
Abstract
Since the audio information is fully explored and leveraged in omnidirectional videos (ODVs), the performance of existing audio-visual saliency models has been improving dramatically and significantly. However, these models are still in their infancy stages, and there are two significant issues in modeling human attention between visual and auditory modalities: (1) Temporal non-alignment problem between auditory and visual modalities is rarely considered; (2) Most audio-visual saliency models are audio content attributes-agnostic. Thus, they need to learn audio features with fine details. This paper proposes a novel audio-visual aligned saliency (AVAS) model that can simultaneously tackle two issues as mentioned above in an effective end-to-end training manner. In order to solve the temporal non-alignment problem between the two modalities, a Hanning window method is employed on the audio stream to truncate the audio signal per unit time (frame-time interval) to match the visual information stream of the corresponding duration, which can capture the potential correlation of two modalities across time steps and facilitate audio-visual features fusion. Regarding the audio content attribute-agnostic issue, an effective periodic audio encoding method is proposed based on implicit neural representation (INR) to map audio sampling points to their corresponding audio frequency values, which can better discriminate and interpret audio content attributes. Comprehensive experiments and detailed ablation analyses are performed on the benchmark dataset to demonstrate the efficacy of the proposed model. The experimental results indicate that the proposed model consistently outperforms other competitors by a large margin.










Similar content being viewed by others

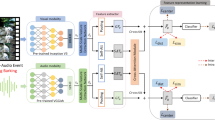

References
Liu H, Liu T, Zhang Z, Sangaiah AK, Yang B, Li Y (2022) ARHPE: Asymmetric relation-aware representation learning for head pose estimation in industrial human-computer interaction. IEEE Trans Industr Inf 18(10):7107–7117
Hu-Au E, Lee JJ (2017) Virtual reality in education: a tool for learning in the experience age. Int J Innov Educ Res 4(4):215–226
Li Z, Liu H, Zhang Z, Liu T, Xiong NN (2021) Learning knowledge graph embedding with heterogeneous relation attention networks. IEEE Trans Neural Netw Learn Syst 33(8):3961–3973
Liu H, Zheng C, Li D, Shen X, Lin K, Wang J, Zhang Z, Zhang Z, Xiong NN (2021) EDMF: efficient deep matrix factorization with review feature learning for industrial recommender system. IEEE Trans Industr Inf 18(7):4361–4371
Kruzan KP, Won AS (2019) Embodied well-being through two media technologies: Virtual reality and social media. New Media Soc 21(8):1734–1749
Liu H, Liu T, Chen Y, Zhang Z, Li YF (2022) EHPE: skeleton cues-based gaussian coordinate encoding for efficient human pose estimation. IEEE Trans Multimedia. pp 1–12. https://doi.org/10.1109/TMM.2022.3197364
Ferguson C, Davidson PM, Scott PJ, Jackson D, Hickman LD (2015) Augmented reality, virtual reality and gaming: an integral part of nursing
Cheng HT, Chao CH, Dong JD, Wen HK, Liu TL, Sun M (2018) Cube padding for weakly-supervised saliency prediction in 360 videos. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp 1420–1429
Xu Y, Dong Y, Wu J, Sun Z, Shi Z, Yu J, Gao S (2018) Gaze prediction in dynamic 360 immersive videos. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 5333–5342
Chao FY, Ozcinar C, Zhang L, Hamidouche W, Deforges O, Smolic A (2020) Towards audio-visual saliency prediction for omnidirectional video with spatial audio. In: 2020 IEEE International Conference on Visual Communications and Image Processing (VCIP). IEEE, pp 355–358
Chao FY, Ozcinar C, Wang C, Zerman E, Zhang L, Hamidouche W, Deforges O, Smolic A (2020) Audio-visual perception of omnidirectional video for virtual reality applications. In: 2020 IEEE International Conference on Multimedia & Expo Workshops (ICMEW). IEEE, pp 1–6
Marat S, Ho Phuoc T, Granjon L, Guyader N, Pellerin D, Guérin-Dugué A (2009) Modelling spatio-temporal saliency to predict gaze direction for short videos. Int J Comput Vision 82(3):231–243
Rudoy D, Goldman DB, Shechtman E, Zelnik-Manor L (2013) Learning video saliency from human gaze using candidate selection. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp 1147–1154
Zhong SH, Liu Y, Ren F, Zhang J, Ren T (2013) Video saliency detection via dynamic consistent spatio-temporal attention modelling. In: Twenty-seventh AAAI Conference on Artificial Intelligence. pp 1063–1069
Gorji S, Clark JJ (2018) Going from image to video saliency: augmenting image salience with dynamic attentional push. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp 7501–7511
Jiang L, Xu M, Liu T, Qiao M, Wang Z (2018) DeepVS: a deep learning based video saliency prediction approach. In: Proceedings of the European Conference on Computer Vision (ECCV). pp 602–617
Wang W, Shen J, Shao L (2017) Video salient object detection via fully convolutional networks. IEEE Trans Image Process 27(1):38–49
Wang W, Shen J, Xie J, Cheng MM, Ling H, Borji A (2019) Revisiting video saliency prediction in the deep learning era. IEEE Trans Pattern Anal Mach Intell 43(1):220–237
Gao D, Mahadevan V, Vasconcelos N (2008) On the plausibility of the discriminant center-surround hypothesis for visual saliency. J Vis 8(7):13–13
Mahadevan V, Vasconcelos N (2009) Spatiotemporal saliency in dynamic scenes. IEEE Trans Pattern Anal Mach Intell 32(1):171–177
Le Meur O, Le Callet P, Barba D (2007) Predicting visual fixations on video based on low-level visual features. Vision Res 47(19):2483–2498
Fang Y, Zhang X, Yuan F, Imamoglu N, Liu H (2019) Video saliency detection by gestalt theory. Pattern Recogn 96:106987
Liu H, Fang S, Zhang Z, Li D, Lin K, Wang J (2021) MFDnet: Collaborative poses perception and matrix fisher distribution for head pose estimation. IEEE Trans Multimedia 24:2449–2460
Liu H, Wang X, Zhang W, Zhang Z, Li YF (2020) Infrared head pose estimation with multi-scales feature fusion on the irhp database for human attention recognition. Neurocomputing 411:510–520
Liu T, Liu H, Li YF, Chen Z, Zhang Z, Liu S (2019) Flexible ftir spectral imaging enhancement for industrial robot infrared vision sensing. IEEE Trans Industr Inf 16(1):544–554
Liu H, Nie H, Zhang Z, Li YF (2021) Anisotropic angle distribution learning for head pose estimation and attention understanding in human-computer interaction. Neurocomputing 433:310–322
Lai Q, Wang W, Sun H, Shen J (2019) Video saliency prediction using spatiotemporal residual attentive networks. IEEE Trans Image Process 29:1113–1126
Coutrot A, Guyader N (2014) How saliency, faces, and sound influence gaze in dynamic social scenes. J Vis 14(8):5–5
Min X, Zhai G, Gu K, Yang X (2016) Fixation prediction through multimodal analysis. ACM Trans Multimed Comput Commun Appl (TOMM) 13(1):1–23
Min X, Zhai G, Hu C, Gu K (2015) Fixation prediction through multimodal analysis. In: 2015 Visual Communications and Image Processing (VCIP). IEEE, pp 1–4
Rezazadegan Tavakoli H, Borji A, Kannala J, Rahtu E (2020) Deep audio-visual saliency: baseline model and data. pp 1–5. https://doi.org/10.1145/3379156.3391337
Zhu D, Zhao D, Min X, Han T, Zhou Q, Yu S, Chen Y, Zhai G, Yang X (2021) Lavs: a lightweight audio-visual saliency prediction model. In: 2021 IEEE International Conference on Multimedia and Expo (ICME). IEEE, pp 1–6
Tsiami A, Koutras P, Maragos P (2020) Stavis: spatio-temporal audiovisual saliency network. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp 4766–4776
Coutrot A, Guyader N (2014) An audiovisual attention model for natural conversation scenes. In: 2014 IEEE International Conference on Image Processing (ICIP). IEEE, pp 1100–1104
Ozcinar C, Smolic A (2018) Visual attention in omnidirectional video for virtual reality applications. In: 2018 Tenth international conference on quality of multimedia experience (QoMEX). IEEE, pp 1–6
Dahou Y, Tliba M, McGuinness K, O’Connor N (2021) ATSAL: an attention based architecture for saliency prediction in 360 videos. In: International Conference on Pattern Recognition. Springer, pp 305–320
Qiao M, Liu Y, Xu M, Deng X, Li B, Hu W, Borji A (2021) Joint learning of visual-audio saliency prediction and sound source localization on multi-face videos. Int J Comput Vision 20:1–21
Arandjelovic R, Zisserman A (2017) Look, listen and learn. In: Proceedings of the IEEE International Conference on Computer Vision. pp 609–617
Arandjelovic R, Zisserman A (2018) Objects that sound. In: Proceedings of the European Conference on Computer Vision (ECCV). pp 435–451
Korbar B, Tran D, Torresani L (2018) Cooperative learning of audio and video models from self-supervised synchronization. Adv Neural Inf Process Syst 31:7763–7774
Aytar Y, Vondrick C, Torralba A (2016) Soundnet: learning sound representations from unlabeled video. Adv Neural Inf Process Syst 29:892–900
Yu X, Ye X, Zhang S (2022) Floating pollutant image target extraction algorithm based on immune extremum region. Digital Signal Process 123:103442
Yu X, Tian X (2022) A fault detection algorithm for pipeline insulation layer based on immune neural network. Int J Press Vessels Pip 196:104611
He K, Zhang X, Ren S, Sun J (2016) Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 770–778
Zhang Y, Li X, Lin M, Chiu B, Zhao M (2020) Deep-recursive residual network for image semantic segmentation. Neural Comput Appl 32(16):12935–12947
Shen Y, Ji R, Wang Y, Chen Z, Zheng F, Huang F, Wu Y (2020) Enabling deep residual networks for weakly supervised object detection. In: European Conference on Computer Vision. Springer, pp 118–136
Sitzmann V, Martel J, Bergman A, Lindell D, Wetzstein G (2020) Implicit neural representations with periodic activation functions. Adv Neural Inf Process Syst 33:7462–7473
Zhang C, Cui Z, Zhang Y, Zeng B, Pollefeys M, Liu S (2021) Holistic 3D scene understanding from a single image with implicit representation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp 8833–8842
Song G, Pellerin D, Granjon L (2013) Different types of sounds influence gaze differently in videos. J Eye Mov Res 6(4):1–13
Kim JH, Lee SW, Kwak D, Heo MO, Kim J, Ha JW, Zhang BT (2016) Multimodal residual learning for visual QA. Adv Neural Inf Process Syst 29:361–369
Bylinskii Z, Judd T, Oliva A, Torralba A, Durand F (2018) What do different evaluation metrics tell us about saliency models? IEEE Trans Pattern Anal Mach Intell 41(3):740–757
Wang W, Shen J (2017) Deep visual attention prediction. IEEE Trans Image Process 27(5):2368–2378
Cornia M, Baraldi L, Serra G, Cucchiara R (2018) Predicting human eye fixations via an LSTM-based saliency attentive model. IEEE Trans Image Process 27(10):5142–5154
Pan J, Sayrol E, Giro-i Nieto X, McGuinness K, O’Connor NE (2016) Shallow and deep convolutional networks for saliency prediction. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp 598–606
Yang S, Lin G, Jiang Q, Lin W (2019) A dilated inception network for visual saliency prediction. IEEE Trans Multimedia 22(8):2163–2176
Chao FY, Zhang L, Hamidouche W, Deforges O (2018) Salgan360: visual saliency prediction on 360 degree images with generative adversarial networks. In: 2018 IEEE International Conference on Multimedia & Expo Workshops (ICMEW). IEEE, pp 01–04
Sanguineti V, Morerio P, Del Bue A, Murino V (2022) Unsupervised synthetic acoustic image generation for audio-visual scene understanding. IEEE Trans Image Process 31:7102–7115
Li J, Zhai G, Zhu Y, Zhou J, Zhang XP (2022) How sound affects visual attention in omnidirectional videos. In: 2022 IEEE International Conference on Image Processing (ICIP). IEEE, pp 3066–3070
Acknowledgements
This work was supported in part by the Fundamental Research Funds for the Central Universities and the foundation of Key Laboratory of Artificial Intelligence, Ministry of Education, P.R. China and the National Natural Science Foundation of China under Grant 62001289.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
We declare that we do not have any commercial or associative interest that represents a conflict of interest in connection with the work submitted.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Zhu, D., Shao, X., Zhang, K. et al. Audio-visual aligned saliency model for omnidirectional video with implicit neural representation learning. Appl Intell 53, 22615–22634 (2023). https://doi.org/10.1007/s10489-023-04714-1
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10489-023-04714-1