
Abstract
Transformers have attracted increasing interest in time-series forecasting. However, there are two issues for Multi-Head Self-Attention (MHSA) layers in Multivariate Long Sequence Time-series Forecasting (MLSTF): the massive computation resource consumption and the lack of inductive bias for learning the seasonal and trend pattern of time-series sequences. To address these issues, a systematic method is proposed to replace part of the MHSA layers in Transformers with convolutional layers. Specifically, the self-attention patterns are categorized into four types, i.e., diagonal, vertical, block and heterogeneous patterns. The relationships are explored between convolutional layers and MHSA layers exhibiting different self-attention patterns. Based on which, the evaluation metrics are proposed to decide whether to replace MHSA layers with convolutional layers or not. The experimental results on two representative Transformer-based forecasting models show that our method can achieve competitive results with the original Transformer-based forecasting models and greatly reduce their number of parameters and flops. The performance of models on small data sets has also been greatly improved due to the introduction of convolutional operations. Further, this method is adapted to Transformer-based models for other time series tasks and achieves similar results.
Graphical abstract











Similar content being viewed by others


Data Availability
The datasets generated or analyzed during this study are available in the links of Section 4
Notes
Available at https://github.com/zhouhaoyi/ETDataset.
Available at https://www.bgc-jena.mpg.de/wetter/.
Available at http://pems.dot.ca.gov
\(\star \): the replaced model
Available at https://github.com/ZZUFaceBookDL/GTN.
\(\star \): the replaced model
References
Chen K, Du X, Zhu B et al (2022) HTS-AT: a hierarchical token-semantic audio transformer for sound classification and detection. In: IEEE International conference on acoustics, speech and signal processing, ICASSP 2022, Virtual and Singapore, 23-27 May 2022. IEEE, pp 646–650
Chimmula VKR, Zhang L (2020) Time series forecasting of covid-19 transmission in Canada using lstm networks. Chaos, Solitons Fractals 135:109864
Cordonnier J, Loukas A, Jaggi M (2020) On the relationship between self-attention and convolutional layers. In: 8th International conference on learning representations, ICLR 2020, Addis Ababa, Ethiopia, 26–30 April 2020
Dai Z, Liu H, Le QV et al (2021) Coatnet: Marrying convolution and attention for all data sizes. In: Advances in neural information processing systems 34: annual conference on neural information processing systems 2021, NeurIPS 2021, 6-14 December 2021, virtual, pp 3965–3977
Devlin J, Chang M, Lee K et al (2019) BERT: pre-training of deep bidirectional transformers for language understanding. In: Proceedings of the 2019 Conference of the North American chapter of the association for computational linguistics: human language technologies, NAACL-HLT 2019, Minneapolis, MN, USA, June 2-7, 2019, Volume 1 (Long and Short Papers). Association for Computational Linguistics, pp 4171–4186
Di Piazza A, Di Piazza M, La Tona G et al (2021) An artificial neural network-based forecasting model of energy-related time series for electrical grid management. Math Comput Simul 184:294–305. ELECTRIMACS 2019 ENGINEERING - Modelling and computational simulation for analysis and optimisation in electrical power engineering
Graham B, El-Nouby A, Touvron H et al (2021) Levit: a vision transformer in convnet’s clothing for faster inference. In: 2021 IEEE/CVF International conference on computer vision, ICCV 2021, Montreal, QC, Canada, October 10-17, 2021. IEEE, pp 12239–12249
Guo S, Lin Y, Feng N et al (2019) Attention based spatial-temporal graph convolutional networks for traffic flow forecasting. In: Proceedings of the thirty-third aaai conference on artificial intelligence and thirty-first innovative applications of artificial intelligence conference and ninth AAAI symposium on educational advances in artificial intelligence. AAAI Press, AAAI’19/IAAI’19/EAAI’19
Haralick RM, Shanmugam K, Dinstein I (1973) Textural features for image classification. IEEE Trans Syst Man Cybern SMC-3(6):610–621
He H, Gao S, Jin T et al (2021) A seasonal-trend decomposition-based dendritic neuron model for financial time series prediction. Appl Soft Comput 108:107488
Himeur Y, Ghanem K, Alsalemi A et al (2021) Artificial intelligence based anomaly detection of energy consumption in buildings: a review, current trends and new perspectives. Appl Energy 287:116601
Kitaev N, Kaiser L, Levskaya A (2020) Reformer: the efficient transformer. In: 8th International conference on learning representations, ICLR 2020, Addis Ababa, Ethiopia, April 26–30, 2020
Li S, Jin X, Xuan Y et al (2019) Enhancing the locality and breaking the memory bottleneck of transformer on time series forecasting. In: Advances in neural information processing systems 32: Annual conference on neural information processing systems 2019, NeurIPS 2019, December 8-14, 2019, Vancouver, BC, Canada, pp 5244–5254
Lim B, Arık SÖ, Loeff N et al (2021) Temporal fusion transformers for interpretable multi-horizon time series forecasting. Int J Forecast 37(4):1748–1764
Liu M, Ren S, Ma S et al (2021a) Gated transformer networks for multivariate time series classification. CoRR abs/2103.14438. arXiv:2103.14438
Liu S, Yu H, Liao C et al (2022) Pyraformer: low-complexity pyramidal attention for long-range time series modeling and forecasting. In: The tenth international conference on learning representations, ICLR 2022, Virtual Event, April 25-29, 2022
Liu Z, Lin Y, Cao Y et al (2021b) Swin transformer: hierarchical vision transformer using shifted windows. In: 2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, October 10–17, 2021. IEEE, pp 9992–10002
Pan X, Ge C, Lu R et al (2022) On the integration of self-attention and convolution. In: IEEE/CVF Conference on computer vision and pattern recognition, CVPR 2022, New Orleans, LA, USA, June 18–24, 2022. IEEE, pp 805–815
Peng Z, Huang W, Gu S et al (2021) Conformer: Local features coupling global representations for visual recognition. In: 2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, October 10–17, 2021. IEEE, pp 357–366
Tuli S, Casale G, Jennings NR (2022) Tranad: Deep transformer networks for anomaly detection in multivariate time series data. Proc VLDB Endow 15(6):1201–1214
Vaswani A, Shazeer N, Parmar N et al (2017) Attention is all you need. In: Advances in neural information processing systems 30: annual conference on neural information processing systems 2017, December 4–9, 2017, Long Beach, CA, USA, pp 5998–6008
Vaswani A, Ramachandran P, Srinivas A et al (2021) Scaling local self-attention for parameter efficient visual backbones. In: IEEE Conference on computer vision and pattern recognition, CVPR 2021, virtual, June 19-25, 2021. Computer Vision Foundation / IEEE, pp 12894–12904
Wang H, Zhang R, Cheng X et al (2022) Hierarchical traffic flow prediction based on spatial-temporal graph convolutional network. IEEE Trans Intell Transp Syst 23(9):16137–16147
Wang X, Ma Y, Wang Y et al (2020) Traffic flow prediction via spatial temporal graph neural network. In: WWW ’20: The Web Conference 2020, Taipei, Taiwan, April 20–24, 2020. ACM / IW3C2, pp 1082–1092
Wu H, Xiao B, Codella N et al (2021a) Cvt: Introducing convolutions to vision transformers. In: 2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, October 10–17, 2021. IEEE, pp 22–31
Wu H, Xu J, Wang J et al (2021b) Autoformer: Decomposition transformers with auto-correlation for long-term series forecasting. In: Advances in neural information processing systems 34: annual conference on neural information processing systems 2021, NeurIPS 2021, December 6–14, 2021, virtual, pp 22419–22430
Yuan L, Chen Y, Wang T et al (2021) Tokens-to-token vit: Training vision transformers from scratch on imagenet. In: 2021 IEEE/CVF International conference on computer vision, ICCV 2021, Montreal, QC, Canada, October 10–17, 2021. IEEE, pp 538–547
Zeng W, Jin S, Liu W et al (2022) Not all tokens are equal: human-centric visual analysis via token clustering transformer. In: IEEE/CVF Conference on computer vision and pattern recognition, CVPR 2022, New Orleans, LA, USA, June 18–24, 2022. IEEE, pp 11091–11101
Zerveas G, Jayaraman S, Patel D et al (2021) A transformer-based framework for multivariate time series representation learning. In: KDD ’21: The 27th ACM SIGKDD conference on knowledge discovery and data mining, virtual event, Singapore, August 14–18, 2021. ACM, pp 2114–2124
Zhang D, Lou S (2021) The application research of neural network and bp algorithm in stock price pattern classification and prediction. Futur Gener Comput Syst 115:872–879
Zhou H, Zhang S, Peng J et al (2021) Informer: beyond efficient transformer for long sequence time-series forecasting. In: Thirty-Fifth AAAI conference on artificial intelligence, AAAI 2021, thirty-third conference on innovative applications of artificial intelligence, IAAI 2021, the eleventh symposium on educational advances in artificial intelligence, EAAI 2021, Virtual Event, February 2-9, 2021. AAAI Press, pp 11106–11115
Zhou T, Ma Z, Wen Q et al (2022) Fedformer: frequency enhanced decomposed transformer for long-term series forecasting. In: International conference on machine learning, ICML 2022, 17–23 July 2022, Baltimore, Maryland, USA, Proceedings of Machine Learning Research, vol 162. PMLR, pp 27268–27286
Author information
Authors and Affiliations
Contributions
All authors contributed to the study conception and design. Material preparation, data collection, experiments and analysis were performed by Yong Wang, Jianjian Peng, Xiaohu Wang, Zhicheng Zhang and Junting Duan. The first draft of the manuscript was written by Yong Wang, Jianjian Peng and Xiaohu Wang. All authors commented on previous versions of the manuscript. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethical and informed consent for data used
Not applicable.
Competing Interests
The authors have no competing interests to declare that are relevant to the content of this article.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix A Details of the models
Appendix A Details of the models
1.1 A.1 Autoformer
The details of Autoformer in the experiments are summarized in Table 10. Autoformer contains a 2-layer encoder and a 1-layer decoder. For the Auto-Correlation mechanism, let \(d = 64, h =8\) and add residual connections, a series decomposition layer (moving avg = 25), a position-wise feed-forward network layer (inner-layer dimension is 2048) and a dropout layer (\(p = 0.05\)) likewise. Note that the MHSA layers are replaced with depthwise separable convolutional layers in the first encoder layer and the decoder. For the depthwise separable convolutional layers, let the kernel size \(m = 5\).
1.2 A.2 Informer
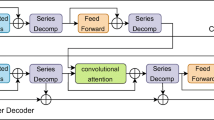
The schematic diagram of introducing convolution into Informer is shown in Fig. 11. The details of Informer in the experiments are summarized in Table 11. Informer contains a 2-layer encoder and a 1-layer decoder. For the ProbSparse self-attention mechanism, let \(d = 64, h = 8\) and add residual connections, a position-wise feed-forward network layer (inner-layer dimension is 2048) and a dropout layer (\(p = 0.05\)) likewise. Note that the MHSA layers are replaced with depthwise separable convolutional layers in the first encoder layer and the decoder. For the depthwise separable convolutional layers, let the kernel size \(m = 7\).

The schematic diagram of introducing convolution into Informer. The wheat color blocks denote the MHSA layers which are replaced by convolutional layers

The schematic diagram of introducing convolution into TranAD. The wheat color blocks denote the MHSA layers which are replaced by convolutional layers
1.3 A.3 TranAD
The schematic diagram of introducing convolution into TranAD is shown in Fig. 12. The details of TranAD in the experiments are summarized in Table 12. TranAD contains a 1-layer encoder, a 1-layer window encoder, and two 1-layer decoders. For the self-attention mechanism, let \(d = 2 \times feats, h = feats\) and add residual connections, a position-wise feed-forward network layer (inner-layer dimension is 16) and a dropout layer (\(p = 0.1\)) likewise, where feats denotes dimensions of data labels. Note that the MHSA layers are replaced with depthwise separable convolutional layers in the first window encoder layer and the encoder. For the depthwise separable convolutional layers, let the kernel size \(m = 5\). According to the training settings of TranAD, the model is trained with the AdamW optimizer to train the model with an initial learning rate of 0.01 (meta learning rate 0.02) and a step-scheduler with a step size of 0.5.
1.4 A.4 GTN
The schematic diagram of introducing convolution into GTN is shown in Fig. 13. The details of GTN in the experiments are summarized in Table 13. GTN contains an 8-layer encoder1 and a 8-layer encoder2. For the self-attention mechanism, let \(d = 64, h = 8\) and add residual connections, a position-wise feed-forward network layer (inner-layer dimension is 1024) and a dropout layer (\(p = 0.2\)) likewise. Note that the MHSA layers are replaced with depthwise separable convolutional layers in the encoder1 and encoder2. For the depthwise separable convolutional layers, let the kernel size \(m = 9\). According to the training settings of GTN, the model is trained with Adagrad with a learning rate of 0.0001.

The schematic diagram of introducing convolution into GTN. The wheat color blocks denote the MHSA layers which are replaced by convolutional layers
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Wang, Y., Peng, J., Wang, X. et al. Replacing self-attentions with convolutional layers in multivariate long sequence time-series forecasting. Appl Intell 54, 522–543 (2024). https://doi.org/10.1007/s10489-023-05205-z
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10489-023-05205-z