
Abstract
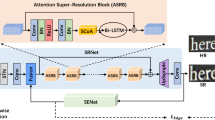
Scene text image super-resolution aims to upgrade the visual quality of low-resolution images and contributes to the accuracy of the subsequent scene text recognition task. However, advanced super-resolution methods with more attention to text-oriented information still have challenges in extremely blurred images. To address this problem, we propose a novel network based on textual reasoning and multiscale cross-convolution (TRMCC), in which a text structure preservation module is designed to explore the correlation of horizontal features among layers to enhance the structural similarity between the reconstructions and the corresponding high-resolution (HR) images and the multiscale cross-convolution block explores structural information hierarchically in layers with various perceptual fields in a progressive manner. In addition, based on human behavior in the presence of blurred images with linguistic rules, the text semantic reasoning module incorporated a self-attention mechanism and language-based textual reasoning to improve the accuracy of textual prior information. Comprehensive experiments conducted on the real-scene text image dataset TextZoom demonstrated the superiority of our model compared with existing state-of-the-art models, especially on structural similarity and information integrity.






Similar content being viewed by others


Data availability and access
The dataset as well as the source code generated during this study are available on request from the corresponding author Meng Qi.
References
Qiao Z, Zhou Y, Yang D et al. (2020) Seed: semantics enhanced encoder-decoder framework for scene text recognition. 2020 IEEE/CVF Conference on computer vision and pattern recognition (CVPR) pp 13525–13534. https://doi.org/10.1109/cvpr42600.2020.01354
Aberdam A, Litman R, Tsiper S et al. (2020) Sequence-to-sequence contrastive learning for text recognition. 2021 IEEE/CVF Conference on computer vision and pattern recognition (CVPR) pp 15297–15307. https://doi.org/10.1109/CVPR46437.2021.01505
Yue X, Kuang Z, Lin C et al (2020) Robustscanner: dynamically enhancing positional clues for robust text recognition. In: European conference on computer vision, https://doi.org/10.1007/978-3-030-58529-7_9
Wang Y, Xie H, Fang S et al (2022) Petr: rethinking the capability of transformer-based language model in scene text recognition. IEEE Trans Image Process 31:5585–5598. https://doi.org/10.1109/TIP.2022.3197981
Dong C, Loy CC, He K et al (2014) Image super-resolution using deep convolutional networks. IEEE Trans Patt Anal Mach Intell 38:295–307. https://doi.org/10.1109/TPAMI.2015.2439281
Chan KCK, Wang X, Xu X et al (2020) Glean: generative latent bank for large-factor image super-resolution. 2021 IEEE/CVF Conference on computer vision and pattern recognition (CVPR) pp 14240–14249. https://doi.org/10.1109/CVPR46437.2021.01402
Chen X, Wang X, Zhou J et al (2022) Activating more pixels in image super-resolution transformer. 2023 IEEE/CVF Conference on computer vision and pattern recognition (CVPR) pp 22367–22377. https://doi.org/10.1109/CVPR52729.2023.02142
Graves A, Schmidhuber J (2005) Framewise phoneme classification with bidirectional lstm and other neural network architectures. Neural Netw : Official J Int Neural Netw Soc 18(5–6):602–10. https://doi.org/10.1016/j.neunet.2005.06.042
Wang W, Xie E, Liu X et al (2020) Scene text image super-resolution in the wild. In: European conference on computer vision, https://doi.org/10.1007/978-3-030-58607-2_38
Ma J, Guo S, Zhang L (2021) Text prior guided scene text image super-resolution. IEEE Transactions on Image Processing 32:1341–1353. https://doi.org/10.1109/TIP.2023.3237002
Zhang Y, Tian Y, Kong Y et al (2018) Residual dense network for image super-resolution. 2018 IEEE/CVF Conference on computer vision and pattern recognition pp 2472–2481. https://doi.org/10.1109/CVPR.2018.00262
Niu B, Wen W, Ren W et al (2020) (2020) Correction to: single image super-resolution via a holistic attention network. Computer Vision - ECCV 12357:C1–C1. https://doi.org/10.1007/978-3-030-58610-2_12
Ledig C, Theis L, Huszár F et al (2016) Photo-realistic single image super-resolution using a generative adversarial network. 2017 IEEE Conference on computer vision and pattern recognition (CVPR) pp 105–114. https://doi.org/10.1109/CVPR.2017.19
Lim B, Son S, Kim H et al (2017) Enhanced deep residual networks for single image super-resolution. 2017 IEEE Conference on computer vision and pattern recognition workshops (CVPRW) pp 1132–1140. https://doi.org/10.1109/CVPRW.2017.151
Zhang Y, Li K, Li K et al (2018) Image super-resolution using very deep residual channel attention networks. In: European conference on computer vision, https://doi.org/10.1007/978-3-030-01234-2_18
Li X, Zuo W, Loy CC (2023) Learning generative structure prior for blind text image super-resolution. 2023 IEEE/CVF Conference on computer vision and pattern recognition (CVPR) pp 10103–10113. https://doi.org/10.1109/CVPR52729.2023.00974
Wang W, Xie E, Sun P et al (2020) Textsr: content-aware text super-resolution guided by recognition. In: European conference on computer vision, https://api.semanticscholar.org/CorpusID:202577634
Chen J, Yu H, Ma J et al (2021) Text gestalt: stroke-aware scene text image super-resolution. In: AAAI Conference on artificial intelligence, https://doi.org/10.1609/aaai.v36i1.19904
Mou Y, Tan L, Yang H et al (2020) Plugnet: degradation aware scene text recognition supervised by a pluggable super-resolution unit. In: European conference on computer vision, https://doi.org/10.1007/978-3-030-58555-6_10
Zhao C, Feng S, Zhao BN et al (2021) Scene text image super-resolution via parallelly contextual attention network. Proceedings of the 29th ACM international conference on multimedia https://doi.org/10.1145/3474085.3475469
Vaswani A, Shazeer NM, Parmar N et al (2017) Attention is all you need. In: NIPS, https://api.semanticscholar.org/CorpusID:13756489
Chen J, Li B, Xue X (2021) Scene text telescope: text-focused scene image super-resolution. 2021 IEEE/CVF Conference on computer vision and pattern recognition (CVPR) pp 12021–12030. https://doi.org/10.1109/CVPR46437.2021.01185
Shi W, Caballero J, Huszár F et al (2016) Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. 2016 IEEE Conference on computer vision and pattern recognition (CVPR) pp 1874–1883. https://doi.org/10.1109/CVPR.2016.207
Fang S, Xie H, Wang Y et al (2021) Read like humans: autonomous, bidirectional and iterative language modeling for scene text recognition. 2021 IEEE/CVF Conference on computer vision and pattern recognition (CVPR) pp 7094–7103. https://doi.org/10.1109/CVPR46437.2021.00702
Liutkus A, Cífka O, Wu SL et al (2021) Relative positional encoding for transformers with linear complexity. In: International conference on machine learning, https://api.semanticscholar.org/CorpusID:234762885
Liu Y, Jia Q, Fan X et al (2022) Cross-srn: structure-preserving super-resolution network with cross convolution. IEEE Trans Circuits Syst Video Technol 32:4927–4939. https://doi.org/10.1109/TCSVT.2021.3138431
Zhang XC, Chen Q, Ng R et al (2019) Zoom to learn, learn to zoom. 2019 IEEE/CVF Conference on computer vision and pattern recognition (CVPR) pp 3757–3765. https://doi.org/10.1109/CVPR.2019.00388
Shi B, Bai X, Yao C (2015) An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition. IEEE Trans Pattern Anal Mach Intell 39:2298–2304. https://doi.org/10.1109/TPAMI.2016.2646371
Luo C, Jin L, Sun Z (2019) A multi-object rectified attention network for scene text recognition. Pattern Recognit 90:109–118. https://doi.org/10.1016/j.patcog.2019.01.020
Shi B, Yang M, Wang X et al (2019) Aster: an attentional scene text recognizer with flexible rectification. IEEE Trans Pattern Anal Mach Intell 41:2035–2048. https://doi.org/10.1109/TPAMI.2018.2848939
Wang Z, Bovik AC, Sheikh HR et al (2004) Image quality assessment: from error visibility to structural similarity. IEEE Trans Image Process 13:600–612. https://doi.org/10.1109/TIP.2003.819861
Karatzas D, i Bigorda LG, Nicolaou A et al (2015) Icdar 2015 competition on robust reading. 2015 13th International conference on document analysis and recognition (ICDAR) pp 1156–1160. https://doi.org/10.1109/ICDAR.2015.7333942
Karatzas D, Shafait F, Uchida S et al (2013) Icdar 2013 robust reading competition. 2013 12th International conference on document analysis and recognition pp 1484–1493. https://doi.org/10.1109/ICDAR.2013.221
Wang K, Babenko B, Belongie SJ (2011) End-to-end scene text recognition. 2011 International conference on computer vision pp 1457–1464. https://doi.org/10.1109/ICCV.2011.6126402
Kingma DP, Ba J (2014) Adam: a method for stochastic optimization. https://api.semanticscholar.org/CorpusID:6628106. arXiv:1412.6980
Ma J, Liang Z, Zhang L (2022) A text attention network for spatial deformation robust scene text image super-resolution. 2022 IEEE/CVF Conference on computer vision and pattern recognition (CVPR) pp 5901–5910. https://doi.org/10.1109/CVPR52688.2022.00582
Author information
Authors and Affiliations
Contributions
Lan Yu data curation, conceptualization, design, implementation and writing. Xiaojie Li design, validation. Qi Yu visualization, software. Guangju Li validation, software. Dehu Jin visualization, validation. Meng Qi formal analysis, resources, writing-review and editing and supervision.
Corresponding authors
Ethics declarations
Competing interests
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Ethical and informed consent for data used
The data that support the findings of this study are openly available in TextZoom, ICDAR- 2015, ICDAR2013 and SVT datasets at https://drive.google.com/drive/folders/1WRVy-fC_KrembPkaI68uqQ9wyaptibMh?usp=sharing, https://github.com/zcswdt/OCR_ICDAR_label_revise, respectively.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Yu, L., Li, X., Yu, Q. et al. Scene text image super-resolution via textual reasoning and multiscale cross-convolution. Appl Intell 54, 1997–2008 (2024). https://doi.org/10.1007/s10489-023-05251-7
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10489-023-05251-7