Rev 43, 301–310 (2015). https://doi.org/10.1007/s10462-012-9374-7
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10462-012-9374-7