
Abstract
Despite powerful advances in interest rate curve modeling for data-rich countries in the last 30 years, comparatively little attention has been paid to the key practical problem of estimation of the term structure of interest rates for emerging markets. This may be partly due to limited data availability. However, emerging bond markets are becoming increasingly important and liquid. It is, therefore, important to be understand whether conclusions drawn from developed countries carry over to emerging markets. We estimate model parameters of fully flexible Nelson–Siegel–Svensson term structures model which has become one of the most popular term structure model among academics, practitioners, and central bankers. We investigate four sets of bond data: U.S. Treasuries, and three major emerging market government bond data-sets (Brazil, Mexico and Turkey). By including both the very dense U.S. data and the comparatively sparse emerging market data, we ensure that are results are not specific to a particular data-set. We find that gradient and direct search methods perform poorly in estimating term structures of interest rates, while global optimization methods, particularly the hybrid particle swarm optimization introduced in this paper, do well. Our results are consistent across four countries, both in- and out-of-sample, and for perturbations in prices and starting values. For academics and practitioners interested in optimization methods, this study provides clear evidence of the practical importance of choice of optimization method and validates a method that works well for the NSS model.




Similar content being viewed by others

Notes
See Gilli and Schumann (2011) for other optimization problems in theoretical and applied finance that are difficult to solve as they exhibit multiple local optima.
Central banks report their term structure estimates and methodologies to the Bank for International Settlements (BIS). Most of them use the NS or NSS functional forms to estimate term structure. (BIS 2005)
NSS model sometimes better applied with fixed time decay parameter such as hedging of bond portfolios (Diebold et al. 2008), or relating the yield curve to macroeconomic variables (Diebold et al. 2006). In such cases, the resulting NSS model with fixed time decay parameter alleviates numerical estimation problem reported in the literature.
Manousopoulos and Michalopoulosa (2007) also tests a variety of optimization methods to estimate the NSS functional form and so is most similar to our paper in the existing literature. Our paper differs from theirs in using multiple data-sources, extensive robustness tests, and a new optimization method which we find to be superior the alternatives. We also reach a different conclusion as to which method is recommended for estimating NS and NSS term structures.
This condition and imposed on spline-based methods through appropriate constraints, but occurs naturally with the Nelson–Siegel functional form. It cannot be achieved using polynomial forms.
Some authors, such as Lekkos (2001), have shown that this factor structure can be replicated with random forward rates and a fairly simple correlation structure. Be that as it may, the level–slope–curvature view of the term structure has now become standard.
Nelson and Siegel (1987), and Diebold and Li (2006) fit the NS or NSS functions to zero coupon rates instead of coupon bond prices. This is a numerically easier problem. Nelson and Siegel use Treasury Bill yields; Diebold and Li (2006) use the Unsmoothed Fama-Bliss term structures, which are available from Robert Bliss.
Annaert et al. (2012b) linearize the NSS function by performing a 2-dimensional grid search over values for \(\tau _1\) and \(\tau _2\).
By systematic mispricing we mean long runs of over- and under-pricing for adjacent maturities by the fitted term structure.
The MATLAB bootstrap routine lacks the internal filter of the Fama-Bliss method (Fama and Bliss (1987)), and neither produce yield curves that are smooth or lend themselves to economic interpretation, as does the NS model.
As starting point may be biased against gradient methods, alternatively we search for different \(\tau _2\) values with \(\tau _2=\tau _1 + \gamma _1 \) where \(\gamma _1\) set from 1 to 10. We find that our the results hold robust with respect to choice of \(\gamma _1\). We would like to thank the referee for kindly raising this issue.
For the optimization methods which begin with multiple starting values, the distance traveled was measured from the mean of the multiple starting values, computed parameter by parameter, to the final solution.
Gimeno and Pineda (2006) use a genetic algorithm to fit the NSS function to Spanish government bond prices. They then compare this method with what they call the “traditional” method.
The code for our algorithms is available upon request from authors.
We consider only dollar denominated Eurobonds issued by these countries because U.S. dollar denominated bonds have longer maturity and more liquidity relative to Euro denominated bonds for the same countries.
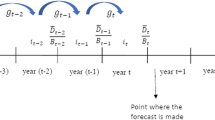
We generate bond price perturbation (\(P^p\)) using the following specification:
$$\begin{aligned} P^p_i = (P_{bid} - P_{ask}) \times \phi (0,1) \end{aligned}$$(14)for i \(=\) 1 ,..., 100 where \(\phi (0,1)\) is a random number from standard uniform distribution.
Each “box” shows the inter-quartile range of the data. The line inside the box is the median value. The “whiskers” are 1.5 times the inter-quartile range in length. The individual points outside of the whiskers are individual “outliers” defined as points greater than \(q_3 + 1.5(q_3-q_1)\) or less than \(q_1 - 1.5(q_3-q_1)\).
See Bertocchi and Moriggia (2000) for sensitivity of the bond portfolios behavior with respect to perturbed yield curves.
References
Afonso, A., & Martins, M. M. F. (2012). Level, slope, curvature of the sovereign yield curve, and fiscal behaviour. Journal of Banking and Finance, 36(6), 1789–1807.
Annaert, J., Claes, A. G., De Ceuster, M. J., & Zhang, H. (2012a). Estimating the yield curve using the Nelson-Siegel model: A ridge regression approach. International Review of Economics & Finance, 27, 482–496.
Annaert, J., Claes, A. G. P., De Ceuster, M. J. K., & Zhang, H. (2012b). The estimation of Svensson model term structures and their volatilities. Available at SSRN 2054693.
Bertocchi, M., & Moriggia, V. (2000). Sensitivity of bond portfolio’s behavior with respect to random movements in yield curve: A simulation study. Annals of Operations Research, 99(1), 267–286. doi:10.1023/A:1019227901758.
BIS. (2005). Zero-coupon yield curves: Technical documentation. Technical Report 25, Bank of International Settlements.
Bliss, R. (1997a). Movements in the term structure of interest rates. Economic Review, 82(4), 16–33.
Bliss, R. (1997b). Testing term structure estimation methods. Advances in Futures and Options Research, 9, 197–231.
Bolder, D., & Streliski, D. (1999). Yield curve modeling at the Bank of Canada. Technical Report 84, Bank of Canada.
Clerc, M., & Kennedy, J. (2002). The particle swarm-explosion, stability, and convergence in a multidimensional complex space. IEEE Transactions on Evolutionary Computation, 6(1), 58–73.
Csajbok, A., et al. (1998). Zero-coupon yield curve estimation from a central bank perspective. Technical Report, Magyar Nemzeti Bank (Central Bank of Hungary).
De Pooter, M. (2007). Examining the Nelson–Siegel class of term structure models: In-sample fit versus out-of-sample forecasting performance. Available at SSRN 992748.
Diebold, F. X., & Li, C. (2006). Forecasting the term structure of government bond yields. Journal of Econometrics, 130, 337–364.
Diebold, F. X., Li, C., & Yue, V. Z. (2008). Global yield curve dynamics and interactions: A dynamic nelsonsiegel approach. Journal of Econometrics, 146(2), 351–363. doi:10.1016/j.jeconom.2008.08.017. http://www.sciencedirect.com/science/article/pii/S0304407608001127. Honoring the research contributions of Charles R. Nelson.
Diebold, F. X., Piazzesi, M., & Rudebusch, G. D. (2005a). Modeling bond yields in finance and macroeconomics. American Economic Review, 95(2), 415–420.
Diebold, F. X., Piazzesi, M., & Rudebusch, G. D. (2005b). Modeling bond yields in finance and macroeconomics. PIER Working Paper Archive 05-008, Penn Institute for Economic Research, Department of Economics, University of Pennsylvania. http://ideas.repec.org/p/pen/papers/05-008.html.
Diebold, F. X., Rudebusch, G. D., & Aruoba, S. B. (2006). The macroeconomy and the yield curve: A dynamic latent factor approach. Journal of Econometrics, 131(1–2), 309–338. https://ideas.repec.org/a/eee/econom/v131y2006i1-2p309338.html.
Fama, E., & Bliss, R. (1987). The information in long-maturity forward rates. American Economic Review, 77(4), 16–33.
Gilli, M., & Schumann, E. (2011). Heuristic optimisation in financial modelling. Annals of Operations Research, 193(1), 129–158. doi:10.1007/s10479-011-0862-y.
Gimeno, R., & Pineda, J. M. N. (2006). Genetic algorithm estimation of interest rate term structure. Documentos de trabajo del Banco de España, (34), 9–36.
Gürkaynak, R. S., Sack, B., & Wright, J. H. (2007). The US Treasury yield curve: 1961 to the present. Journal of Monetary Economics, 54(8), 2291–2304.
Ioannides, M. (2003). A comparison of yield curve estimation techniques using UK data. Journal of Banking and Finance, 27, 1–26.
Judd, K. L. (1998). Numerical methods in economics. Cambridge, MA: MIT Press.
Kirkpatrick, S., Gelatt, C., & Vecchi, M. (1983). Optimization by simulated annealing. Science, 220, 671–680.
Lagarias, J., Reeds, J., Wright, M., & Wright, P. (1965). Convergence properties of the Nelder–Mead simplex method in low dimensions. SIAM Journal on Optimization, 9, 112–147.
Lekkos, I. (2001). Factor models and the correlation structure of interest rates: Some evidence for USD, GBP, DEM and JPY. Journal of Banking and Finance, 8(25), 1427–1445.
Litterman, R., & Scheinkman, J. (1991). Common factors affecting bond returns. Journal of Fixed Income, 1, 54–61.
Litterman, R., & Scheinkman, J. (1994). Explorations into factors explaining money market returns. Journal of Finance, 49, 1861–1882.
Manousopoulos, P., & Michalopoulosa, M. (2007). Comparison of non-linear optimization algorithms for yield curve estimation. European Journal of Operational Research, 192, 594–602.
Nelder, J. A., & Mead, R. (1965). A simplex method for function minimization. Computer Journal, 7, 308–313.
Nelson, C. R., & Siegel, A. F. (1987). Parsimonious modeling of yield curves. The Journal of Business, 60(4), 473–489.
Pedersen, M. E. H., & Chipperfield, A. J. (2010). Simplifying particle swarm optimization. Applied Soft Computing, 10(2), 618–628.
Powell, M. J. D. (1964). An efficient method for finding the minimum of a function of several variables without calculating derivatives. Computer Journal, 7, 155–162.
Shi, Y., & Eberhart, R. (1998). A modified particle swarm optimizer. Evolutionary Computation Proceedings, IEEE World Congress on Computational Intelligence, pp. 69–73.
Svensson, L. E. O. (1994). Estimating and interpreting forward interest rates: Sweden 1992–1994. National Bureau of Economic Research, Working Paper #4871.
Trelea, I. C. (2003). The particle swarm optimization algorithm: Convergence analysis and parameter selection. Information Processing Letters, 85, 317–325.
Yallup, P. J. (2012). Models of the yield curve and the curvature of the implied forward rate function. Journal of Banking and Finance, 36(1), 121–135.
Author information
Authors and Affiliations
Corresponding author
Appendix
Appendix
1.1 Global optimization algorithms
The objective of global optimization is to find the globally best solution of (possibly non-linear) models, in the presence of multiple local optima.
1.1.1 Particle swarm optimization
PSO is a population-based metaheuristic technique. It is a fast converging algorithm, is easy to implement, and has been successfully applied to optimizing various continuous nonlinear functions in other applications.Footnote 24 PSO has not previously been applied to term structure estimation. PSO is essentially inspired from the social behaviour of the individuals. In a simple social setting, decision process of each individual is affected by his own experiences and other individual’s experiences. Every individual keeps a memory of their best choice, as well as the overall best choice of the population. In our PSO setting, for each observation day, dataset a set of particles search for good solutions to the NSS term structure fitting optimization problem as described in Sects. 2.2 and 2.3. Each particle is a solution of the NSS optimization problem and uses its own experience and also the experience of neighbour particles to choose how to move in the search space to find a better fitting term structure.
The PSO algorithm is initialized with a population of random candidate solutions, called particles. Each particle is assigned a random location and a random velocity, and is iteratively moved through the problem space. Every particle is attracted towards the location of the best solution achieved by the particle itself and towards the location of the best solution achieved across the whole population. At each iteration, velocity vector (\(v_i\)) and position (parameter) vector (\(\varTheta _i\)) of a particle is updated as follows:
where the \(U(0,\phi _i)\) are scalars uniformly distributed in the interval \([0,\phi _i]\), \(pb_i\) is the best known position of particle i, and gb is the best known position across the entire population. The parameters \(\phi _1\) and \(\phi _2\) denote the magnitude of the random forces in the direction of personal best \(pb_i\) and swarm best gb. The components \(U(0,\phi _1) \otimes (pb_i-\varTheta _i)\) and \(U(0,\phi _2) \otimes (gb-\varTheta _i)\) can be interpreted as attractive forces produced by springs of random stiffness.
PSO is an unconstrained optimization algorithm, which required us to handle the constraints in the objective function. To this end we added a penalty function that is a scalar value times the square of the violation of constraint \(c_{i}\) to the objective i.e
where C is large scalar value. Thus, the optimization problem becomes:
There are several variants of the original PSO algorithm. Shi and Eberhart (1998) developed a variant which we call PSO-W. They modify the updating of the velocity vector to place decreasing weight on the last value, and thereby increasing weight on the individual and global bests as the iteration count increases:
where \(\omega \) is termed the inertia weight, and \(0<\omega _p<1\) is the decay factor. Effectively, the inertia weight preserves the initial random search direction, the magnitude of which decreases over iterations.

Another variant of PSO was proposed by Pedersen and Chipperfield (2010). This variant, named as PSO-G, disregards the personal best values and focuses on the neighborhood of the population best.

Our computational experiments show that the best results were obtained when PSO-W and PSO-G were applied sequentially. This method will be referred to as Hybrid PSO for the rest of the study.

1.1.2 Simulated annealing
Simulated annealing (SA) algorithm, proposed by Kirkpatrick et al. (1983), is a probabilistic local search algorithm that looks for the minimum of an objective function using the neighborhood information of a point in the search space. The name and inspiration of the algorithm come from annealing in metallurgy, a technique involving heating and controlled cooling of a material to increase the size of its crystals and reduce their defects. The heat causes the atoms to become unstuck from their initial positions (a local minimum of the internal energy) and wander randomly through states of higher energy; the slow cooling gives them more chances of finding configurations with lower internal energy than the initial one. By analogy with this physical process, each step of the SA algorithm replaces the current solution by a random “nearby” solution, chosen with a probability that depends both on the difference between the corresponding function values and also on a global parameter T (called the temperature), that is gradually decreased during the process.
Local search algorithms usually start with a random initial solution. A neighbour of this solution is then generated by some suitable mechanism and the change in cost is calculated. Neighbors are chosen as a network topology where the local optima are shallow or a similar topology where there are many deep local minima. If a reduction in cost is found, the current solution is replaced by the generated neighbour, otherwise the current solution is retained. The process is then repeated until no further improvement can be found in the neighbourhood of the current solution and the algorithm terminates at a local minimum. In SA, sometimes a neighbour that increases the cost is accepted, to avoid becoming trapped in a local optimum. A move that does not improve the solution is accepted with a probability that decreases with iterations. Usually, the probability is selected as \(e^{-\delta /T}\) where \(\delta \) is the increase in the objective function value at each iteration and T is a control parameter.

1.2 Direct search algorithms
Direct search is a class of methods for solving optimization problems that does not require any information about the gradient of the objective function. Direct search algorithms search a set of points around the current point, looking for one where the value of the objective function is lower than the value at the current point.
1.2.1 Nelder–Mead method
Nelder–Mead method is based on the idea of a “simplex”, which refers to the generalized form of a triangle in \(n \ge 2\) dimensions. The algorithm is initialized with \(n+1\) solutions, which form a simplex in \(R^n\). The midpoint of all initial solutions excluding the worst one, is computed first. The reflection of the worst solution with respect to this midpoint is then determined as a candidate solution. Based on the parameters of the algorithm, expanded and contracted points on the line connecting the worst point and the midpoint are also determined as candidate solutions. Finally, n more candidates are generated by shrinking the simplex towards the best solution, and determining the new corners of the simplex. The best solution among all candidates then replaces the worst solution, and the algorithm is iterated until the worst solution cannot be improved.
The Nelder–Mead method (Nelder and Mead 1965; Lagarias et al. 1965) uses four scalar parameters: \(\rho \) (reflection), \(\chi \) (expansion), \(\gamma \) (contraction), \(\sigma \) (shrinkage). Let the vertices are denoted as \(\varTheta ^{(1)},\varTheta ^{(2)},\ldots \varTheta ^{(n+1)}\) where n is the number of parameters to be estimated.

1.2.2 Powell’s method
Powell’s algorithm (Powell (1964)) is a generalization of a straightforward and intuitive optimization algorithm, called the “taxi-cab” algorithm. The taxi-cab algorithm has n search directions, usually the unit vectors in every dimension. The algorithm starts with an initial solution and search directions are evaluated sequentially. The best possible improvement is found in a search direction (through line minimization methods such as Golden section search), and is applied before moving on to the next search direction. The innovation of the Powell’s algorithm over the taxi-cab algorithm is the idea of updating the search directions based on the history of the search. Every time an improving solution is found, one of the search directions is replaced by the vector connecting the current solution and the improving solution, as it proved to be a good search direction.

1.3 Gradient based algorithms
Gradient based optimization algorithms iteratively search for a minimum by computing (or approximating) the gradient of the objective function. We use two popular and efficient gradient based optimization algorithms, namely Broyden–Fletcher–Goldfarb–Shanno algorithm (BFGS) and Gauss–Newton method. One of the key advantage of these algorithms compared to global and direct search algorithms is their theoretical capability of using the geometry of NSS parameters space via its function gradient information.
1.3.1 Broyden–Fletcher–Goldfarb–Shanno algorithm
The Broyden–Fletcher–Goldfarb–Shanno (BFGS) algorithm (see Judd (1998)) is a quasi-Newton algorithm which is an iterative procedure with a local quadratic approximation of the function. An approximation of the Hessian of the objective function is used instead of the function itself, which decreases the complexity of the algorithm. As all variants of Newton’s methods, the idea behind them is to start at a point \(\varTheta _0\) and find the quadratic polynomial \(J^0(\varTheta )\) that approximates \(J(\varTheta )\) to its second degree Taylor expansion evaluated at \(\varTheta ^0\):
where \(\nabla \) is the gradient operator, such that:
and \(H = \nabla ^2 J(\varTheta _0)\) is the Hessian matrix of \(J(\varTheta _0)\), that is the symmetric matrix containing the second-order derivatives of \(J\):
Quasi-Newton methods specify \(d_k\) (the direction vector) as:
The step size \(\alpha _k\) is obtained by line minimization, where the direction \(H_k\) is a positive definite matrix, \(H_k\) may be adjusted from one iteration to the next so that \(d_k\) tends to approximate the Newton direction.

1.3.2 Gauss–Newton algorithm
The idea behind the Gauss–Newton algorithm is to build a derivative matrix that contains the derivatives of the function with respect to each variable. After the first iteration, the algorithm modifies the values of the initial guess, as the optimization process goes on the variable values are updated after each iteration, until the algorithm reaches a satisfactory value (from the point of view of the operator) or the error reaches its pre-defined limit. One of the necessity of the algorithm requires the function derivative and its calculation. In the NSS estimation process, the functional form is suitable for calculation of the derivative.

1.4 Implementation details
The algorithms were coded in MATLAB. For Nelder–Mead, Powell, SA and PSO algorithms the constraints have been embedded in objective function with a penalty constant \(C = 1000\), whereas they have been explicitly stated for BFGS. Stopping criterion for the algorithms has been chosen as \(\epsilon =10^{-8}\). Parameter set for the Nelder–Mead algorithm is chosen as \(\rho =1, \chi =2, \gamma =0.5, \sigma =0.5\). For the SA algorithm, initial value of T is chosen as 1.
Rights and permissions
About this article

Cite this article
Ahi, E., Akgiray, V. & Sener, E. Robust term structure estimation in developed and emerging markets. Ann Oper Res 260, 23–49 (2018). https://doi.org/10.1007/s10479-016-2282-5
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10479-016-2282-5