
Abstract
Common binary classification algorithms which learn directly from imbalanced data can lead to a bias towards the majority class. Although the over-sampling technology can solve the imbalance problem, the realness of the synthesized samples cannot be guaranteed. Generative Adversarial Networks can improve the authenticity of the generated samples. However, it may cause mode collapse, resulting in the data distribution space of the minority class changed after balance. A sample-level data generation method is proposed in this paper for imbalanced classification. Firstly, we present a reconstruction technique of latent codes with mutual information constraints for global data generation. The latent codes of the input sample are divided into latent vectors of key features and subordinate features respectively. We can obtain the mutated latent codes by retaining the key features’ latent vector and randomly replacing the subordinate features’ latent vector. Then the reliable similar mutation samples are generated through decoder restoration, mutual information constraint, and discriminant confrontation. In addition, the feature repulsion technique and the combination coding technique are proposed to solve the problem of feature extraction and classification for samples in overlapping areas. The former carries out supervised feature representation learning of the key features’ latent vector. The latter superimposes the reconstruction error of each dimension of the sample as a supplement for the latent vector of key features. Combined with a variety of typical base classifiers, a large number of experimental results on public datasets show that the proposed method outperforms other typical data balancing methods in F1-Measure and G-Mean.









Similar content being viewed by others
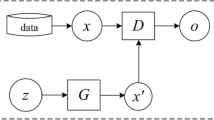


Data Availability
The datasets supporting the results of this article are all from UCI and KEEL public database.
Code Availability
Custom code
References
Chao YR, Zipf GK (1950) Human behavior and the principle of least effort: An introduction to human ecology. Language 26:394. https://doi.org/10.2307/409735
Nicholson M, Agrahari R, Conran C, Assem H, Kelleher JD (2022) The interaction of normalisation and clustering in sub-domain definition for multi-source transfer learning based time series anomaly detection. Knowl-Based Syst 257:109894. https://doi.org/10.1016/j.knosys.2022.109894
Baik R (2019) Class imbalance learning–driven Alzheimer’s detection using hybrid features. Int J Distrib Sensor Netw 15:1550147719826048. https://doi.org/10.1177/1550147719826048
Ahammad J, Hossain N, Alam MS (2020) Credit card fraud detection using data pre-processing on imbalanced data - both oversampling and undersampling. ACM, pp 1–4. https://doi.org/10.1145/3377049.3377113
Soon HF, Amir A, Azemi SN (2021) An analysis of multiclass imbalanced data problem in machine learning for network attack detections. In: Journal of physics: Conference series, vol 1755. IOP Publishing, p 012030. https://doi.org/10.1109/LSENS.2018.2879990
Zhai J, Qi J, Shen C (2022) Binary imbalanced data classification based on diversity oversampling by generative models. Inform Sci 585:313–343. https://doi.org/10.1016/j.ins.2021.11.058
Yan J, Zhang Z, Lin K, Yang F, Luo X (2020) A hybrid scheme-based one-vs-all decision trees for multi-class classification tasks. Knowl-Based Syst 198:105922. https://doi.org/10.1016/j.knosys.2020.105922
Özdemir A, Polat K, Alhudhaif A (2021) Classification of imbalanced hyperspectral images using smote-based deep learning methods. Expert Syst Appl 178:114986. https://doi.org/10.1016/j.eswa.2021.114986
Yang Y, Huang S, Huang W, Chang X (2021) Privacy-preserving cost-sensitive learning. IEEE Trans Neural Netw Learn Syst 32:2105–2116. https://doi.org/10.1109/TNNLS.2020.2996972
Zhao X, Wu Y, Lee DL, Cui W (2019) Iforest: Interpreting random forests via visual analytics. IEEE Trans Vis Comput Graph 25:407–416. https://doi.org/10.1109/TVCG.2018.2864475
Wang B, Mao Z (2019) Outlier detection based on a dynamic ensemble model: Applied to process monitoring. Inf Fusion 51:244–258. https://doi.org/10.1016/J.INFFUS.2019.02.006
Shen F, Liu Y, Wang R, Zhou W (2020) A dynamic financial distress forecast model with multiple forecast results under unbalanced data environment. Knowl-Based Syst 192:105365. https://doi.org/10.1016/j.knosys.2019.105365
Saleh M, Tabrizchi H, Rafsanjanim M, Gupta BB, Palmieri F (2021) A combination of clustering-based under-sampling with ensemble methods for solving imbalanced class problem in intelligent systems. Technol Forecast Soc Chang 169:120796. https://doi.org/10.1016/j.techfore.2021.120796
Guzmán-Ponce A, Sánchez J, Valdovinos R, Marcial-Romero J (2021) DBIG-US: A two-stage under-sampling algorithm to face the class imbalance problem. Expert Syst Appl 168:114301. https://doi.org/10.1016/j.eswa.2020.114301, https://linkinghub.elsevier.com/retrieve/pii/S0957417420310009
Le HL, Landa-Silva D, Galar M, Garcia S, Triguero I (2021) EUSC: A clustering-based surrogate model to accelerate evolutionary undersampling in imbalanced classification. Appl Soft Comput 101:107033. https://doi.org/10.1016/j.asoc.2020.107033
Japkowicz N (2000) The class imbalance problem: Significance and strategies. Proceedings of the 2000 International Conference on Artificial Intelligence
Chawla NV, Bowyer KW, Hall LO, Kegelmeyer WP (2002) Smote: Synthetic minority over-sampling technique. J Artif Intell Res 16:321–357. https://doi.org/10.1613/jair.953
Douzas G, Bacao F, Last F (2018) Improving imbalanced learning through a heuristic oversampling method based on k-means and SMOTE. Inform Sci 465:1–20. https://doi.org/10.1016/j.ins.2018.06.056
Fujiwara K, Huang Y, Hori K, Nishioji K, Kobayashi M, Kamaguchi M, Kano M (2020) Over- and under-sampling approach for extremely imbalanced and small minority data problem in health record analysis. Front Public Health 8:178. https://doi.org/10.3389/fpubh.2020.00178
Gao X, Ren B, Zhang H, Sun B, Li J, Xu J, He Y, Li K (2020) An ensemble imbalanced classification method based on model dynamic selection driven by data partition hybrid sampling. Expert Syst Appl 160:113660. https://doi.org/10.1016/j.eswa.2020.113660
García-Ordás MT, Benítez-Andrades JA, García-Rodríguez I, Benavides C, Alaiz-Moretón H (2020) Detecting respiratory pathologies using convolutional neural networks and variational autoencoders for unbalancing data. Sensors 20:1214. https://doi.org/10.3390/s20041214
Deng X, Dai Z, Sun M, Lv T (2020) Variational autoencoder based enhanced behavior characteristics classification for social robot detection, vol 1268 CCIS. https://doi.org/10.1007/978-981-15-9129-7_17
Zhou F, Yang S, Fujita H, Chen D, Wen C (2020) Deep learning fault diagnosis method based on global optimization GAN for unbalanced data. Knowl-Based Syst 187:104837. https://doi.org/10.1016/j.knosys.2019.07.008
Kingma DP, Welling M (2014) Auto-encoding variational bayes. 2nd International Conference on Learning Representations, ICLR 2014 - Conference Track Proceedings
Goodfellow I, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, Courville A, Bengio Y (2020) Generative adversarial networks. Commun ACM 63:139–144. https://doi.org/10.1145/3422622
Thanh-Tung H, Tran T (2020) Catastrophic forgetting and mode collapse in GANS. IEEE, 1–10. https://doi.org/10.1109/IJCNN48605.2020.9207181
Cover T, Hart P (1967) Nearest neighbor pattern classification. IEEE Trans Inf Theory 13:21–27. https://doi.org/10.1109/TIT.1967.1053964
Calleja JDL, Fuentes O (2007) A distance-based over-sampling method for learning from imbalanced data sets
Sandhan T, Choi JY (2014) Handling imbalanced datasets by partially guided hybrid sampling for pattern recognition. IEEE, pp 1449–1453. https://doi.org/10.1109/ICPR.2014.258
Douzas G, Bacao F (2017) Self-organizing map oversampling (SOMO) for imbalanced data set learning. Expert Syst Appl 82:40–52. https://doi.org/10.1016/j.eswa.2017.03.073
Han H, Wang WY, Mao BH (2005) Borderline-SMOTE: A new over-sampling method in imbalanced data sets learning, vol 3644. https://doi.org/10.1007/11538059_91
Bunkhumpornpat C, Sinapiromsaran K, Lursinsap C (2009) Safe-Level-SMOTE: Safe-level-synthetic minority over-sampling TEchnique for handling the class imbalanced problem, vol 5476 LNAI. https://doi.org/10.1007/978-3-642-01307-2_43
Reivich M, Kuhl D, Wolf A, Greenberg J, Phelps M, Ido T, Casella V, Fowler J, Hoffman E, Alavi A, Som P, Sokoloff L (1979) The [18f]fluorodeoxyglucose method for the measurement of local cerebral glucose utilization in man. Circ Res 44:127–137. https://doi.org/10.1161/01.RES.44.1.127
Krishna K, Murty MN (1999) Genetic k-means algorithm. IEEE Trans Syst Man and Cybern Part B (Cybernetics) 29:433–439. https://doi.org/10.1109/3477.764879
Li J, Zhu Q, Wu Q, Zhang Z, Gong Y, He Z, Zhu F (2021) Smote-nan-de: Addressing the noisy and borderline examples problem in imbalanced classification by natural neighbors and differential evolution. Knowl-Based Syst 223:107056. https://doi.org/10.1016/j.knosys.2021.107056
Dablain D, Krawczyk B, Chawla NV (2022) Deepsmote: Fusing deep learning and smote for imbalanced data. IEEE Transactions on Neural Networks and Learning Systems. https://doi.org/10.1109/TNNLS.2021.3136503
Fiore U, Santis AD, Perla F, Zanetti P, Palmieri F (2019) Using generative adversarial networks for improving classification effectiveness in credit card fraud detection. Inform Sci 479:448–455. https://doi.org/10.1016/j.ins.2017.12.030
Arjovsky M, Chintala S, Bottou L (2017) Wasserstein generative adversarial networks. vol 1
Gentle JE, McLachlan GJ, Krishnan T (1998) The em algorithm and extensions. Biometrics 54:395. https://doi.org/10.2307/2534032
Gulrajani I, Ahmed F, Arjovsky M, Dumoulin V, Courville A (2017) Improved training of wasserstein gans. vol 2017-December
Zheng M, Li T, Zhu R, Tang Y, Tang M, Lin L, Ma Z (2020) Conditional wasserstein generative adversarial network-gradient penalty-based approach to alleviating imbalanced data classification. Inform Sci 512:1009–1023. https://doi.org/10.1016/j.ins.2019.10.014
Douzas G, Bacao F (2018) Effective data generation for imbalanced learning using conditional generative adversarial networks. Expert Syst Appl 91:464–471. https://doi.org/10.1016/j.eswa.2017.09.030
Huang K, Wang X (2021) ADA-INCVAE: Improved data generation using variational autoencoder for imbalanced classification. Applied Intelligence. https://doi.org/10.1007/s10489-021-02566-1
Larsen ABL, Sønderby SK, Larochelle H, Winther O (2016) Autoencoding beyond pixels using a learned similarity metric. vol 4
Chen X, Duan Y, Houthooft R, Schulman J, Sutskever I, Abbeel P (2016) Infogan: Interpretable representation learning by information maximizing generative adversarial nets
Hosmer DW, Lemeshow S, Sturdivant RX (2013) Applied logistic regression. Wiley, New York
Janik P, Lobos T (2006) Automated classification of power-quality disturbances using SVM and RBF networks. IEEE Trans Power Deliv 21:1663–1669. https://doi.org/10.1109/TPWRD.2006.874114
Breiman L (2001) Random forests. Mach Learn 45:5–32. https://doi.org/10.1023/A:1010933404324
Pedregosa F, Varoquaux G, Gramfort A, Michel V, Thirion B, Grisel O, Blondel M, Prettenhofer P, Weiss R, Dubourg V, Vanderplas J, Passos A, Cournapeau D, Brucher M, Perrot M, Duchesnay Édouard (2011) Scikit-learn: Machine learning in python. J Mach Learn Res 12:2825–2830
Taheri SM, Hesamian G (2013) A generalization of the wilcoxon signed-rank test and its applications. Stat Pap 54:457–470. https://doi.org/10.1007/s00362-012-0443-4
García S, Fernández A, Luengo J, Herrera F (2010) Advanced nonparametric tests for multiple comparisons in the design of experiments in computational intelligence and data mining: Experimental analysis of power. Inform Sci 180:2044–2064. https://doi.org/10.1016/j.ins.2009.12.010
Raghuwanshi BS, Shukla S (2019) Class imbalance learning using underbagging based kernelized extreme learning machine. Neurocomputing 329:172–187. https://doi.org/10.1016/j.neucom.2018.10.056
Pereira DG, Afonso A, Medeiros FM (2015) Overview of friedman’s test and post-hoc analysis. Commun Stat-Simul Comput 44(10):2636–2653. https://doi.org/10.1080/03610918.2014.931971
Acknowledgements
The authors would like to thank their colleagues from the Machine learning group for discussions on this paper.This work was supported by Science and Technology Project of SGCC [Grant No. 5700-202227226A-1-1-ZN].
Funding
This work was supported by Science and Technology Project of SGCC [Grant No. 5700-202227226A-1-1-ZN].
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of Interests
The authors declare that they have no conflict of interest.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Jia, X., Gao, X., Chen, W. et al. Global reliable data generation for imbalanced binary classification with latent codes reconstruction and feature repulsion. Appl Intell 53, 16922–16960 (2023). https://doi.org/10.1007/s10489-022-04330-5
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10489-022-04330-5