
Abstract
Social media platforms like Twitter have been recognized as a reliable real-time information dissemination and collection medium, especially during disasters when traditional communication media fail. Information access improves situational awareness and is essential for successful disaster management. The response team primarily requires information about the people in danger and the need for and availability of resources, such as food, shelter, and medical supplies. These details can only be actionable with the location information. People’s tweets during disasters will be informal and not adhere to standard linguistic rules, causing traditional NLP methods to fail. This study focuses on location reference recognition, in which the system must identify any locations mentioned in tweets. Most existing solutions focus on rule-based systems and gazetteers, which depend on the completeness of the gazetteers and manually defined rules. Since people’s writing styles differ significantly, manually defining rules will be complex. This paper introduces a neural network architecture based on BiLSTM, CRF, and attention mechanisms. It exploits statistical linguistic properties also. Compared to state-of-the-art methods, the model demonstrated superior results in both in- and cross-domain scenarios on tweet datasets representing diverse disaster types from different regions and times. Empirical results demonstrate that supervised systems can replace gazetteer-based solutions. BiLSTM and CRF, in conjunction with attention mechanism, improve the sequential modelling in informal text. Our system excels in non-English tweets also. The observations have applications in location-based services like tracking news events, traffic management, and event localization.








Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Data Availability
\(\bullet \)The datasets [2, 15, 50] analysed during the current study are available from the corresponding authors on reasonable request. \(\bullet \) GeoCorpora, Harvey 2017 and IDRISI-RE are available online at the following URLs: https://github.com/rdeoliveira/geocorpora/https://github.com/geoai-lab/NeuroTPRhttps://github.com/rsuwaileh/IDRISI
Notes
References
Abdelkoui F, Kholladi MK (2017) Extracting criminal-related events from arabic tweets: A spatio-temporal approach. J Inf Technol Res (JITR) 10(3):34–47
Al-Olimat HS, Thirunarayan K, Shalin V et al (2018) Location name extraction from targeted text streams using gazetteer-based statistical language models. In: Proceedings of the 27th international conference on computational linguistics, pp 1986—1997
Allerton DJ (1987) The linguistic and sociolinguistic status of proper names what are they, and who do they belong to? J Pragmatics 11(1):61–92
Altinok D (2023) A diverse set of freely available linguistic resources for turkish. In: Proceedings of the 61st annual meeting of the association for computational linguistics (Volume 1: Long Papers), pp 13,739–13,750
Antariksa G, Muammar R, Lee J (2022) Performance evaluation of machine learning-based classification with rock-physics analysis of geological lithofacies in tarakan basin, indonesia. J Petroleum Sci Eng 208(109):250
Bahdanau D, Cho K, Bengio Y (2015) Neural machine translation by jointly learning to align and translate. In: Proceedings of the 3rd international conference on learning representations, ICLR 2015, San Diego, United States
Basu M, Shandilya A, Khosla P et al (2019) Extracting resource needs and availabilities from microblogs for aiding post-disaster relief operations. IEEE Trans Comput Social Syst 6(3):604–618
Briskilal J, Subalalitha C (2022) An ensemble model for classifying idioms and literal texts using bert and roberta. Inf Process & Manage 59(1):102,756
Chomsky N (2009) Syntactic structures. In: Syntactic Structures. De Gruyter Mouton
Daniluk M, Rocktäschel T, Welbl J et al (2017) Frustratingly short attention spans in neural language modeling. In: proceedings of the 5th international conference on learning representations (ICLR 2017)
Devlin J, Chang MW, Lee K et al (2019) Bert: Pre-training of deep bidirectional transformers for language understanding. In: proceedings of the 2019 conference of the north american chapter of the association for computational linguistics: human language technologies, Volume 1 (Long and Short Papers), pp 4171–4186
Dong L, Satpute MN, Wu W et al (2021) Two-phase multidocument summarization through content-attention-based subtopic detection. IEEE Trans Comput Social Syst 8(6):1379–1392
Dutt R, Hiware K, Ghosh A et al (2018) Savitr: A system for real-time location extraction from microblogs during emergencies. Companion proceedings of the the web conference 2018:1643–1649
FERNÁNDEZ NJ, Periñán-Pascual C (2021) nlore: A linguistically rich deep-learning system for locative-reference extraction in tweets. In: Intelligent environments 2021: workshop proceedings of the 17th international conference on intelligent environments, IOS Press, p 243
Fernández-Martínez NJ (2022) The fgloctweet corpus: An english tweet-based corpus for fine-grained location-detection tasks. Res Corpus Linguistics 10(1):117–133
Fernández-Martínez NJ, Periñán-Pascual C (2021) Lore: a model for the detection of fine-grained locative references in tweets. Onomázein 52:195–225
Fugate C (2011) Understanding the power of social media as a communication tool in the aftermath of disasters. Senate Committee on Homeland Security and Governmental Affairs, Subcommittee on Disaster Recovery and Intergovernmental Affairs
Gelernter J, Balaji S (2013) An algorithm for local geoparsing of microtext. GeoInformatica 17(4):635–667
Gelernter J, Zhang W (2013) Cross-lingual geo-parsing for non-structured data. In: Proceedings of the 7th workshop on geographic information retrieval, pp 64–71
Giridhar P, Abdelzaher T, George J et al (2015) On quality of event localization from social network feeds. In: 2015 IEEE International conference on pervasive computing and communication workshops (percom workshops), IEEE, pp 75–80
Goldfine E (2011) Best practices: The use of social media throughout emergency & disaster relief. Washington, DC: A Capstone Project submitted to Faculty of the Public Communication Graduate Program, School of Communication, American University 28
Guo Z, Zhu L, Han L (2021) Research on short text classification based on roberta-textrcnn. In: 2021 International conference on computer information science and artificial intelligence (CISAI), IEEE, pp 845–849
Gupta S, Nishu K (2020) Mapping local news coverage: Precise location extraction in textual news content using fine-tuned bert based language model. In: Proceedings of the fourth workshop on natural language processing and computational social science, pp 155–162
Hochreiter S, Schmidhuber J (1997) Long short-term memory. Neural Comput 9(8):1735–1780
Hochreiter S, Bengio Y, Frasconi P et al (2001) Gradient flow in recurrent nets: the difficulty of learning long-term dependencies
Hu X, Al-Olimat HS, Kersten J et al (2022) Gazpne: annotation-free deep learning for place name extraction from microblogs leveraging gazetteer and synthetic data by rules. Int J Geographical Inf Sci 36(2):310–337
Hu X, Zhou Z, Li H et al (2022) Location reference recognition from texts: A survey and comparison. ACM Computing Surveys
Hu X, Zhou Z, Sun Y et al (2022) Gazpne2: A general place name extractor for microblogs fusing gazetteers and pretrained transformer models. IEEE Int Things J 9(17):16,259–16,271
Huang B, Carley KM (2019) A large-scale empirical study of geotagging behavior on twitter. In: Proceedings of the 2019 IEEE/ACM international conference on advances in social networks analysis and mining, pp 365–373
Imran M, Castillo C, Diaz F et al (2015) Processing social media messages in mass emergency: A survey. ACM Comput Surveys (CSUR) 47(4):1–38
Inkpen D, Liu J, Farzindar A et al (2017) Location detection and disambiguation from twitter messages. J Intell Inf Syst 49:237–253
Jurgens D, Finethy T, McCorriston J et al (2015) Geolocation prediction in twitter using social networks: A critical analysis and review of current practice. In: Proceedings of the international AAAI conference on web and social media, pp 188–197
Kapoor KK, Tamilmani K, Rana NP et al (2018) Advances in social media research: Past, present and future. Inf Syst Front 20:531–558
Kolajo T, Daramola O, Adebiyi AA (2022) Real-time event detection in social media streams through semantic analysis of noisy terms. J Big Data 9(1):1–36
Korjus K, Hebart MN, Vicente R (2016) An efficient data partitioning to improve classification performance while keeping parameters interpretable. PloS one 11(8):e0161,788
Kumar A, Singh JP (2019) Location reference identification from tweets during emergencies: A deep learning approach. Int J Disaster Risk Reduction 33:365–375
Lafferty J (2001) Conditional random fields: Probabilistic models for segmenting and labelling sequence data. In: ICML, 2001
Lample G, Ballesteros M, Subramanian S et al (2016) Neural architectures for named entity recognition. In: Proceedings of the 2016 conference of the north american chapter of the association for computational linguistics: human language technologies, pp 260–270
Larochelle H, Hinton GE (2010) Learning to combine foveal glimpses with a third-order boltzmann machine. In: Advances in neural information processing systems 23
Levenshtein VI et al (1966) Binary codes capable of correcting deletions, insertions, and reversals. In: Soviet physics doklady, Soviet Union, pp 707–710
Li C, Sun A (2014) Fine-grained location extraction from tweets with temporal awareness. In: Proceedings of the 37th international ACM SIGIR conference on Research & development in information retrieval, pp 43–52
Li Y, Yang T (2018) Word embedding for understanding natural language: a survey. In: Guide to big data applications. Springer, p 83–104
Lingad J, Karimi S, Yin J (2013) Location extraction from disaster-related microblogs. In: Proceedings of the 22nd international conference on world wide web, pp 1017–1020
Liu Y, Ott M, Goyal N, et al (2019) Roberta: A robustly optimized bert pretraining approach. arXiv e-prints pp arXiv–1907
Malmasi S, Dras M (2015) Location mention detection in tweets and microblogs. In: Conference of the Pacific association for computational linguistics, Springer, pp 123–134
Martínez NJF, Periñán-Pascual C (2020) Knowledge-based rules for the extraction of complex, fine-grained locative references from tweets. RAEL: revista electrónica de lingüística aplicada 19(1):136–163
McCallum A, Li W (2003) Early results for named entity recognition with conditional random fields, feature induction and web-enhanced lexicons
Meiring B (1993) The syntax and semantics of geographical names. Hattingh et al Pretoria: Department of Geography: University of Pretoria
Mendes PN, Jakob M, García-Silva A, et al (2011) Dbpedia spotlight: shedding light on the web of documents. In: Proceedings of the 7th international conference on semantic systems, pp 1–8
Middleton SE, Kordopatis-Zilos G, Papadopoulos S et al (2018) Location extraction from social media: Geoparsing, location disambiguation, and geotagging. ACM Transactions on Information Systems (TOIS) 36(4):1–27
Obeid O, Zalmout N, Khalifa S et al (2020) Camel tools: An open source python toolkit for arabic natural language processing. In: Proceedings of the twelfth language resources and evaluation conference, pp 7022–7032
Pennington J, Socher R, Manning CD (2014) Glove: Global vectors for word representation. In: Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), pp 1532–1543
Qu S, Yang Y, Que Q (2021) Emotion classification for spanish with xlm-roberta and textcnn. In: IberLEF@ SEPLN, pp 94–100
Radford A, Narasimhan K, Salimans T et al (2018) Improving language understanding by generative pre-training (2018)
Saleem HM, Xu Y, Ruths D (2014) Novel situational information in mass emergencies: what does twitter provide? Procedia Eng 78:155–164
Sang EF, De Meulder F (2003) Introduction to the conll-2003 shared task: Language-independent named entity recognition. Proceedings of the seventh conference on natural language learning at HLT-NAACL 2003:142–147
Sankaranarayanan J, Samet H, Teitler BE et al (2009) Twitterstand: news in tweets. In: Proceedings of the 17th acm sigspatial international conference on advances in geographic information systems, pp 42–51
Shi M, Wang K, Li C (2019) A c-lstm with word embedding model for news text classification. In: 2019 IEEE/ACIS 18th International Conference on Computer and Information Science (ICIS), IEEE, pp 253–257
Sultanik EA, Fink C (2012) Rapid geotagging and disambiguation of social media text via an indexed gazetteer. In: ISCRAM
Suwaileh R, Elsayed T, Imran M, et al (2022) When a disaster happens, we are ready: Location mention recognition from crisis tweets. Int J Disaster Risk Reduction p 103107
Suwaileh R, Elsayed T, Imran M (2023) Idrisi-re: A generalizable dataset with benchmarks for location mention recognition on disaster tweets. Inf Process & Management 60(3):103,340
Unankard S, Li X, Sharaf MA (2015) Emerging event detection in social networks with location sensitivity. World Wide Web 18(5):1393–1417
Vaswani A, Shazeer N, Parmar N et al (2017) Attention is all you need. In: Advances in neural information processing systems 30
Vijayaraghavan P, Vosoughi S, Roy D (2016) Automatic detection and categorization of election-related tweets. In: Proceedings of the international AAAI conference on web and social media, pp 703–706
Wallgrün JO, Karimzadeh M, MacEachren AM et al (2018) Geocorpora: building a corpus to test and train microblog geoparsers. Int J Geographical Inf Sci 32(1):1–29
Wang J, Hu Y, Joseph K (2020) Neurotpr: A neuro-net toponym recognition model for extracting locations from social media messages. Trans GIS 24(3):719–735
Wiciaputra YK, Young JC, Rusli A (2021) Bilingual text classification in english and indonesian via transfer learning using xlm-roberta. Int J Adv Soft Computing & Its Appl 13(3)
Yamada I, Asai A, Shindo H et al (????) Luke: Deep contextualized entity representations with entity-aware self-attention. In: Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)
Zheng X, Wang B, Du X et al (2021) Mutual attention inception network for remote sensing visual question answering. IEEE Trans Geosci Remote Sens 60:1–14
Funding
This research received no external funding.
Author information
Authors and Affiliations
Contributions
All authors contributed to the conception and design of the proposed work. R.K established the system model and performed the experiments. All authors reviewed the results and approved the final version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare that they have no competing interests as defined by Springer, or other interests that might be perceived to influence the results and/or discussion reported in this paper.
Ethics approval
Not applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix
A Preliminaries
The fundamental concepts encompassing the major components of the proposed system are explained in this section. Word embedding, BiLSTM, CRF and attention mechanisms are used in our system.
1.1 A.1 Text preprocessing
As the text data is unstructured in nature, it needs to be cleaned up to improve the reliability and adaptability of text processing systems. Users’ social media posts (tweets) are typically colloquial and contain a lot of irrelevant information. Preprocessing is used to mitigate these issues. The following are the common text preprocessing methods.
-
Case conversion
-
Stemming and lemmatization
-
Removal of stopwords, URLs, punctuations, non-ASCII characters, extra spaces, etc.
-
Expanding the informal abbreviations with the original words

LSTM
1.2 A.2 Word embedding
Word embedding [42] is the most promising deep learning approach for word representation. The words are depicted as real-valued vectors. Semantically related words will have similar representations so that they will be placed closer in vector space.
1.2.1 A.2.1 RoBERTa model
Transformer-based pretrained language models like BERT (Bi-directional Encoder Representations from Transformers) [11] are breakthroughs in NLP. RoBERTa (Robustly Optimized BERT Pretraining Approach [44] is an improved variation of BERT. Compared to BERT, RoBERTa is pre-trained using larger batches and more data. RoBERTa outperformed BERT in [8, 22, 53, 67].
The proposed system applies RoBERTa-based word embedding. It generates contextual dynamic word vectors. Byte-pair encoding technique is used to process out-of-vocabulary words.
1.3 A.3 LSTM and BiLSTM
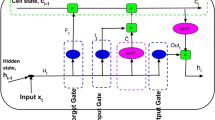
In sequential modelling, recurrent neural networks (RNNs) are demonstrated to be effective. However, RNNs suffers from long-term dependency issue [25]. Long short-term memory (LSTM) [24] is an improved variation of RNN. It solves problems of RNN in attaining long-term dependency in sequential modelling. It can retain information in the memory for a longer time. Both current input and previous output are processed to get the current output. Three gates, which are nonlinear - input gate, output gate, and forget gate - and a cell state are the major components of LSTM. This structure helps to regulate the flow of data from input to output.
Figure 9 depicts an LSTM architecture in detail.
The data progression through a single unit of LSTM is depicted in (19),(20), (21), (22), (23), (24) and (25), where,
\(x_t\), \(h_t\): input data and hidden state representation respectively at \(t^{th}\) time step
\(\hat{C_t}\): candidate cell state at \(t^{th}\) time step
\(C_t\): final cell state at \(t^{th}\) time step
\(F_t\), \(I_t\) and \(Out_t\): the data representation at the forget gate, the input gate and the output gate, respectively at time t
\(W_f\), \(W_i\), \(W_o\): the weight parameters of forget gate, input gate and output gate
\(b_f\), \(b_i\) and \(b_o\): the bias parameters of forget gate, input gate and output gate
\(\sigma \): sigmoid function
\(*\), \(+\): pointwise multiplication and addition
\(+\hspace{-5.52501pt}+\hspace{3.40001pt}\): concatenation operator
By forgetting the unwanted details, the forget gate retains the necessary information from previous states, the input gate captures the required data from the current input, and the output gate produces the current output.

BiLSTM

CRF
An LSTM processes the input only in one direction. However, a word’s semantics are influenced by both its left and right contexts. BiLSTM is a neural network which processes the input text in both directions. As a result, a feature vector with more contextual data is obtained. The BiLSTM architectural diagram is displayed in Fig. 10. It is composed of two LSTMs, one for each direction of data processing (left or right).
1.4 A.4 Conditional random field
We can consider location reference recognition as a sequence labelling task. Word embeddings are derived with a general natural language objective. As a result, it can be used for a wide range of tasks. Since these embeddings are not learned for a specific downstream task, there are chances of missing the most useful information for that task. Tasks like sentiment analysis, user review analysis, and fake news detection require the global semantics of a sentence, but sequence labelling tasks like POS tagging, and NER need neighboring word information.
In a sequence labelling task to determine the tag of a word, the most informative data are the tags of the very nearest words. Also, it needs a well-formed word embedding of the current word that embeds the general contextual information.
Conditional random field (CRF) was introduced by Lafferty (2001) [37]. It attained state-of-the-art performance for various sentence-level sequence labelling paradigms, including NER, POS tagging and chunking [47]. It is a discriminative model best suited for prediction problems where the state of the neighbours or contextual information influences the present prediction. Specifically, it performs sequence prediction by taking context into account. It models the inter-dependencies among neighboring word-level tags.
Figure 11 shows a symbolic representation of CRF with sequential tag interdependence.
RoBERTa word-embedding algorithm generates dynamic contextual embedding of natural language words. Hence, combining RoBERTa word embedding with CRF can generate a word-level representation giving more importance to neighboring words. We can utilize information from neighboring words to predict the current tag. It provides our system with a greater modelling capacity.
1.5 A.5 Attention mechanism
The concept underlying attention mechanism is the cognitive capacity to focus on certain parts of textual or visual data. This concept was originally applied to computer vision [39] by Larochelle and Hinton (2010). Later, Bahdanau et al. (2014) [6] implemented neural machine translation employing the attention technique. Afterwards, it was effectively used in various NLP systems, such as language modelling, information extraction, text classification, etc. [12, 69].
The attention mechanism enables the model to ignore irrelevant data and concentrate on the crucial parts. It prioritizes different input elements according to their importance. Different attention variants [6, 10, 63] have been implemented so far. The general idea in all the models is shown in Fig. 12.

Attention Model
\(x_1,x_2,...,x_t\) indicates the textual input elements. A compatibility score is computed between \(x_i\)s and a query vector q, for example, by calculating the dot product. The score shows the association between the input element and the query vector. This score is converted to a probability distribution, denoted as attention weight. The final context vector is generated by prioritizing the input elements based on their attention weight.
B Disaster datasets
Details of 17 publicly available disaster-specific datasets are given here. These datasets, which describe various catastrophic occurrences, cover a wide geographic range (the Us, UK, India, New Zealand, Kuwait, etc.) in different languages (English, Turkish, and Arabic).
-
The dataset collected and annotated by Al-Olimat et al. (2017) [2] consists of tweets posted by people during the Chennai Flood 2015, the Louisiana Flood 2016, and the Houston Flood 2016. It has a total of 4500 tweets. The Chennai, Louisiana and the Houston flood datasets have 2226, 1396 and 1701 location names, respectively.
-
The dataset collected and annotated by Middleton et al. (2018) [50] consists of tweets posted during Hurricane Sandy 2012, the Christchurch Earthquake 2012, Milan Blackout 2013 and Turkey Earthquake 2013. These datasets [2, 50] were annotated in the BILOU scheme by Suwaileh et al. (2022) [60]. “B”, “I”, and “L” indicate the beginning token, the inside token and the last token of a multiple-token location name. “U” indicates a single-token location name, and “O” indicates tokens other than location names. The datasets are annotated for a higher level of granularity, such as street names, bridges, cities, etc. Several location references have multiple tokens - for example, the tweet " Adyar River flowing at first floor height of the nearby houses. Stay safe" has two tokens to refer to one location, i.e., Adyar and river.
-
GeoCorpora [65]: It is a collection of tweets about various disasters. The authors gathered posts from Twitter that referenced natural disasters, infectious diseases, and riots by using keywords like "earthquake", "flu", "protest", "ebola", and others. The majority of the tweets are of events that happened in the United States (42%) and the United Kingdom(12%). Both fine-grained (street, river, mountain, etc.) and coarse-grained (country, state, country abbreviations, etc.) location references are given. GeoCorpora uses information from GeoNames to provide a comprehensive location description. GeoName identifier, corresponding toponym, country code, longitude and latitude are also given for each location reference token in the tweet text. This makes GeoCorpora suitable for geocoding models. Additionally, tweet metadata such as tweet_id, creation time, user location, etc., are given.
-
Fine-Grained LOCation Tweet Corpus (FGLOCTweets [15]): It is a set of disaster-specific English tweets collected by keywords such as ’earthquake’, ’fire’, etc. The tweets correspond to events that occurred in different locations across the world. It references geopolitical entities, natural landforms, POIs and traffic ways. Several fine-grained locations and complex location expressions (’1km SW of Lake Henshaw’, ’25min out of Melbourne’) are included in this dataset. Tweets are annotated using the BMESO scheme (Beginning-Medium-End-Single-Outside). ’S’ is for single token location reference, and ’O’ is for tokens other than location references.
-
Harvey 2017 [66]: It is a set of 1000 tweets collected during Hurricane Harvey 2017. It is annotated with a BIO (Beginning, Inside and Outside) scheme.
-
IDRISI-RE [61]: This publicly available location mention recognition dataset includes tweets in both English and Arabic. The datasets are annotated in the BILOU scheme. The tweets span 41 disaster events of various types (flood, earthquake, bombing, covid19, etc.) in 23 countries across different continents. We used the gold version (manually annotated) in our experiments. Three Arabic and four English sub-datasets were used to test the proposed system: Hurricane Dorian 2019 (English), Ecuador Earthquake 2016 (English), Midwestern US Floods 2019 (English), Canada Wild Fires 2016 (English), Beirut Explosion 2020 (Arabic), Cairo bombing 2019 (Arabic) and Kuwait Flood 2018 (Arabic). All datasets include location references that are fine- and coarse-grained and have multiple components.
C Detailed performance values of location recognition systems on various datasets
The model numbering used in the result tables (Tables 11, 12, 13 and 14) is as follows: M1-SpaCyNER, M2-Stanford Stanza, M3-DBPedia SpotLight, M4-Geoparsepy, M5-Lample et al., M6-Gupta and Nishu, M7-Kumar and Singh, M8-LUKE, M9-Neuro TPR, M10-LORE, M11-nLORE, M12-GazPNE2, M13 - GPT System and M14-Proposed System. Macro averaged results are provided.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Koshy, R., Elango, S. Applying social media in emergency response: an attention-based bidirectional deep learning system for location reference recognition in disaster tweets. Appl Intell 54, 5768–5793 (2024). https://doi.org/10.1007/s10489-024-05462-6
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10489-024-05462-6