
Abstract
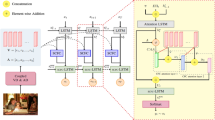
Image captioning is a cross-modal task to describe an image into descriptions. The commonly used image captioning methods include the generation-based and the retrieval-based method. In this paper, we propose a feature enhanced image captioning model, which is mainly made up of three parts: cross-modal feature enhanced module (CFD), gated feature fusion (GFF), cross-modal decoder. The retrieval-based method first retrieved the semantic related similar sentences for each image. CFD mutually coarse aligned the region-based visual features with the word-based similar sentences. GFF further performs a deeper interaction for the coarse aligned visual and semantic features through a dynamic gate to control the fusion level, and get the fine aligned features. We concatenated the two sets fine aligned features as the enhanced features. Both the visual relationship features and the enhanced features guide the cross-modal decoder generate the description. Our model got 131.0 and 68.3 CIDEr score when it compared with different methods on MSCOCO and Flickr30k. Further ablation studies also demonstrate the effectiveness of each component.




Similar content being viewed by others


References
Das A, Kottur S, Gupta K, Singh A, Yadav D, Moura JM, Parikh D, Batra D (2017) Visual dialog. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 326–335
Chen H, Ding G, Liu X, Lin Z, Liu J, Han J (2020) Imram: iterative matching with recurrent attention memory for cross-modal image-text retrieval. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 12655– 12663
Hou C, Li Z, Wu J (2021) Unsupervised hash retrieval based on multiple similarity matrices and text self-attention mechanism. Appl Intell:1–16
Wang Z, Liu X, Li H, Sheng L, Yan J, Wang X, Shao J (2019) Camp: cross-modal adaptive message passing for text-image retrieval. In: Proceedings of the IEEE/CVF international conference on computer vision, pp 5764–5773
Wang L, Bai Z, Zhang Y, Lu H (2020) Show, recall, and tell: image captioning with recall mechanism. In: Proceedings of the AAAI conference on artificial intelligence, vol 34, pp 12176–12183
Mun J, Cho M, Han B (2017) Text-guided attention model for image captioning. In: Proceedings of the AAAI conference on artificial intelligence, vol 31
Kuznetsova P, Ordonez V, Berg TL, Choi Y (2014) Treetalk: composition and compression of trees for image descriptions. Trans Assoc Comput Linguist 2:351–362
Gong Y, Wang L, Hodosh M, Hockenmaier J, Lazebnik S (2014) Improving image-sentence embeddings using large weakly annotated photo collections. In: European conference on computer vision. Springer, pp 529–545
Karpathy A, Fei-Fei L (2015) Deep visual-semantic alignments for generating image descriptions. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 3128–3137
Vinyals O, Toshev A, Bengio S, Erhan D (2017) Show and tell: Lessons learned from the 2015 mscoco image captioning challenge. IEEE Trans Pattern Anal Mach Intell 39(4):652–663
Xu K, Ba J, Kiros R, Cho K, Courville A, Salakhudinov R, Zemel R, Bengio Y (2015) Show, attend and tell: neural image caption generation with visual attention. In: International conference on machine learning, pp 2048–2057
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, Kaiser Ł, Polosukhin I (2017) Attention is all you need. In: Advances in neural information processing systems, pp 5998–6008
Bhunia AK, Perla SRK, Mukherjee P, Das A, Roy PP (2019) Texture synthesis guided deep hashing for texture image retrieval. In: 2019 IEEE winter conference on applications of computer vision (WACV). IEEE, pp 609–618
Bhunia AK, Bhattacharyya A, Banerjee P, Roy PP, Murala S (2020) A novel feature descriptor for image retrieval by combining modified color histogram and diagonally symmetric co-occurrence texture pattern. Pattern Anal Applic 23(2):703–723
Ordonez V, Kulkarni G, Berg T (2011) Im2text: describing images using 1 million captioned photographs. Adv Neural Inf Process Syst 24:1143–1151
Hodosh M, Young P, Hockenmaier J (2013) Framing image description as a ranking task: data, models and evaluation metrics. J Artif Intell Res 47:853–899
Agrawal P, Yadav R, Yadav V, De K, Pratim Roy P (2020) Caption-based region extraction in images. In: Proceedings of 3rd international conference on computer vision and image processing. Springer, pp 27–38
Lu J, Xiong C, Parikh D, Socher R (2017) Knowing when to look: adaptive attention via a visual sentinel for image captioning. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 375–383
Yao T, Pan Y, Li Y, Qiu Z, Mei T (2017) Boosting image captioning with attributes. In: Proceedings of the IEEE international conference on computer vision, pp 4894–4902
Chen L, Zhang H, Xiao J, Nie L, Shao J, Liu W, Chua T. -S. (2017) Sca-cnn: spatial and channel-wise attention in convolutional networks for image captioning. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 5659–5667
Anderson P, He X, Buehler C, Teney D, Johnson M, Gould S, Zhang L (2018) Bottom-up and top-down attention for image captioning and visual question answering. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 6077–6086
Krishna R, Zhu Y, Groth O, Johnson J, Hata K, Kravitz J, Chen S, Kalantidis Y, Li L-J, Shamma DA et al (2017) Visual genome: connecting language and vision using crowdsourced dense image annotations. Int J Comput Vision 123(1):32–73
Rennie SJ, Marcheret E, Mroueh Y, Ross J, Goel V (2017) Self-critical sequence training for image captioning. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 7008–7024
Wei H, Li Z, Huang F, Zhang C, Ma H, Shi Z (2021) Integrating scene semantic knowledge into image captioning. ACM Trans Multimed Comput Communi Appl (TOMM) 17(2):1–22
Yao T, Pan Y, Li Y, Mei T (2018) Exploring visual relationship for image captioning. In: Proceedings of the European conference on computer vision (ECCV), pp 684–699
Yang X, Tang K, Zhang H, Cai J (2019) Auto-encoding scene graphs for image captioning. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 10685–10694
Zhu X, Li L, Liu J, Peng H, Niu X (2018) Captioning transformer with stacked attention modules. Appl Sci 8(5):739
Cornia M, Stefanini M, Baraldi L, Cucchiara R (2020) Meshed-memory transformer for image captioning. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 10578–10587
Liu J, Wang K, Xu C, Zhao Z, Xu R, Shen Y, Yang M (2020) Interactive dual generative adversarial networks for image captioning. In: Proceedings of the AAAI conference on artificial intelligence, vol 34, pp 11588–11595
Zhao W, Wu X, Luo J (2020) Cross-domain image captioning via cross-modal retrieval and model adaptation. IEEE Trans Image Process 30:1180–1192
Yang M, Liu J, Shen Y, Zhao Z, Chen X, Wu Q, Li C (2020) An ensemble of generation-and retrieval-based image captioning with dual generator generative adversarial network. IEEE Trans Image Process 29:9627–9640
Lin T-Y, Maire M, Belongie S, Hays J, Perona P, Ramanan D, Dollár P, Zitnick CL (2014) Microsoft coco: common objects in context. In: European conference on computer vision. Springer, pp 740–755
Papineni K, Roukos S, Ward T, Zhu W-J (2002) Bleu: a method for automatic evaluation of machine translation. In: Proceedings of the 40th annual meeting on association for computational linguistics. Association for Computational Linguistics, pp 311–318
Banerjee S, Lavie A (2005) Meteor: an automatic metric for mt evaluation with improved correlation with human judgments. In: Proceedings of the Acl workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization, pp 65–72
Vedantam R, Lawrence Zitnick C, Parikh D (2015) Cider: consensus-based image description evaluation. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 4566–4575
Anderson P, Fernando B, Johnson M, Gould S (2016) Spice: Semantic propositional image caption evaluation. In: European conference on computer vision. Springer, pp 382–398
Luo R, Price B, Cohen S, Shakhnarovich G (2018) Discriminability objective for training descriptive captions. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 6964–6974
Huang L, Wang W, Chen J, Wei X-Y (2019) Attention on attention for image captioning. In: Proceedings of the IEEE/CVF international conference on computer vision, pp 4634–4643
Li G, Zhu L, Liu P, Yang Y (2019) Entangled transformer for image captioning. In: Proceedings of the IEEE/CVF international conference on computer vision, pp 8928–8937
Wang J, Xu W, Wang Q, Chan AB (2020) Compare and reweight: distinctive image captioning using similar images sets. In: European conference on computer vision. Springer, pp 370–386
Nie W, Li J, Xu N, Liu A-A, Li X, Zhang Y (2021) Triangle-reward reinforcement learning: a visual-linguistic semantic alignment for image captioning. In: Proceedings of the 29th ACM international conference on multimedia, pp 4510–4518
Guo L, Liu J, Tang J, Li J, Luo W, Lu H (2019) Aligning linguistic words and visual semantic units for image captioning. In: Proceedings of the 27th ACM international conference on multimedia, pp 765–773
Huang Y, Chen J, Ouyang W, Wan W, Xue Y (2020) Image captioning with end-to-end attribute detection and subsequent attributes prediction. IEEE Trans Image Process 29:4013–4026
Yao T, Pan Y, Li Y, Mei T (2019) Hierarchy parsing for image captioning. In: Proceedings of the IEEE/CVF international conference on computer vision, pp 2621–2629
Liu F, Ren X, Liu Y, Lei K, Sun X (2019) Exploring and distilling cross-modal information for image captioning. In: IJCAI
Liu W, Chen S, Guo L, Zhu X, Liu J (2021) Cptr: full transformer network for image captioning. arXiv:2101.10804
Lu J, Yang J, Batra D, Parikh D (2018) Neural baby talk. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 7219–7228
Zhou L, Kalantidis Y, Chen X, Corso JJ, Rohrbach M (2019) Grounded video description. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 6578–6587
Gao L, Fan K, Song J, Liu X, Xu X, Shen HT (2019) Deliberate attention networks for image captioning. In: Proceedings of the AAAI conference on artificial intelligence, vol 33, pp 8320– 8327
Cai W, Liu Q (2020) Image captioning with semantic-enhanced features and extremely hard negative examples. Neurocomputing 413:31–40
Acknowledgements
The authors would thank the editor and all the anonymous referees for their valuable comments which would help us to improve this paper. This work was supported by the National Key Research and Development Program of China (Grant No. 2020YFB1805403), the National Natural Science Foundation of China (Grant Nos. 62032002, 61932005), the Natural Science Foundation of Beijing Municipality (Grant No. M21034) and the 111 Projet (Grant No. B21049).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Lixiang Li and Haipeng Peng contributed equally to this work.
Rights and permissions
Springer Nature or its licensor holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Zhao, S., Li, L. & Peng, H. Incorporating retrieval-based method for feature enhanced image captioning. Appl Intell 53, 9731–9743 (2023). https://doi.org/10.1007/s10489-022-04010-4
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10489-022-04010-4