
Abstract
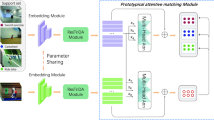
Few-shot action recognition aims to learn a model that can be easily adapted to identify novel action classifications using only a few labeled samples. Recent methods primarily focus on visual features and fail to fully utilize the available classification title of the video. In addition, they capture higher-order temporal relationships among video frames through averaging, which neglects the long-range dependencies information of the video. To address these issues, we designed a novel cross-modal guided spatio-temporal enrichment network (X-STEN) for few-shot action recognition. The model includes a cross-modal spatial enrichment module (X-SEM), a temporal enrichment module (TEM), and a non-parametric metrics module (NMM). Firstly, we extract and fuse multi-modal feature representations of videos. Then, we enhance the spatial context information of the video using the X-SEM and model the temporal context information of the video using the TEM. Finally, we generate the query and support prototypes and measure the similarity between them. Extensive experiments demonstrate that our X-STEN achieve excellent results on few-shot splits of Kinetics, HMDB51 and UCF101. Importantly, our method outperforms prior work on Kinetics by a wide margin (13.9%).







Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Data availability and access
The datasets generated during and/or analysed during the current study are available from the corresponding author on reasonable request.
References
Ahn D, Kim S, Ko BC (2023) Star++: Rethinking spatio-temporal cross attention transformer for video action recognition. Appl Intell 1–14
Feng F, Ming Y, Hu N, Zhou J (2023) See, move and hear: a local-to-global multi-modal interaction network for video action recognition. Appl Intell 1–20
Qin Y, Liu B (2023) Otde: optimal transport distribution enhancement for few-shot video recognition. Appl Intell 53(13):17115–17127
Qiu S, Fan T, Jiang J, Wang Z, Wang Y, Xu J, Sun T, Jiang N (2023) A novel two-level interactive action recognition model based on inertial data fusion. Inf Sci 633:264–279
Nasirihaghighi S, Ghamsarian N, Stefanics D, Schoeffmann K, Husslein H (2023) Action recognition in video recordings from gynecologic laparoscopy. In: 2023 IEEE 36th International symposium on computer-based medical systems (CBMS), pp 29–34
Abdelrazik MA, Zekry A, Mohamed WA (2023) Efficient hybrid algorithm for human action recognition. J Image Graph 11(1):72–81
Wu Z, Ma N, Wang C, Xu C, Xu G, Li M (2024) Spatial-temporal hypergraph based on dual-stage attention network for multi-view data lightweight action recognition. Pattern Recognit 151:110427
Arnab A, Dehghani M, Heigold G, Sun C, Lučić M, Schmid C (2021) Vivit: A video vision transformer. In: Proceedings of the IEEE/CVF International conference on computer vision, pp 6836–6846
Damen D, Doughty H, Farinella GM, Fidler S, Furnari A, Kazakos E, Moltisanti D, Munro J, Perrett T, Price W et al (2020) The epic-kitchens dataset: collection, challenges and baselines. IEEE Trans Pattern Anal Mach Intell 43(11):4125–4141
Coskun H, Zia MZ, Tekin B, Bogo F, Navab N, Tombari F, Sawhney HS (2021) Domain-specific priors and meta learning for few-shot first-person action recognition. IEEE Trans Pattern Anal Mach Intell 45(6):6659–6673
Xing J, Wang M, Liu Y, Mu B (2023) Revisiting the spatial and temporal modeling for few-shot action recognition. In: Proceedings of the AAAI conference on artificial intelligence, vol 37, pp 3001–3009
Wang X, Zhang S, Qing Z, Gao C, Zhang Y, Zhao D, Sang N (2023) Molo: Motion-augmented long-short contrastive learning for few-shot action recognition. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 18011–18021
Wang X, Zhang S, Cen J, Gao C, Zhang Y, Zhao D, Sang N (2023) Clip-guided prototype modulating for few-shot action recognition. Int J Comput Vis 1–14
Zhang H, Zhang L, Qi X, Li H, Torr PH, Koniusz P (2020) Few-shot action recognition with permutation-invariant attention. In: Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part V 16, pp 525–542
Cao K, Ji J, Cao Z, Chang C-Y, Niebles JC (2020) Few-shot video classification via temporal alignment. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 10618–10627
Thatipelli A, Narayan S, Khan S, Anwer RM, Khan FS, Ghanem B (2022) Spatio-temporal relation modeling for few-shot action recognition. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 19958–19967
Wang X, Ye W, Qi Z, Zhao X, Wang G, Shan Y, Wang H (2021) Semantic-guided relation propagation network for few-shot action recognition. In: Proceedings of the 29th ACM international conference on multimedia, pp 816–825
Lin C-C, Lin K, Wang L, Liu Z, Li L (2022) Cross-modal representation learning for zero-shot action recognition. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 19978–19988
Radford A, Kim JW, Hallacy C, Ramesh A, Goh G, Agarwal S, Sastry G, Askell A, Mishkin P, Clark J (2021) Learning transferable visual models from natural language supervision. In: International conference on machine learning, pp 8748–8763
Zhou K, Yang J, Loy CC, Liu Z (2022) Learning to prompt for vision-language models. Int J Comput Vis 130(9):2337–2348
Gao P, Geng S, Zhang R, Ma T, Fang R, Zhang Y, Li H, Qiao Y (2023) Clip-adapter: better vision-language models with feature adapters. Int J Comput Vis 1–15
Wang Z, Lu Y, Li Q, Tao X, Guo Y, Gong M, Liu T (2022) Cris: Clip-driven referring image segmentation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 11686–11695
Chao Y-W, Vijayanarasimhan S, Seybold B, Ross DA, Deng J, Sukthankar R (2018) Rethinking the faster r-cnn architecture for temporal action localization. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 1130–1139
Perrett T, Masullo A, Burghardt T, Mirmehdi M, Damen D (2021) Temporal-relational crosstransformers for few-shot action recognition. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 475–484
Haddad M, Ghassab VK, Najar F, Bouguila N (2021) A statistical framework for few-shot action recognition. Multimed Tools Appl 80:24303–24318
Liu T, Ma Y, Yang W, Ji W, Wang R, Jiang P (2022) Spatial-temporal interaction learning based two-stream network for action recognition, 606:864–876
Zong M, Wang R, Ma Y, Ji W (2023) Spatial and temporal saliency based four-stream network with multi-task learning for action recognition. Appl Soft Comput 132:109884
Berlin SJ, John M (2022) Spiking neural network based on joint entropy of optical flow features for human action recognition. Vis Comput 38(1):223–237
Liu Y, Yuan J, Tu Z (2022) Motion-driven visual tempo learning for video-based action recognition. IEEE Trans Image Process 31:4104–4116
Khobdeh SB, Yamaghani MR, Sareshkeh SK (2024) Basketball action recognition based on the combination of yolo and a deep fuzzy lstm network. J Supercomput 80(3):3528–3553
Cai J, Hu J, Tang X, Hung T-Y, Tan Y-P (2020) Deep historical long short-term memory network for action recognition. Neurocomputing 407:428–438
Qiu S, Fan T, Jiang J, Wang Z, Wang Y, Xu J, Sun T, Jiang N (2023) A novel two-level interactive action recognition model based on inertial data fusion. Inf Sci 633:264–279
Cao C, Lu Y, Zhang Y, Jiang D, Zhang Y (2023) Efficient spatiotemporal context modeling for action recognition. Neurocomputing 545:126289
Zhang G, Wen S, Li J, Che H (2023) Fast 3d-graph convolutional networks for skeleton-based action recognition. Appl Soft Comput 145:110575
Vrskova R, Kamencay P, Hudec R, Sykora P (2023) A new deep-learning method for human activity recognition. Sensors 23(5):2816
Li Y, Ji B, Shi X, Zhang J, Kang B, Wang L (2020) Tea: Temporal excitation and aggregation for action recognition. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 909–918
Liu Z, Luo D, Wang Y, Wang L, Tai Y, Wang C, Li J, Huang F, Lu T (2020) Teinet: Towards an efficient architecture for video recognition. In: Proceedings of the AAAI conference on artificial intelligence, vol 34, pp 11669–11676
Liu Z, Wang L, Wu W, Qian C, Lu T (2021) Tam: Temporal adaptive module for video recognition. In: Proceedings of the IEEE/CVF international conference on computer vision, pp 13708–13718
Wu G, Xu Y, Li J, Shi Z, Liu X (2023) Imperceptible adversarial attack with multi-granular spatio-temporal attention for video action recognition. IEEE Internet Things J
Zhou A, Ma Y, Ji W, Zong M, Yang P, Wu M, Liu M (2023) Multi-head attention-based two-stream efficientnet for action recognition. Multimed Syst 29(2):487–498
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, Kaiser Ł, Polosukhin I (2017) Attention is all you need. Adv Neural Inf Process Syst 30
Khan S, Naseer M, Hayat M, Zamir SW, Khan FS, Shah M (2022) Transformers in vision: a survey. ACM Comput Surv (CSUR) 54(10s):1–41
Zhao H, Chen Z, Guo L, Han Z (2022) Video captioning based on vision transformer and reinforcement learning. Peer J Comput Sci 8:916
Huang W, Deng Y, Hui S, Wu Y, Zhou S, Wang J (2024) Sparse self-attention transformer for image inpainting. Pattern Recognit 145:109897
Chang Z, Lu Y, Wang X, Ran X (2022) Mgnet: Mutual-guidance network for few-shot semantic segmentation. Eng Appl Artif Intell 116:105431
Chang Z, Lu Y, Ran X, Gao X, Wang X (2023) Few-shot semantic segmentation: a review on recent approaches. Neural Comput Appl 35(25):18251–18275
Kim C-L, Lee G-E, Choi Y-J, Kang J, Kim B-G (2024) Channel selective relation network for efficient few-shot facial expression recognition. In: 2024 IEEE International conference on consumer electronics (ICCE), pp 1–3
Bharadiya J (2023) A comprehensive survey of deep learning techniques natural language processing. Eur J Technol 7(1):58–66
Ran H, Li W, Li L, Tian S, Ning X, Tiwari P (2024) Learning optimal inter-class margin adaptively for few-shot class-incremental learning via neural collapse-based meta-learning. Inf Process Manage 61(3):103664
Tian S, Li L, Li W, Ran H, Ning X, Tiwari P (2024) A survey on few-shot class-incremental learning. Neural Netw 169:307–324
Chang Z, Lu Y, Ran X, Gao X, Zhao H (2023) Simple yet effective joint guidance learning for few-shot semantic segmentation. Appl Intell 53(22):26603–26621
Huang X, Choi SH (2023) Sapenet: Self-attention based prototype enhancement network for few-shot learning. Pattern Recognit 135:109170
Xing C, Rostamzadeh N, Oreshkin B, O Pinheiro PO (2019) Adaptive cross-modal few-shot learning. Adv Neural Inf Process Syst 32
Li Q, Xie X, Zhang J, Shi G (2023) Few-shot human-object interaction video recognition with transformers. Neural Netw 163:1–9
Elsken T, Staffler B, Metzen JH, Hutter F (2020) Meta-learning of neural architectures for few-shot learning. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 12365–12375
Lee Y, Choi S (2018) Gradient-based meta-learning with learned layerwise metric and subspace. In: International conference on machine learning, pp 2927–2936
Qin Y, Liu B (2023) Otde: optimal transport distribution enhancement for few-shot video recognition. Appl Intell 53(13):17115–17127
Yang F, Wang R, Chen X (2022) Sega: Semantic guided attention on visual prototype for few-shot learning. In: Proceedings of the IEEE/CVF winter conference on applications of computer vision, pp 1056–1066
Sung F, Yang Y, Zhang L, Xiang T, Torr PH, Hospedales TM (2018) Learning to compare: Relation network for few-shot learning. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 1199–1208
Ma R, Wu H, Wang X, Wang W, Ma Y, Zhao L (2024) Multi-view semantic enhancement model for few-shot knowledge graph completion. Expert Syst Appl 238:122086
Chen Z, Fu Y, Zhang Y, Jiang Y-G, Xue X, Sigal L (2019) Multi-level semantic feature augmentation for one-shot learning. IEEE Trans Image Process 28(9):4594–4605
Lu J, Li J, Yan Z, Mei F, Zhang C (2018) Attribute-based synthetic network (abs-net): Learning more from pseudo feature representations. Pattern Recognit 80:129–142
Zhu L, Yang Y (2018) Compound memory networks for few-shot video classification. In: Proceedings of the european conference on computer vision (ECCV), pp 751–766
Wang X, Lu Y, Yu W, Pang Y, Wang H (2024) Few-shot action recognition via multi-view representation learning. IEEE Trans Circuits Syst Video Technol
Wang X, Zhang S, Qing Z, Tang M, Zuo Z, Gao C, Jin R, Sang N (2022) Hybrid relation guided set matching for few-shot action recognition. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 19948–19957. https://doi.org/10.1109/CVPR52688.2022.01932
Wang X, Zhang S, Qing Z, Zuo Z, Gao C, Jin R, Sang N (2023) Hyrsm++: Hybrid relation guided temporal set matching for few-shot action recognition. Preprint at arXiv:2301.03330
Li C, Zhang J, Wu S, Jin X, Shan S (2023) Hierarchical compositional representations for few-shot action recognition. Preprint at arXiv:2208.09424
Zhang Y, Gong K, Zhang K, Li H, Qiao Y, Ouyang W, Yue X (2023) Meta-transformer: A unified framework for multimodal learning. Preprint at arXiv:2307.10802
Goyal R, Ebrahimi Kahou S, Michalski V, Materzynska J, Westphal S, Kim H, Haenel V, Fruend I, Yianilos P, Mueller-Freitag M (2017) The something something video database for learning and evaluating visual common sense. In: Proceedings of the IEEE international conference on computer vision, pp 5842–5850
Carreira J, Zisserman A (2017) Quo vadis, action recognition? a new model and the kinetics dataset. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 6299–6308
Soomro K, Zamir AR, Shah M (2012) Ucf101: A dataset of 101 human actions classes from videos in the wild. Preprint at arXiv:1212.0402
Kuehne H, Jhuang H, Garrote E, Poggio T, Serre T (2011) Hmdb: a large video database for human motion recognition. In: 2011 International conference on computer vision, pp 2556–2563
Zhu L, Yang Y (2020) Label independent memory for semi-supervised few-shot video classification. IEEE Trans Pattern Anal Mach Intell 44(1):273–285
Wu J, Zhang T, Zhang Z, Wu F, Zhang Y (2022) Motion-modulated temporal fragment alignment network for few-shot action recognition. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 9151–9160
He K, Zhang X, Ren S, Sun J (2016) Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 770–778. https://doi.org/10.1109/CVPR52688.2022.00894
Zheng S, Chen S, Jin Q (2022) Few-shot action recognition with hierarchical matching and contrastive learning. In: European conference on computer vision, pp 297–313
Li S, Liu H, Qian R, Li Y, See J, Fei M, Yu X, Lin W (2022) Ta2n: Two-stage action alignment network for few-shot action recognition. In: Proceedings of the AAAI conference on artificial intelligence, vol 36, pp 1404–1411
Liu H, Lin W, Chen T, Li Y, Li S, See J (2023) Few-shot action recognition via intra-and inter-video information maximization. Preprint at arXiv:2305.06114
Xing J, Wang M, Ruan Y, Chen B, Guo Y, Mu B, Dai G, Wang J, Liu Y (2023) Boosting few-shot action recognition with graph-guided hybrid matching. In: Proceedings of the IEEE/CVF international conference on computer vision, pp 1740–1750
Acknowledgements
This work was supported by the National Key Research and Development Program of China (No.2021ZD0111405), the Key Research and Development Program of Gansu Province (No.21YF5GA103, No.21YF5FA111), Lanzhou Science and Technology Planning Project (No.2021-1-183), Gansu Province Key Talent Project 2023, Lanzhou Talent Innovation and Entrepreneurship Project (No.2021-RC-91), and the Excellent Doctoral Student Program of Gansu Province (Grant No. 24JRRA487).
Author information
Authors and Affiliations
Contributions
Z. W. C. participated in the data acquisition, performed the model construction and the statistical analysis, and drafted the manuscript. Y. Y. participated in the study design and supervised all aspects of the study. L. L. participated in interpreting study findings and implications. M. L. drafted the figure and the manuscript. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Ethical and informed consent for data used
The authors declare that they have an informed consent to publish and for data used. This research is not napplicable for both human and/or animal.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Chen, Z., Yang, Y., Li, L. et al. Cross-modal guides spatio-temporal enrichment network for few-shot action recognition. Appl Intell 54, 11196–11211 (2024). https://doi.org/10.1007/s10489-024-05617-5
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10489-024-05617-5