
Abstract
Cross-modal retrieval aims to correlate multimedia data by bridging the heterogeneity gap. Most cross-modal retrieval approaches learn a common subspace to project the multimedia data into the subspace for directly measuring the similarity. However, the existing cross-modal retrieval frameworks cannot fully capture the semantic consistency in the limited supervision information. In this paper, we propose a Cross-coupled Semantic Adversarial Network (CSAN) for cross-modal retrieval. The main structure of this approach is mainly composed of the generative adversarial network, i.e., each modality branch is equipped with a generator and a discriminator. Besides, a cross-coupled semantic architecture is designed to fully explore the correlation of paired heterogeneous samples. To be specific, we couple a forward branch with an inverse mapping and implement a weight-sharing strategy of the inverse mapping branch to the branch of another modality. Furthermore, a cross-coupled consistency loss is introduced to minimize the semantic gap between the representations of the inverse mapping branch and the forward branch. Extensive qualitative and quantitative experiments are conducted to evaluate the performance of the proposed approach. By comparing against the previous works, the experiment results demonstrate our approach outperforms state-of-the-art works.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
With the development of multimedia data, cross-modal retrieval especially image-text matching becomes a highlighted and novel research topic Shi et al. (2022). It takes one type of data as the query and returns the relevant data of another type to search for multi-modal data. Different data distribution spaces lead to heterogeneity gap between multimodal data, which makes it difficult to directly analyze visual and language correlation. The key challenge of the cross-modal retrieval task is to establish a common representation subspace to eliminate the heterogeneous gap (Park and Kim 2023; Perez-Martin et al. 2022).
In previous research, aiming to eliminate the modality gap, the traditional cross-modal retrieval approaches utilize linear projection and handcraft features to explore the correlation between multimodal data. However, large-scale multi-modal data is highly complex in practical retrieval applications, thus the linear projection is unable to capture the pairwise semantic association. Although several approaches such as Akaho (2006), Rupnik and Shawe-Taylor (2010) are devoted to solving the aforementioned problem by introducing the non-linear strategy, most of the traditional approaches fail to achieve satisfactory performance due to the limited correlation description ability (Yao et al. 2020; Yang et al. 2021).
Profit from the enormous neurons and nonlinear fitting ability, Deep neural network (DNN) Jing et al. (2021) achieves superior data description ability in many research topics including cross-modal retrieval. In recent years, DNN-based approaches Su et al. (2019), Yu et al. (2021), Zhang and Wu (2022, 2020) have modeled the cross-modal correlation by exploiting data driven iterative training, which aims to eliminate the semantic gap across heterogeneous data and improve retrieval accuracy. The powerful nonlinear learning ability of DNN is exploited in both the feature extraction stage and correlation learning stage, while several correlation learning strategies (e.g., adversarial learning) are gradually optimizing this typical paradigm (Zhang et al. 2021a, b, c). Although these methods have achieved satisfactory results, the semantic level information mining is still insufficient.
With the unique adversarial optimization principle and the significant cross-modal correlation learning ability, the Generative Adversarial Network (GAN) Goodfellow et al. (2014) is widely applied to cross-modal retrieval tasks. Most of the GAN-based cross-modal retrieval approaches design one generator and one discriminator for each modality (Ma et al. 2021; Xu et al. 2022). Feature representations of different modalities are input into the generators to learn cross-modal correlations. During the training stage, the generators confuse the discriminator while the discriminators conduct competitive training to assign the correct label to samples from the generators. By employing the minimax game strategy, the architecture eliminates the gap of multi-modality data. However, it is difficult to directly bridge the heterogeneity gap between cross-modal data using simple adversarial strategies.
Most of the existing GAN-based cross-modal retrieval algorithms are based on Conditional Generative Adversarial Networks (CGAN) Mirza and Osindero (2014) technology, that is, the generator obtains additional information (original feature representation) rather than noise vectors as conditions, so as to train cross-modal retrieval frameworks. Aiming to boost the performance on the domain adaptation task, a Cycle-Consistent Adversarial Networks (CycleGAN) Zhu et al. (2017) was proposed to learn a mapping G: \({{\textrm{I}}_x} \rightarrow {{\textrm{I}}_y}\) such that the distribution of samples from G (\({{\textrm{I}}_x}\)) is indistinguishable from the distribution Y employing an adversarial loss. To address the problem of highly under-constrained mapping, CycleGAN couples G with an inverse mapping F: \({{\textrm{I}}_y} \rightarrow {{\textrm{I}}_x}\) and designs a cycle consistency loss to expect F(G (\({{\textrm{I}}_x}\)))\(\approx {{\textrm{I}}_x}\), and vice versa.

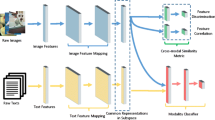
The framework of the proposed cross-coupled semantic adversarial network. The network is mainly composed of three parts: visual correlation learning branch (upper box), text correlation learning branch (bottom box) and cross-coupled semantic learning branch (red dashed box). For visual and text correlation learning branches, the architecture employs the mini-max game strategy to construct a common potential subspace. Moreover, in the training stage, the projected feature representations are fed into the Couple-generator which adopts the weight sharing strategy on the forward generator of the corresponding modality for further preserving the semantic discrimination and modal consistency
In this paper, we present a Cross-coupled Semantic Adversarial Network (CSAN) for cross-modal retrieval. Based on the GAN strategy, the generator transforms the sample representations to confuse the discriminators, as well as trains the discriminators to distinguish the modality. The framework is shown in Fig. 1. Inspired by CycleGAN, apart from learning a common mapping to eliminate the discrepancy of heterogeneous data, we also introduce an inverse mapping to learn the semantic consistency in the common potential subspace. Notably, the main purpose of CSAN is to constrain heterogeneity differences in common representations and learn semantic consistency across modal samples bidirectionally, rather than image domain transfer tasks. Aiming to follow the property of cycle-semantic consistency, this paper establishes one couple-generator and conducts a secondary mapping with the projected feature representations. The weight sharing strategy bridges the forward mapping generation process and the reverse mapping process of cross modal samples, so that the parameter updates of reverse learning can achieve cross-modal transfer. On one hand, the couple-generator attempts to enhance the modality consistency by exploiting the modality label information. On the other hand, the proposed strategy further preserves the robustness in the common potential subspace, that is, the projected feature representations in the common subspace still maintain the original representation features through reverse mapping. Therefore, the samples with similar semantics are compact even if the data comes from different modalities, while the samples with mutually exclusive semantics remain scattered. Generous experiments are verified to separately evaluate the performance with different components of the framework on three widely-used benchmark databases and the experimental results achieve state-of-the-art performance on the three databases.
The main contributions of this work are summarized as follows
-
We propose a cross-coupled semantic architecture with the adversarial learning strategy to preserve the semantic consistency in the common potential subspace. In this way, the proposed network not only learns modal discrimination through a single feed-forward sub-network, but also exploits the coupling network with inverse mapping to construct the semantic correlation.
-
We design an optimization strategy for the proposed coupled-generator architecture, which is formulated by multiple task-specific loss functions of the forward generators and cross-coupled consistency loss. By minimizing the loss functions in the training stage, the proposed CSAN pushes the mutilmedia data into a unified subspace, thereby eliminating semantic heterogeneity in multimodal samples.
-
Numerous experiments are conducted on three widely-used benchmark databases for ablation analysis and visualization analysis, which demonstrate the effectiveness of our proposed CSAN.
The rest of this paper is organized as follows: Sect. 2 briefly reviews the related work of this work. In Sect. 3, the proposed method is introduced in detail. The experiment is introduced in Sect. 4. And Sect. 5 is the conclusion of this work.
2 Related work
Most of the traditional cross-modal retrieval approaches project heterogeneous data into a common representation space for unified similarity measures. However, the performance of the traditional cross-modal retrieval approaches is limited by the single linear projection Rasiwasia et al. (2010); Zhang et al. (2017). Next, we will introduce the related work of this paper from two aspects: the research of deep learning based cross modal retrieval and the research of GAN based cross modal retrieval.
2.1 DNN based cross-modal retrieval method
As Deep Neural Network (DNN) has achieved state-of-the-art performance in numerous computer vision tasks, it has demonstrated its efficient data representation ability (Xie et al. 2022; Li et al. 2022). In the past decade, DNN was widely exploited in cross-modal correlation learning tasks to explore the complex nonlinear transformations of heterogeneous sample pairs. By employing labels as the supervised information, Kan et.al proposed a Multi-view Deep Network Analysis (MvDA) Kan et al. (2012) to model modality-specific linear transforms and project the heterogeneous data into a common space, where a Fisher’s loss was adopted to minimize modality discrepancy. Feng et.al proposed Correspondence autoencoder (Corr-AE) Feng et al. (2014) to combine autoencoder and correlation costs for joint correlation learning. Peng et al. presented a Cross-Media multiple Deep Network (CMDN) Peng et al. (2016) algorithm, which exploited the intra-media and inter-media information to get the separate representation of each media type and then hierarchically integrated the representation vectors to obtain the shared representations.
In addition, several approaches are devoted to exploring the rich complementary fine-grained information to improve the accuracy of the cross-modal retrieval task. For instance, a Modality-specific Cross-modal Similarity Measurement (MCSM) Peng et al. (2018) approach was proposed by constructing independent semantic spaces for each modality, which trained attention-based joint embedding with the attention weights to guide the fine-grained cross-modal correlation learning. Besides, the Cross-modal Correlation Learning (CCL) Peng et al. (2017a) approach preserved the complementary context with multi-grained fusion by employing a hierarchical network, as well as employed multi-level association with joint optimization by maximizing modality correlation. To match the visual and textual data in high-level semantics, UVCL Peng et al. (2020) was proposed to learn cross-media correlation by aligning the fine-grained visual local patches and textual keywords with fine-grained soft attention as well as semantic-guided hard attention. To fully exploit graph-structured semantics, a Weighted Graph-structured Semantics Constraint Network (WGSCN) Zhang et al. (2024a) was proposed by mining the semantic information in the dataset with discriminative representations. Su et al. proposed a semi-supervised approach Su et al. (2021) called semi-supervised knowledge distillation for cross-modal hashing, aiming to solve the problem of supervision methods relying on large-scale labeled cross-modal training data. Furthermore, Zhang et al. proposed a parallel weight control method based on Policy Gradient of Relationship Refinement (PGRR) Zhang et al. (2024b) for cross-modal retrieval, which utilized self-attention mechanism to model the relationship between any local features and all local features within the modality.
2.2 Generative adversarial networks
GANs Goodfellow et al. (2014) involve a dualistic competition between a generator and a discriminator network. The generator aims to produce samples that are indistinguishable from real data, while the discriminator evaluates the authenticity of these samples. This adversarial process refines both networks, with the generator learning to create more realistic outputs and the discriminator improving its ability to discern fakes from genuine data.
Building upon the foundation of GANs, CGANs Mirza and Osindero (2014) introduce conditioning variables to enable the generation of data with specific properties. This is particularly useful in scenarios where the generation process needs to be guided by certain inputs, such as labels or other auxiliary information. CGANs have been successfully applied in text-to-image synthesis, where the textual description acts as a condition for generating relevant images. Recent work has extended the capabilities of CGANs to handle continuous, scalar conditions, termed as regression labels, which present unique mathematical challenges and have led to the development of Continuous Conditional Generative Adversarial Networks (CcGANs) Ding et al. (2022).
CycleGANs Zhu et al. (2017) represent a significant departure from traditional GAN frameworks by enabling image-to-image translation without paired data. This is achieved through a cycle-consistent framework that preserves the content and style of images across different domains. CycleGANs have demonstrated efficacy in tasks such as style transfer and cross-modal image synthesis, where the model learns to translate images from one domain to another while maintaining the essential characteristics of the original images.
KTransGAN Azzam et al. (2020) includes a classification component that leverages labeled data to transfer knowledge and works in tandem with the conditional generator through a collaborative learning approach. With these strategies in place, KTransGAN can estimate the conditional distribution of unlabeled data and offer an innovative solution to challenges in unsupervised domain adaptation.
In summary, the evolution of GANs into CGANs and CycleGANs has expanded their applicability to more complex and diverse tasks. CGANs has ability to incorporate conditional information. In particular, CycleGANs, with their unpaired image translation capabilities, showcase the versatility and ongoing innovation in the field of generative adversarial networks. And the proposed method leverages the cycle-consistent strategy in CycleGANs to eliminate the heterogeneity gap in cross-modal data.
2.3 GAN based cross-modal retrieval method
In recent years, Generative Adversarial Networks (GAN) had been employed in the cross-modal retrieval task due to the distinctive iterative learning mechanism and superior correlation modeling ability (Cai et al. 2022; Zhang et al. 2022; Yang et al. 2022). Wang et al. proposed an Adversarial Cross-Modal Retrieval (ACMR) Wang et al. (2017) approach that maximized the distance between related samples with the adversarial learning strategy and the triplet constraint. Moreover, a Cross-modal Generative adversarial Network (CM-GAN) Peng and Qi (2019) was proposed to correlate the multi-media data across distinct modalities by utilizing both weight-sharing and semantic constraint strategies. To avoid the discriminant function overemphasizing the large distances between already separated classes, Hu et al. proposed Multimodal Adversarial Network (MAN) Hu et al. (2019a) for cross-modal retrieval. It employed an eigenvalue strategy to weaken the dominant eigenvalues and emphasize the minor ones, thereby preserving more discriminative features in the common subspace. By jointly leveraging both modality-specific and shared features for cross-modal retrieval, the modality-specific and shared generative adversarial network (\(\hbox {MS}^{2}\)GAN) Wu et al. (2020) was proposed to model the inter-modal and intra-modal similarity with label information and capture the complex correlation in multimodal information.
Aiming at addressing real-world educational scenarios, Li et al. presented a novel framework (EduCross) Li et al. (2024) to enhance CMR within multimodal educational slides. EduCross utilized the capabilities of generative adversarial networks with figure-text dual channels by integrating dual adversarial bipartite hypergraph learning. Li et al. proposed an Adaptive Adversarial Learning (AAL) Li et al. (2023a) based cross-modal retrieval method to fully explore potential semantic information with GAN-based cross-modal learning framework. To improve the accuracy of cross-modal retrieval tasks and achieve flexible retrieval between different modalities, He et al. proposed a Dual Discriminant Adversarial Cross-modal Retrieval (DDAC) He et al. (2023) method in this paper. DDAC integrated adversarial learning and label information into the overall algorithm, which eliminated the same semantic heterogeneity between modalities by maintaining the distinguishability of different semantic features between modalities.
To solve the problem of semantic consistency in most existing GAN-based methods, this paper proposes a Cross-coupled Semantic Adversarial Network to eliminate the heterogeneity gap in pairwise instances and improve discrimination in common space. However, training stability in Generative Adversarial Networks (GANs) has been a significant challenge since their inception. In fact, the generative adversarial mechanism adopted in cross modal retrieval is different from the GAN network used in tasks such as image translation. The adversarial mechanisms in these cross-modal retrieval methods train representation data processing rather than the original pixel data of the image. Therefore, issues such as mode collapse have been significantly alleviated.
3 Cross-coupled semantic adversarial network
3.1 Revisit GAN-based cross-modal retrieval model
Let \({\mathop {\textbf{X}}\nolimits } = \{ {{\textbf{X}}_I} = [{{\textbf{i}}_1}, \cdot \cdot \cdot,{{\textbf{i}}_n}],{{\textbf{X}}_T} = [{{\textbf{t}}_1}, \cdot \cdot \cdot,{{\textbf{t}}_n}]\}\) represents the input image-text sample matrix in the model, where n is the number of sample pairs in the database. In this paper, the generator \({G_m}\) and the discriminator \({D_m}\) of a specific modality m are exploited to conduct the minimax game, as well as the couple-generator \(G_m^c\) for a secondary optimization. The features projected into the common subspace (generated from the \({G_m}\) and generated from the couple-generator \(G_m^c\)) are represented as \({\textbf{Y}} = \{ {{\textbf{Y}}_I} = [\textbf{y}_1^I, \cdot \cdot \cdot,\textbf{y}_n^I],{{\textbf{Y}}_T} = [\textbf{y}_1^T, \cdot \cdot \cdot,\textbf{y}_n^T]\}\) and \({{\mathop {{\textbf{Y}}}\nolimits } _c} = \{ {\textbf{Y}}_I^c,{\textbf{Y}}_T^c\}\), respectively. The semantic label is denoted as \({{\textbf{l}}_s}\). \({{\textbf{l}}_m}\) is the modality label for discriminators and \({{\bar{l}}_m}\) performs the fake modality label for generators, which are both exploited to guide the adversarial learning in our architecture. The one-hot binary vectors \({{\textbf{l}}_m}\) and \({\bar{\textbf{l}}_m}\) are denoted as
3.2 The architecture of the cross-coupled semantic adversarial network
Generally, most cross-modal retrieval approaches learn a common potential subspace, so that the multi-media data could be projected into the uniform space for correlation measurement (Cheng et al. 2022; Shu et al. 2022). In this paper, on one hand, our goal is to bridge the gap between correlated heterogeneous data pairs that are projected into the common space (as shown in Fig. 2). Moreover, aiming to convey the semantic consistency in the common subspace, the projected data representations are inverting fed into the modality space, which expected the inverse mapping instances and the original instances to be more compact. On the other hand, we attempt to preserve the semantic discriminant in the learned common subspace, i.e., instances with the same semantics are compact, while instances with different semantics are scattered, even though they come from different modality spaces.

Most specifically, the mechanism of CSAN is trained to learn two auto-encoders for each modality: one is the forward mapping \({G_m}\) and the other one is the inverse mapping \(G_m^c\). By employing the weight sharing strategy, the image forward mapping \({G_I}\) is coupled with the text inverse mapping \(G_T^c\), and vice versa. In this way, the cross-modal correlation learning task can be considered as the translation process between modalities. Therefore, the CSAN not only learns the modality invariance and semantic discrimination in the forward translation process, but also emphasizes the cross semantic consistency in the reverse translation process, so as to further bridge the heterogeneity gap of multi-modal data information. In the following section, we will introduce three task-specific loss functions for model optimization.
3.3 Modality-specific generators
With the unique adversarial mechanism, the proposed CSAN is devoted to training the generator for mapping the instances compact across different modalities, so that the generator is able to deceive discriminators about modality attribution. Meanwhile, the discriminators are also trained to distinguish the correct category of the corresponding representation.
3.3.1 Modality approximate loss
To eliminate the modality gap between the multimedia data, the modality approximate loss is proposed with the minimax game. The modality approximate loss is introduced to optimize the specific generator which is shown as
here \(\Vert \cdot {\Vert _2}\) is the \({\ell _2}\)-norm. We utilize the fake modality label \({\bar{\textbf{l}}_m}\) as label information to supervise the learning of loss function, thereby the generators are trained deceptive to map the pairwise heterogeneous data in the common subspace more approximate.
3.3.2 Semantic discriminative loss
Specific embedding methods are employed for multi-modal feature extraction before the GAN-based cross-modal learning framework in this paper. Therefore, the extracted features are semantically discriminative, i.e., the features are superior for classification. To avoid the destruction of the semantic discrimination that originally exist in the feature representation during the cross-modal correlation learning, we introduce the semantic discriminative loss, which is designed in the forward generators. The specific loss is formulated as
where \(\mathbb {R}( \cdot {\vert _{predict}})\) indicates the prediction transformation of the category label and \(\Vert \cdot {\Vert _F}\) indicates the Frobenius norm. By employing the \({{{\mathcal {L}}}_s}\) loss, the proposed CSAN minimizes the difference between the predicted category label output from the last linear classification layer of the forward generator and the real category label, as well as preserves the semantic discrimination in the learned potential common subspace.
3.3.3 Correlation discrimination loss
In the common subspace, a superior data distribution system should be discriminative, that is, the instance vectors with the same semantics should be approximate whether they come from the same representation space or not. On the contrary, data with different semantics is scattered, which avoids the interference of the data distribution (as shown in Fig. 1).
We calculate the loss function for three tasks, the distribution gap of image features, the distribution gap of text features and the distribution gap of cross-modal features. As mentioned above, the scores of the three tasks are expected to be small if the two elements are the vectors of intra-semantic-class samples, while large if not. Therefore, we maximize the likelihood function to compress the sample pairs under the same semantic category and the cosine distance is exploited to represent three distribution measurement tasks of the related samples such as cos(\(\textbf{v}_1\), \(\textbf{v}_2\)), which is defined as
where \(S( \cdot )\) is the sigmoid function. sgn(\(\cdot\)) is the indicator function that the value is 1 if the input sample pairs under the same semantic category, otherwise 0. To facilitate the optimization of target loss, the likelihood function is represented by the negative log-likelihood function.
Noted that, Eq. 5 aims to conditionally minimize the cosine distance of \(\textbf{v}_1\) and \(\textbf{v}_2\). Thus the loss function is formulated as
For the three optimization tasks about inter-modalities and intra-modalities (minimizing cos(\(\textbf{y}_j^I\), \(\textbf{y}_k^T\)), cos(\(\textbf{y}_j^I\), \(\textbf{y}_k^I\)) and cos(\(\textbf{y}_j^T\), \(\textbf{y}_k^T\)), we summarize the three tasks by employing the loss optimization strategy and formulate the correlation discrimination loss to evaluate the distribution of the feature representations in common space. The loss is shown as
here the hyper-parameter \(\chi\) controls the contributions of \({\ell _r}\), and \({\ell _r}\) is a constraint that is introduced into CSAN to enforce the modality consistency of the multiple linear transforms. And \({\ell _r}\) is formulated as
Different from \({{\mathcal {L}}}({{\textbf{v}}_j},{{\textbf{v}}_k})\), the loss \({\ell _r}\) not only minimizes the discrepancy between pairwise samples, but also eliminates the gap between unpaired samples with similar semantics. Therefore, the proposed CSAN further pushes multi-modality discrimination into the potential common subspace. Overall, the loss function for the forward generators is shown as
In Eq. 9, the hyper-parameters \(\alpha\) and \(\beta\) are set to guarantee different loss functions within the same magnitude.
3.4 Cross-coupled semantic architecture
In this paper, the cross-coupled semantic architecture is presented mainly to learn two mapping functions, so that the ‘style’ information between different modality domains can transfer to each other. As illustrated in Fig. 3, the proposed cross-coupled semantic architecture is equipped with one forward generator \({G_m}\) and one couple-generator \(G_m^c\).

Cross-coupled semantic architecture. The scaling operation indicates that the dimension of the forward generator and the coupling generator are matched by exploiting a single linear layer to scale the representations
In the proposed CSAN, the learned mapping functions are trained to be cycle-consistent, that is, the mapped representations \(\textbf{X}\) from one forward generator should carry abundant domain information from another modality, while the other modality generator should also be able to bring these representations \(\textbf{X}\) backward to the original modality representations. By employing the weight sharing strategy, the couple-generator and the corresponding modality forward generator unify the learned parameters for learning the potential common subspace. The cross-coupled consistency loss for the aforementioned strategy will be introduced in the following.
To further preserve the semantic discrimination in the mapping functions of coupled architecture, the semantic loss is defined as
where \(\mathbb {R}_o^c( \cdot {\vert _{predict}})\) is the coupled prediction transformation of the category label. In addition, the representation consistent is also considered as
In Eq. 11, \(\Vert \cdot {\Vert _1}\) indicates the L1-norm. There are two terms consisted in Eq. 11, which are employed to transfer domain information from one modality to another modality. In the first term, the forward mapped multimedia data vectors are fed into \(G_m^c\) the for a secondary optimization. Similarly, the second term follows the backward semantic consistency strategy to eliminate the gap in the feature representations generated by the forward generator and coupled generator. By integrating the two losses, the cross-coupled consistency loss is formulated as
With the cross-coupled optimization strategy, knowledge across modalities is transferred to each other and ensured that the complementarity information in multi-modal data is effectively explored as well.
Overall, the final objective function of generators in the CSAN is presented as
3.5 Discriminator of the specific modality
Most of the GAN-based approaches are equipped with discriminators for training against generators which attempt to distinguish the modal label in adversarial strategy. In CSAN, due to the high consistency and overlapping of redundant discriminator training, each modality has one unified discriminator for both forward generators and coupled generators. The architecture of the discriminator is mainly composed of the Fully Connected layer (FC layer) and the activation layer. To minimize discrimination error, the loss function of the discriminator can be formulated as
Worth noting that the loss is similar to the modality approximate loss while the modality supervision label is the opposite, i.e., true modality label in discriminator and fake modality label in generator. This is because the main purpose of the discriminator loss function is to narrow the modality difference between the generated representation and the original data in the projection process, thereby improving the discriminant consistency in the potential subspace.
By utilizing the optimization strategy of the generators and discriminators for the min-max game, our CSAN eliminates the heterogeneous modality discrepancy. The overall training process is summarized as Algorithm 1.

The optimization algorithm for the proposed CSAN
4 Experiments
To comprehensively investigate the effectiveness of our CSAN, several experiments are conducted on three widely-used databases.
4.1 Databases
In this paper, we evaluate the proposed CSAN approach on three widely-used benchmark cross-modal databases: Pascal Sentence Rashtchian et al. (2010), PKU XMedia Peng et al. (2015), Zhai et al. (2013) and PKU XMediaNet Peng et al. (2017b, 2018) databases. The illustrations of the databases are as follows.
Pascal sentence database is a common database for cross-modal retrieval which is selected from the 2008 PASCAL development kit (Everingham and Winn 2010, Everingham et al. 2010). The database is composed of 1000 image-text pairs with 20 semantic categories such as bird, horse, sofa, and so on. Each image instance corresponds to five independent sentences, and the corresponding cross-modal instances are semantically related. The partition strategy of the database is set as 800 image-text instances for training, 100 image-text instances for testing and 100 image-text instances for validation.
PKU XMedia database contains 5000 texts, 5000 images, 1143 videos, 1000 audio clips and 500 3D models which are crawled from famous websites on the internet such as Flickr, YouTube, etc. The database is divided into 20 categories including insects, wolves, horses and so on. In the experimental part, we employed the image and text modalities to evaluate the performance of the algorithm. Finally, we follow the partition strategy in Huang et al. (2018), Peng and Qi (2019) to set the 8,000 instances (4000 texts, 4000 images) as the training subset and 2000 instances (1000 texts, 1000 images) as the testing subset.
PKU XMediaNet database contains 40,000 images, 40,000 texts, 10,000 videos, 10,000 audios, and 2000 3D models. As a large-scale dataset designed for cross-media retrieval, the dataset can further verify the effectiveness of the algorithm. The database contains 20 different multimedia types. Similar to the XMedia database, only image modality and text modality are exploited to evaluate our proposed methods. XMediaNet is divided into training subset (32,000 pairs), validation subset (4000 pairs) and testing sets (4000 pairs) as Hu et al. (2019b), Zhen et al. (2019).
4.2 Evaluation metric
As most of the cross-modal retrieval approaches performed, Mean Average Precision (MAP) and Precision-Recall curve (PR curve) are employed to evaluate our CSAN against several existing baselines. MAP is the main score criterion to investigate quantitative experiments. Given a query instance Q, we calculate and obtain a ranking list of \({N_R}\) retrieved results with the cosine similarity, where the Average Precision (AP) is defined as
where R is the number of semantically related instances of Q. p(r) denotes the precision score of the top r returned instances. Here the is an indicator function. \(\delta (r)\)=1 if the rth returned instance is the semantically relevant instance with the Q, otherwise \(\delta (r)\)=0. By calculating the mean value of the AP, the MAP with \({N_Q}\) query instances is denoted as
In addition, the MAP results are reported on two specific tasks: retrieval text instances through image query instance (I2T), and retrieval image instances through text query instance (T2I). Generally, MAP reflects the discrimination ability of correlation between heterogeneous instances, thereby a higher MAP score means a superior retrieval performance. For the number of returned instances r, we have set two criteria according to the previous work Hu et al. (2019a). Except for calculating the MAP score of all search results in the ranking list, we also calculate the MAP scores by returning the top 50 ranked instances to further explore the performance of the method. Thus, the two tasks (i.e.,\({N_R}\)=50 and \({N_R}\)=ALL) are shown in the quantitative experiment section and ablation analysis section. The PR curve is exploited to intuitively visualize and evaluate the performance of the competitive approaches in the quantitative experiment section.
4.3 Implementation details
4.3.1 Embedding architecture
In this section, the specific setting of our model and the hyper-parameters are discussed in detail. Since the proposed CSAN approach is conducted to investigate the correlation between image and text modalities, we will introduce these two modalities respectively. For embedding strategy, the image modality exploits the VGG19 network Gu et al. (2018), Ma et al. (2020) to extract the image representation vector which is outputted by the fc7 layer of the VGG19 model. And we utilize the pre-trained weight parameter on ImageNet to initialize the image embedded model. Text modality adopts the Word2vec technology to extract a 300-dimensional representation vector for each text sample, which is pre-trained on billions of words in Google News. Moreover, the representation vectors of the text samples on the XMedia database are embedded by the 3000-dimensional Bag-of-Word Jin et al. (2016) vectors. Furthermore, for all the databases, the generators of both two modalities are equipped with two fully connected layers and each of the layers follows one ReLU layer. The number of hidden units for the two layers is 2048. The discriminators are equipped with one fully connected layer and one ReLU layer. The number of hidden units for the layer is 2048.
4.3.2 Hyper-parametric analysis
In Sect. 3.3.3, three hyper-parameters, i.e., \(\alpha\), \(\beta\) and \(\chi\) are employed to guarantee different loss functions within the same magnitude. To investigate the impact of the parameter in Eqs. 7 and 9, we conduct experiments to tune the hyper-parameters on validation sets. By analyzing the range of the hyper-parameters in which the performance will be affected, \(\alpha\) is set ranging from 0 to 5 with an increment by 0.5 and \(\beta\) is set ranging from \(10^{-5}\) to 1 with an equal ratio of 10. Figure 4 shows the average retrieval MAP scores by adjusting the hyper-parameters \(\alpha\) and \(\beta\) on the Pascal Sentence database and XMediaNet database.

Parameter analysis. Comparison of average MAP scores for different \(\alpha\) and \(\beta\) values on the validation set of pascal sentence database

Parameter analysis on pascal sentence and XMediaNet databases
From the experiments, it can be seen that the average MAP scores of our approach are impacted by both the two hyper-parameters \(\alpha\) and \(\beta\). And the results indicate that the hyper-parameter performs well in controlling the magnitude of the loss function \({{{\mathcal {L}}}_C}\) and forces it suitable for model optimization. The MAP scores are superior to other settings when \(\beta\)=\(10^{-4}\). Based on the value of \(\beta\), we can find that the MAP achieves the best performance when \(\alpha\) reaches 1.5. Therefore, we set \(\alpha\)=1.5 and \(\beta\)=\(10^{-4}\) in our experiments by default.
Furthermore, the hyper-parameter \(\chi\) is investigated in Fig. 5 to ensure the constraint item within a suitable value. From Fig. 5a, it could be seen that the MAP scores reach a stable performance and outperform other \(\chi\) values from \(\chi\)=5 to \(\chi\)=30. In Fig. 5b, the MAP score achieves the best value when \(\chi\) is 10. Combining (a) and (b) in Fig. 5, we finally set \(\chi\)=10 in our experiments. In addition, the training process employs ADAM as the optimizer and conducts the experiment on Nvidia 2080Ti GPUs with a learning rate of 2\(\times 10^{-4}\). The maximum epoch is set as 500 in all experiments.
4.4 Quantitative results
We verify the effectiveness of our proposed method and compare 21 common cross-modal retrieval methods in the experiments, including 13 traditional multimodal retrieval methods, namely CCA Rasiwasia et al. (2010), MCCA Rupnik and Shawe-Taylor (2010), KCCA Akaho (2006), Corr-AE Feng et al. (2014), MvDA Kan et al. (2012), MvDA-vc Kan et al. (2015), GSS-SL Zhang et al. (2017), DCCA Andrew et al. (2013), DCCAE Wang et al. (2015), CMDN Peng et al. (2016), MvDN Kan et al. (2016), MCSM Peng et al. (2018), and CCL Peng et al. (2017a). Different from these methods, the proposed CSAN utilized a cross-coupled semantic adversarial network for cross-modal retrieval. Based on the adversarial strategy, the condition-generators reform the sample representations to confuse the discriminators, and encourage the discriminators to distinguish the modality.
In addition, we introduce 8 deep adversarial-based methods, namely ACMR Wang et al. (2017), CM-GANs Peng and Qi (2019), MHTN Huang et al. (2018), MAN Hu et al. (2019a), CAN Hu et al. (2021), \(\hbox {MS}^{2}\)GAN Wu et al. (2020), PAN Zeng et al. (2021), PLMS Li et al. (2023b). Although these methods receive optimization by deep adversarial strategy, the proposed method leverages cross-coupled semantic architecture with the adversarial learning strategy to preserve the semantic consistency in the common potential subspace. Therefore, the proposed network optimizes the model through a single feed-forward sub-network, while exploiting the coupling network with inverse mapping to construct the semantic correlation.
The proposed CSAN is compared against several common cross-modal retrieval approaches such as CCA, CCL, PAN, ACMR, etc, in the three databases to investigate the effectiveness of the proposed algorithms. To make fair comparisons, the feature embedding strategy is unified in all approaches. Tables 1, 2, 3 report the MAP results by retrieving all of the ranked instances on Pascal Sentence, PKU XMedia and PKU XMediaNet databases, respectively. To statistically analyze the detailed results in the following tables, all of the results are conducted with 5 random runnings and the final MAP score is obtained by calculating the mean score. The most superior results are bolded in the Tables.
Table 1 reports the cross-modal retrieval results in terms of MAP scores of our approach and several competing approaches on the Pascal Sentence database, where “Average” represents the mean value of I2T and T2I results. From Table 1, it could be found that our proposed CSAN achieves the best performance, as well as shows significantly superior to all the compared algorithms. Intuitively, most of the GAN-based approaches (e.g, CAN and \(\hbox {MS}^{2}\)GAN ) are superior to the other approaches, since the adversarial learning mechanism alternately trains the generator and discriminator with the unique minimax game. Based on the strategy, our CSAN maps the multi-media data into one potential common subspace for direct correlation measurement.
Specifically, the proposed CSAN achieves 71.2%, 72.4% and 71.8% on I2T, T2I and Average tasks, respectively. By comparing with the PAN, our CSAN outperforms it with 2.6%, 3.5% and 3.0% of improvement. Moreover, our approach is superior to the \(\hbox {MS}^2\)GAN approach with improvements of 3.5%, 5.4% and 4.5% on the three tasks. On one hand, our CSAN fully exploits the supervised information to learn the discrimination in both semantic space and representation space. Except for preserving the modality correlation of common space, we also improve the representation discriminability, that is, forcing the distribution of instances of the same semantic category to be compact, while the distribution of instances of different semantics to be as scattered as possible. On the other hand, the cross-coupled semantic architecture is presented to perform the semantic consistency of reconstructed information. The generator of each mode not only learns the feature discrimination in the forward process, but also minimizes the distance between the generated representation of a specific modality and the cross-media representation through the coupling generator.
Table 2 provides the MAP scores on the XMedia database to compare the performance of the proposed CSAN and baselines. Different from other databases, the text data of XMedia adopts BOW strategy to extract the representation vector with 3000 dimensions. Although there are differences in feature embedding strategy, Table 2 shows that our CSAN outperforms all other baselines and achieves the most competitive approach. The result in terms of MAP score of the CSAN method reaches 90.6% on I2T task and 91.3% on T2I task. Compared with the MAN method, the MAP of the proposed method increases by up to 1.5%. For the T2I task, the MAP of the CSAN method increases by up to 1.2%. The CSAN method reaches 90.9% and it gets an improvement of 1.3% than the MAN approach on Average tasks. The MAP scores of all tasks achieve the optimal results on the XMedia database, which demonstrates the effectiveness of the proposed method and indicates that the proposed approach is a good multimodal learning method for cross-modal retrieval even when dealing with multimodal data from different feature embedding methods.
Table 3 reports the MAP scores of our CSAN against the SOTA baselines on the large-scale database (i.e., XMediaNet), which aims to investigate the performance of our approach in large-scale scenarios. In Table 3, the CSAN is significantly superior to other algorithms with the results of 72.8% on I2T, 69.1% on T2I and 70.9% on average. As can be seen, the proposed CSAN has improved one of the best competitors (i.e., PAN) by 4.4% on average. Thus, the performance indicates that our architecture with the adversarial learning strategy performs significant advantages compared with the non-GAN-based approaches. Moreover, by comparing with the competitors based on the GAN module, our CSAN also outperforms the optimal result (i.e., CAN) with 5.8% on I2T and 3.0% on T2I. Because both two approaches employ the adversarial learning strategy, it can be concluded that the cross-coupled semantic architecture is effective in this work and significantly boosts the performance of the proposed CSAN approach.
From Tables 1 and 2, we find that despite several traditional algorithms reporting satisfactory results in terms of MAP scores, most of these algorithms fail to achieve a significant cross-modal retrieval performance in the large-scale XMediaNet database. However, CSAN achieves the most competitive performance in the database. Especially, it is worth noting that although the proposed method did not demonstrate sufficient superiority compared to the PLMS method, it demonstrated good MAP scores on large-scale datasets. There mainly exist two reasons for the superiority: (1) XMediaNet has more abundant categories than other databases, thus the heterogeneous modality space contains complex semantic information and feature discrimination. However, most of the traditional algorithms cannot exploit semantic information sufficiency to associate paired heterogeneous data. (2) Semantic discrimination and correlation discrimination are jointly explored and leveraged effectively for the retrieval task, so that CSAN can capture more pairwise relations in label space and the discriminative information in multi-modal data space simultaneously.

PR curves for I2T and T2I on pascal sentence database
To intuitively visualize the performance of our CSAN and competitive baselines, Fig. 6 provides the PR curve on I2T and T2I tasks, respectively. All of the samples are retrieved in the test set of the PR curve and 5 random runnings are performed to obtain the results. From the figure, the proposed CSAN shows clear advantages as compared with other competing approaches in all of the retrieval tasks. The precision and recall scores of the proposed CSAN are superior to both the GAN-based approaches and traditional approaches, which indicates that CSAN makes a significant improvement in eliminating modality differences and bridging the heterogeneity gap between multimedia data.
It is worth noting that compared with the baselines in Fig. 6, the proposed CSAN algorithm shows better results by retrieving the top samples, especially on the I2T task. To verify the result, we also report the performance in terms of MAP scores of the proposed CSAN against SOTA baselines by retrieving the top 50 instances (i.e.,\({N_R}\)=50) in the ranking list on the Pascal Sentence database and XMedia database. From Table 4 and Table 5, we find our CSAN outperforms all the other competitors and achieves more significant improvement than the \({N_R}\)=ALL task. Obviously, instances at the top of the ranking list convey more semantic discrimination information and feature similarity to the query instance. The proposed CSAN approach relies on semantic information and feature representation in both forward generators and cross-coupled architectures to supervise the training of the framework. Accordingly, the proposed CSAN shows superior heterogeneous data matching performance in the top-ranked instances.
4.5 Ablation study
In this section, we set several task-specific variants to evaluate the important components of CSAN. Specifically, to investigate the contribution of multi-losses in the forward generator and couple-generator, five alternative variants are introduced as follows. To give a fair comparison, all the variants follow the same settings and experimental parameters as the proposed CSAN except for the investigated components.
-
CSAN-\({{{\mathcal {L}}}_G}\) is the variant that training the proposed CSAN without \({{{\mathcal {L}}}_G}\), which is used to investigate the effectiveness of the modality approximate loss.
-
CSAN-\({{{\mathcal {L}}}_s}\) trains the CSAN variant without the semantic discrimination loss, which aims to explore the contribution of semantic discriminative loss.
-
CSAN-\({{{\mathcal {L}}}_C}\) is the variant of our approach without employing the \({{{\mathcal {L}}}_C}\) loss function.
-
CSAN-\({{{\mathcal {L}}}_{cross\sim r}}\) removes the \({\mathcal{L}_{cross\sim r}}\) loss in CSAN to train the model.
-
CSAN-\({{{\mathcal {L}}}_{cross\sim s}}\) represents the variant that removes the \({{{\mathcal {L}}}_{cross\sim s}}\) loss function in the CSAN.
From Table 6, the MAP scores of variants CSAN-\({\mathcal{L}_G}\), CSAN-\({{{\mathcal {L}}}_s}\) and CSAN-\({{{\mathcal {L}}}_C}\) are obviously inferior to those of the complete version of CSAN, which demonstrates all of the designed loss functions effectively push the semantically discriminative into the common subspace, and provide significant contributions on both I2T and T2I tasks. Noted that CSAN-\({{{\mathcal {L}}}_s}\) achieves poor performance with the MAP score of only 10.5% on average. This is because the semantic discriminative loss fully explores the semantic information in the category label, and guides the proposed CSAN architecture for training.
Furthermore, we also investigate the contribution of the proposed cross-coupled losses. Table 7 demonstrates the performance comparisons of the two variants of CSAN in terms of MAP scores on the Pascal Sentences database. From the experiment results, we can find that the two loss functions \({{{\mathcal {L}}}_{cross\sim r}}\) and \({{{\mathcal {L}}}_{cross\sim s}}\) show a certain impact on cross-modal retrieval and both of the two loss functions improve the performance of our algorithm in terms of MAP scores. The above baseline results have verified the separate contribution of each component in the proposed CSAN approach with regard to the following two aspects. (1) \({{{\mathcal {L}}}_{cross\sim r}}\) further explore cross-modal correlation and discriminate information between different modalities in the cross-coupled semantic architecture. (2) \({{{\mathcal {L}}}_{cross\sim s}}\) can model semantic information within each modality to make a complementary contribution to inter-modality discrimination.
Table 8 investigates the average training time-consuming of each epoch on the XMediaNet database. From Table 8, we can observe that the proposed CSAN approach achieves the lowest time complexity with the baseline algorithm. The CSAN algorithm designs cross-coupled semantic architecture in the modality-specific generator and the overall framework learns a unified potential subspaces. Based on the scores in Tables 1-3, the results indicate that CSAN significantly improves the performance of cross-modal retrieval as well as effectively improves the efficiency of cross-modal retrieval with a lower cost.
4.6 Visualization of the representations in common space
In this section, we employ the t-SNE Van der Maaten and Hinton (2008), Van Der Maaten (2014) approach to visualize the representations learned by different cross-modal methods, which reduces the dimension of the high-dimensional data and embeds them in two-dimensional data.

The visualization distribution on the Pascal Sentence database by using the t-SNE method. For the convenience of distinguishing, we mark different colors on the data with different categories
In Fig. 7a is the original distribution of the Pascal Sentence database. Figure 7b, c and d represent the representations learned by ACMR, MAN and proposed CSAN approaches, respectively. Since the original samples in the Pascal sentence database have been embedded by feature extraction models, the original representations show preliminary category segmentation with a scattered intra-class distribution. ACMR and MAN attempt to learn the modality consistency representations in the common subspace. However, these approaches lack information interaction between modalities, which shows the overlap of category clusters among modalities. By exploiting the cross-coupled semantic architecture, the proposed CSAN approach preserves more semantic discrimination and reduces information redundancy, thus the representations in Fig. 7d show a compact intra-class distribution and scattered intra-class distribution.
5 Conclusions
In this paper, a cross-coupled semantic adversarial network is proposed for cross-modal retrieval. First, based on the generative adversarial network, a bimodal image-text mutual retrieval framework is introduced in this paper, which constructs a potential common subspace and projects multimodal data in it to bridge the semantic gap of heterogeneous data. Second, aiming to fully explore the internal relationship between modalities and interactively learn semantic information, this paper design a cross-coupled semantic learning branch for each modality. By sharing the parameters of the forward mapping and the inverse mapping (coupled branch), the discriminative information of different modalities is exchanged with each other, thus eliminating the cross-modal discrepancy and alleviating the redundancy. Third, by minimizing the loss functions in cross-coupled semantic architecture, the instances with the same semantics are pushed to be compact in the common subspace, thus improving the retrieval accuracy. Extensive experiments indicate that our approach is effective and outperforms the baseline approaches in three widely-used databases.
With the sharp increase of imperfect multimedia data, such as noise samples and unpaired samples, we consider employing the reinforcement learning strategy in the future to reduce the impact of these problems on cross-modal retrieval. Given the introduction of noisy and missing data, issues such as non-convergence or gradient disappearance in the training of adversarial mechanisms will also be optimized in the next work. Moreover, the time cost of the cross-modal retrieval is also planned to be optimized by utilizing the hash mapping model in further work.
Data availability
The datasets generated during and/or analysed during the current study are available from the corresponding author on reasonable request.
References
Akaho S (2006) A kernel method for canonical correlation analysis. Proceedings of the International Meeting of Psychometric Society, 263–269
Andrew G, Arora R, Bilmes J, Livescu K (2013) Deep canonical correlation analysis. In: International Conference on Machine Learning, pp. 1247–1255. PMLR
Azzam M, Wu W, Cao W, Wu S, Wong H-S (2020) Ktransgan: variational inference-based knowledge transfer for unsupervised conditional generative learning. IEEE Trans Multimed 23:3318–3331
Cai L, Zhu L, Zhang H, Zhu X (2022) Da-gan: dual attention generative adversarial network for cross-modal retrieval. Future Internet 14(2):43
Cheng Q, Tan Z, Wen K, Chen C, Gu X (2022) Semantic pre-alignment and ranking learning with unified framework for cross-modal retrieval. IEEE Transactions on Circuits and Systems for Video Technology
Ding X, Wang Y, Xu Z, Welch WJ, Wang ZJ (2022) Continuous conditional generative adversarial networks: novel empirical losses and label input mechanisms. IEEE Trans Pattern Anal Mach Intell 45(7):8143–8158
Everingham M, Winn J (2010) The pascal visual object classes challenge 2007 (voc2007) development kit. Int J Comput Vis 88(2):303–338
Everingham M, Gool L, Williams CK, Winn J, Zisserman A (2010) The pascal visual object classes (voc) challenge. Springer, New York
Feng F, Wang X, Li R (2014) Cross-modal retrieval with correspondence autoencoder. In: Proceedings of the 22nd ACM International Conference on Multimedia, pp. 7–16
Goodfellow I, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, Courville A, Bengio Y (2014) Generative adversarial nets. Adv Neural Inf Process Syst 27:1
Gu J, Wang Z, Kuen J, Ma L, Shahroudy A, Shuai B, Liu T, Wang X, Wang G, Cai J et al (2018) Recent advances in convolutional neural networks. Pattern Recogn 77:354–377
He P, Wang M, Tu D, Wang Z (2023) Dual discriminant adversarial cross-modal retrieval. Appl Intell 53(4):4257–4267
Hu P, Peng D, Wang X, Xiang Y (2019a) Multimodal adversarial network for cross-modal retrieval. Knowl-Based Syst 180:38–50
Hu P, Zhen L, Peng D, Liu P (2019b) Scalable deep multimodal learning for cross-modal retrieval. In: Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, pp. 635–644
Hu P, Peng X, Zhu H, Lin J, Zhen L, Wang W, Peng D (2021) Cross-modal discriminant adversarial network. Pattern Recogn 112:107734
Huang X, Peng Y, Yuan M (2018) Mhtn: modal-adversarial hybrid transfer network for cross-modal retrieval. IEEE Trans cybern 50(3):1047–1059
Jin P, Zhang Y, Chen X, Xia Y (2016) Bag-of-embeddings for text classification. IJCAI 16:2824–2830
Jing L, Vahdani E, Tan J, Tian Y (2021) Cross-modal center loss for 3d cross-modal retrieval. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 3142–3151
Kan M, Shan S, Zhang H, Lao S, Chen X (2012) Multi-view discriminant analysis, pp. 188–194
Kan M, Shan S, Zhang H, Lao S, Chen X (2015) Multi-view discriminant analysis. IEEE Trans Pattern Anal Mach Intell 38(1):188–194
Kan M, Shan S, Chen X (2016) Multi-view deep network for cross-view classification. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4847–4855
Li G, Stalin T, Truong VT, Alvarado P (2022) Dnn-based predictive model for a batoid-inspired soft robot. IEEE Robotics Automation Lett (7–2)
Li Z, Lu H, Fu H, Wang Z, Gu G (2023a) Adaptive adversarial learning based cross-modal retrieval. Eng Appl Artif Intell 123:106439. https://doi.org/10.1016/j.engappai.2023.106439
Li Z, Lu H, Fu H, Gu G (2023b) Parallel learned generative adversarial network with multi-path subspaces for cross-modal retrieval. Inf Sci 620:84–104
Li M, Zhou S, Chen Y, Huang C, Jiang Y (2024) Educross: dual adversarial bipartite hypergraph learning for cross-modal retrieval in multimodal educational slides. Inform Fusion 109:102428. https://doi.org/10.1016/j.inffus.2024.102428
Ma X, Zhang T, Xu C (2020) Multi-level correlation adversarial hashing for cross-modal retrieval. IEEE Trans Multimed. 22(12):3101–3114
Ma X, Wang F, Hou Y (2021) Multiple negative samples based on gan for cross-modal retrieval. In: 2021 IEEE 4th International Conference on Electronics and Communication Engineering (ICECE), pp. 136–140. IEEE
Mirza M, Osindero S (2014) Conditional generative adversarial nets. Preprint at arXiv:1411.1784
Park SM, Kim YG (2023) Visual language navigation: a survey and open challenges. Artif Intell Rev 56(1):365–427
Peng Y, Qi J (2019) Cm-gans: cross-modal generative adversarial networks for common representation learning. ACM Trans Multimed Comput Commun Appl (TOMM) 15(1):1–24
Peng Y, Zhai X, Zhao Y, Huang X (2015) Semi-supervised cross-media feature learning with unified patch graph regularization. IEEE Trans Circuits Syst Video Technol 26(3):583–596
Peng Y, Huang X, Qi J (2016) Cross-media shared representation by hierarchical learning with multiple deep networks. In: IJCAI, pp. 3846–3853
Peng Y, Qi J, Huang X, Yuan Y (2017a) Ccl: cross-modal correlation learning with multigrained fusion by hierarchical network. IEEE Trans Multimed 20(2):405–420
Peng Y, Huang X, Zhao Y (2017b) An overview of cross-media retrieval: concepts, methodologies, benchmarks, and challenges. IEEE Trans Circuits Syst Video Technol 28(9):2372–2385
Peng Y, Qi J, Yuan Y (2018) Modality-specific cross-modal similarity measurement with recurrent attention network. IEEE Trans Image Process 27(11):5585–5599
Peng Y, Ye Z, Qi J, Zhuo Y (2020) Unsupervised visual-textual correlation learning with fine-grained semantic alignment. IEEE Transactions on Cybernetics
Perez-Martin J, Bustos B, Guimarães SJF, Sipiran I, Pérez J, Said GC (2022) A comprehensive review of the video-to-text problem. Artif Intell Rev, 1–75
Rashtchian C, Young P, Hodosh M, Hockenmaier J (2010) Collecting image annotations using amazon’s mechanical turk. In: Proceedings of the NAACL HLT 2010 Workshop on Creating Speech and Language Data with Amazon’s Mechanical Turk, pp. 139–147
Rasiwasia N, Costa Pereira J, Coviello E, Doyle G, Lanckriet GR, Levy R, Vasconcelos N (2010) A new approach to cross-modal multimedia retrieval. In: Proceedings of the 18th ACM International Conference on Multimedia, pp. 251–260
Rupnik J, Shawe-Taylor J (2010) Multi-view canonical correlation analysis. In: Conference on Data Mining and Data Warehouses (SiKDD 2010), pp. 1–4
Shi Y, Zhao Y, Liu X, Zheng F, Ou W, You X, Peng Q (2022) Deep adaptively-enhanced hashing with discriminative similarity guidance for unsupervised cross-modal retrieval. IEEE Transactions on Circuits and Systems for Video Technology
Shu Z, Bai Y, Zhang D, Yu J, Yu Z, Wu X-J (2022) Specific class center guided deep hashing for cross-modal retrieval. Inf Sci 609:304–318
Su S, Zhong Z, Zhang C (2019) Deep joint-semantics reconstructing hashing for large-scale unsupervised cross-modal retrieval. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 3027–3035
Su M, Gu G, Ren X, Fu H, Zhao Y (2021) Semi-supervised knowledge distillation for cross-modal hashing. IEEE Trans Multimed 25:662–675
Van Der Maaten L (2014) Accelerating t-sne using tree-based algorithms. J Mach Learn Res 15(1):3221–3245
Van der Maaten L, Hinton G (2008) Visualizing data using t-sne. J Mach Learn Res 9(11):2579–2605
Wang W, Arora R, Livescu K, Bilmes J (2015) On deep multi-view representation learning. In: International Conference on Machine Learning, pp. 1083–1092. PMLR
Wang B, Yang Y, Xu X, Hanjalic A, Shen HT (2017) Adversarial cross-modal retrieval. In: Proceedings of the 25th ACM International Conference on Multimedia, pp. 154–162
Wu F, Jing X-Y, Wu Z, Ji Y, Dong X, Luo X, Huang Q, Wang R (2020) Modality-specific and shared generative adversarial network for cross-modal retrieval. Pattern Recogn 104:107335
Xie Z, Yang Y, Zhang Y, Wang J, Du S (2022) Deep learning on multi-view sequential data: a survey. Artif Intell Rev, 1–44
Xu X, Lin K, Yang Y, Hanjalic A, Shen HT (2022) Joint feature synthesis and embedding: adversarial cross-modal retrieval revisited. IEEE Trans Pattern Anal Mach Intell 44(6):3030–3047
Yang Z, Yang L, Raymond OI, Zhu L, Huang W, Liao Z, Long J (2021) Nsdh: a nonlinear supervised discrete hashing framework for large-scale cross-modal retrieval. Knowl-Based Syst 6:217
Yang F, Ding X, Liu Y, Ma F, Cao J (2022) Scalable semantic-enhanced supervised hashing for cross-modal retrieval. Knowled-Based Syst 251:109176
Yao T, Yan L, Ma Y, Yu H, Su Q, Wang G, Tian Q (2020) Fast discrete cross-modal hashing with semantic consistency. Neural Netw 125:142–152
Yu T, Yang Y, Li Y, Liu L, Fei H, Li P (2021) Heterogeneous attention network for effective and efficient cross-modal retrieval, pp. 1146–1156
Zeng Z, Wang S, Xu N, Mao W (2021) Pan: Prototype-based adaptive network for robust cross-modal retrieval. In: Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, pp. 1125–1134
Zhai X, Peng Y, Xiao J (2013) Learning cross-media joint representation with sparse and semisupervised regularization. IEEE Trans Circuits Syst Video Technol 24(6):965–978
Zhang D, Wu X-J (2020) Scalable discrete matrix factorization and semantic autoencoder for cross-media retrieval. IEEE Trans Cybern 52(7):5947–5960
Zhang D, Wu X-J (2022) Robust and discrete matrix factorization hashing for cross-modal retrieval. Pattern Recogn 122:108343
Zhang L, Ma B, Li G, Huang Q, Tian Q (2017) Generalized semi-supervised and structured subspace learning for cross-modal retrieval. IEEE Trans Multimed 20(1):128–141
Zhang D, Wu X-J, Yu J (2021a) Label consistent flexible matrix factorization hashing for efficient cross-modal retrieval. ACM Trans Multimed Comput Commun Appl (TOMM) 17(3):1–18
Zhang D, Wu X-J, Liu Z, Yu J, Kitter J (2021b) Fast discrete cross-modal hashing based on label relaxation and matrix factorization. In: 2020 25th International Conference on Pattern Recognition (ICPR), pp. 4845–4850. IEEE
Zhang D, Wu X-J, Yu J (2021c) Discrete bidirectional matrix factorization hashing for zero-shot cross-media retrieval. In: Chinese Conference on Pattern Recognition and Computer Vision (PRCV), pp. 524–536. Springer
Zhang L, Chen L, Ou W, Zhou C (2022) Semi-supervised constrained graph convolutional network for cross-modal retrieval. Comput Electr Eng 101:107994
Zhang L, Chen L, Zhou C, Li X, Yang F, Yi Z (2024a) Weighted graph-structured semantics constraint network for cross-modal retrieval. IEEE Trans Multimed 26:1551–1564. https://doi.org/10.1109/TMM.2023.3282894
Zhang L, Yang Y, Ge S, Sun G, Wu X (2024b) Parallel weight control based on policy gradient of relation refinement for cross-modal retrieval. Eng Appl Artif Intell 136:108949. https://doi.org/10.1016/j.engappai.2024.108949
Zhen L, Hu P, Wang X, Peng D (2019) Deep supervised cross-modal retrieval. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 10394–10403
Zhu JY, Park T, Isola P, Efros AA (2017) Unpaired image-to-image translation using cycle-consistent adversarial networks. In: International Conference on Computer Vision
Acknowledgements
The authors would like to thank the anonymous reviewers for valuable comments.
Funding
This work was partly supported by the Hebei Medical University Postdoctoral Fund (No. 30705010057), National Natural Science Foundation of China (No.62072394), Natural Science Foundation of Hebei province (F2024203049), the Central Guidance on Local Science and Technology Development Fund of Hebei Province (246Z2003G), Hebei Yanzhao Golden Platform Talent Gathering Plan Backbone Talent Project (Postdoctoral Platform)(B2024005031), the Science Research Project of Hebei Education Department (BJ2025213) and the Science Research Project of Hebei Education Department (grant No. BJK2023074).
Author information
Authors and Affiliations
Contributions
Zhuoyi Li and Guanghua Gu wrote the main manuscript text. Guanghua Gu guided the experimental method. Zhuoyi Li proposed ideas. Huibin Lu provided the experimental resources. Hao Fu and Fanzhen Meng verified the experiment. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Li, Z., Lu, H., Fu, H. et al. Csan: cross-coupled semantic adversarial network for cross-modal retrieval. Artif Intell Rev 58, 151 (2025). https://doi.org/10.1007/s10462-025-11152-7
Accepted:
Published:
DOI: https://doi.org/10.1007/s10462-025-11152-7