
Abstract
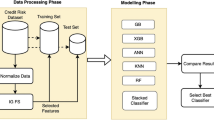
The development of credit risk assessment models is often considered within a classification context. Recent studies on the development of classification models have shown that a combination of methods often provides improved classification results compared to a single-method approach. Within this context, this study explores the combination of different classification methods in developing efficient models for credit risk assessment. A variety of methods are considered in the combination, including machine learning approaches and statistical techniques. The results illustrate that combined models can outperform individual models for credit risk analysis. The analysis also covers important issues such as the impact of using different parameters for the combined models, the effect of attribute selection, as well as the effects of combining strong or weak models.
Similar content being viewed by others

References
Altman, E.I., R. Avery, R. Eisenbeis, and J. Stinkey. (1981). Application of Classification Techniques in Business, Banking and Finance. Greenwich: JAI Press,.
Baesens, B., T. Van Gestel, S. Viaene, M. Stepanova, J. Suyken, and J. Vanthienen. (2003). “Benchmarking State-of-the-Art Classification Algorithms for Credit Scoring.” Journal of the Operational Research Society, 54, 627–635.
Bates, J.M. and C.W.J. Granger. (1969). “The Combination of Forecasts,” Operational Research Quarterly, 20(4), 541–468.
Blake, C., E. Keogh, and C.J. Merz. (1998), “UCI Repository of Machine Learning Data Bases,” University of California, Department of Information and Computer Science, Irvine, CA (http://www.ics.uci.edu/~mlearn/MLRepository.html).
Boyle M., J.N. Crook, R. Hamilton, and L.C. Thomas. (1992). “Methods for Credit Scoring Applied to Slow Payers.” In L.C. Thomas, J.N. Crook, and D.B. Edelman (eds.), Credit scoring and Credit Control. Oxford: Oxford University Press, pp. 75–90.
Breiman, L. (1996). “Bagging Predictors,” Machine Learning, 24(2), 123–140.
Breiman, L., J. Friedman, R. Olshen, and C.J. Stone. (1984). Classification and Regression Trees. New York: Chapman and Hall.
Cronan, T.P., L.W. Glorfeld, and L.G. Perry. (1991). “Production System Development for Expert Systems Using a Recursive Partitioning Induction Approach: An Application to Mortgage, Commercial and Consumer Lending”, Decision Sciences, 22, 812–845.
Dietterich, T.G. (2000). “Ensemble Methods in Machine Learning.” In J. Kittler and F. Roli (eds.), First International Workshop on Multiple Classifier Systems (Lecture Notes in Computer Science). New York: Springer Verlag, pp. 1–15.
Doumpos, M. and C. Zopounidis. (2002). Multicriteria Decision Aid Classification Methods. Dordrecht: Kluwer Academic Publishers.
Doumpos, M., K. Kosmidou, G. Baourakis, and C. Zopounidis. (2002). “Credit Risk Assessment Using a Multicriteria Hierarchical Discrimination Approach: A Comparative Analysis,” European Journal of Operational Research, 138(2), 392–412.
Duda, R.O., P.E. Hart, and D.G. Stork. (2001). Pattern Classification (2nd Edition)}. New York: John Wiley.
Dunteman, G.H. (1989). Principal Components Analysis. Newbury Park, CA: Sage Publications.
Efron, B. (1983). “Estimating the Error Rate of a Prediction Rule: Improvement of Cross-validation,” Journal of the American Statistical Association, 78, 316–330.
Freund, Y. (1995). “Boosting a Weak Learning Algorithm by Majority,” Information and Computation, 121(2), 256–285.
Geman, S., E. Bienenstock, and R. Doursat. (1992). “Neural Networks and the Bias/Variance Dilemma,” Neural Computation, 4, 1–58.
Hillegeist S.A., E.K. Keating, D.P. Cram, and K.G. Lundstedt. (2004). “Assessing the Probability of Bankruptcy,” Review of Accounting Studies, 9(1), 5–34.
Hosmer, D.W. and S. Lemeshow. (2000). Applied Logistic Regression (2nd Edition). New York: John Wiley.
Huang, Z., H. Chen, C.-J. Hsu, W.-H. Chen, and S. Wu. (2004). “Credit Rating Analysis with Support Vector Machines and Neural Networks: A Market Comparative Study.” Decision Support Systems, 37, 543–558.
Klecka, W.R. (1980). Discriminant Analysis. London: Sage Publications.
LeBlanc, M. and R. Tibshirani. (1996). “Combining Estimates in Regression and Classification,” Journal of the American Statistical Association, 91, 1641–1650.
Lee, T-S., Ch.-Ch. Chiu, Ch-J. Lu, and I-F. Chen. (2002). “Credit Scoring Using the Hybrid Neural Discriminant Technique.” Expert System with Applications, 23, 245–254.
Merz, C.J. (1996). “Dynamical Selection of Learning Algorithms.” In D. Fisher and H. Lenz (eds.), Learning from Data: Artificial Intelligence and Statistics, New York: Springer Verlag.
Merz, C.J. (1999). “Using Correspondence Analysis to Combine Classifiers,” Machine Learning, 36, 33–58.
Merz, C.J. and M.J. Pazzani. (1999). “A Principal Components Approach to Combining Regression Estimates,” Machine Learning 36, 9–32.
Michie, D., D.J. Spiegelhalter, C.C. Taylor, and D.J. Speigelhalter. (1994). Machine Learning Neural and Statistical Classification. Englewood Cliffs, NJ: Prentice Hall.
Pawlak, Z. (1982). “Rough Sets,” International Journal of Information and Computer Sciences, 11, 341–356.
Ripley, B.D. (1996). Pattern Recognition and Neural Networks. Cambridge: Cambridge University Press.
Shin, K.-S., T.S. Lee, and H. Kim. (2005). “An Application of Support Vector Machines in Bankruptcy Prediction Model.” Expert Systems with Applications, 28, 127–135.
Shumway, T.G. (2001). “Forecasting Bankruptcy More Accurately: A Simple Hazard Model,” Journal of Business 74(1), 101–124.
Specht, D.F. (1990). “Probabilistic Neural Networks,” Neural Networks, 3, 109–118.
Srinivasan, V. and Y.H. Kim. (1987). “Credit Granting: A Comparative Analysis of Classification Procedures”, Journal of Finance, 42(3), 665–683.
Stone, M. (1974). “Cross-validation Choice and Assessment of Statistical Predictions,” Journal of the Royal Statistical Society, B 36, 111–147.
Theodossiou, P. (1991). “Alternative Models for Assessing the Financial Condition of Business in Greece,” Journal of Business Finance and Accounting, 18(5), 697–720.
Thomas, L.C. (2000). “A survey of credit and behavioural scoring: forecasting financial risk of lending to consumers.” International Journal of Forecasting, 16, 149–172.
Ting, K.M., and I.H. Witten. (1999). “Issues in Stacked Generalization,” Journal of Artificial Intelligence Research, 10, 271–289.
Tyree, E. and J. Long. (1995). “Assessing Financial Distress with Probabilistic Neural Networks.” In A.N. Refenes, Y. Abu-Mostafa and J. Moody and A. Weigend (eds.), Neural Networks in Financial Engineering. London: World Scientific, pp. 423–435.
Vapnik, V.N. (1998). Statistical Learning Theory. New York: Wiley.
Vilalta, R. and Y. Drissi. (2002). “A Perspective View and Survey of Meta-Learning”, Artificial Intelligence Review, 18, 77–95.
Wolpert, D.H. (1992). “Stacked Generalization,” Neural Networks, 5, 241–259.
Wolpert, D.H. (1996a). “The Lack of a Priori Distinctions Between Learning Algorithms,” Neural Computation, 8(7), 1341–1390.
Wolpert, D.H. (1996b). “The Existence of a Priori Distinctions Between Learning Algorithms,” Neural Computation, 8(7), 1391–1420.
Wolpert, D.H., and W.G. Macready. (1997). “No Free Lunch Theorems for Optimization,” IEEE Transactions on Evolutionary Computation, 1(1), 67–82.
Yang, Z.R., M.B. Platt, and H.D. Platt. (1999). “Probabilistic Neural Networks in Bankruptcy Prediction.” Journal of Business Research, 44(2), 67–74
Zadeh, L.A. (1965). “Fuzzy sets,” Information and Control, 8, 338–353.
Zopounidis, C. and M. Doumpos. (2002). “Multicriteria Classification and Sorting Methods: A Literature Review,” European Journal of Operational Research, 138(2), 229–246.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Doumpos, M., Zopounidis, C. Model combination for credit risk assessment: A stacked generalization approach. Ann Oper Res 151, 289–306 (2007). https://doi.org/10.1007/s10479-006-0120-x
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10479-006-0120-x