
Abstract
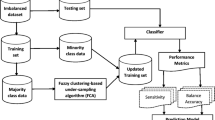
As one of the supervised learning techniques, classification plays a crucial role in categorizing and predicting the observations across a wide range of machine learning applications such as software defect detection, fraud detection in financial sector, fault and defect detection in manufacturing industry, medical diagnosis, etc. However, most classification algorithms have been developed with the assumption that the class distribution is balanced although unequal class distributions are quite common in many practical cases. When a class imbalance problem exists, in general, the classifier tends to become biased towards the majority class and thus the minority class instances are often misclassified to the majority class. Along with the class imbalance problem, the class overlap is also known as one of the sources that makes the learning task become difficult or sometimes deteriorates the classification performance, especially, when class imbalance problem also exists. Thus, in this research, we propose a cluster impurity-based hybrid resampling method including the partially balanced strategy to improve the classification performance of class imbalanced data with considering intra-cluster class imbalance and inter-cluster overlap problems. Specifically, several clustering methods are employed for identifying the groups (i.e., clusters) of all the instances and the cluster impurity of each instance is computed for measuring the degree of cluster overlap. Then, based on the cluster impurity, the instances are generated and eliminated recursively. To demonstrate the effectiveness of the proposed method, comprehensive experiments are conducted on forty imbalanced datasets and two non-parametric hypothesis tests are employed to show the statistical difference in classification performances between the proposed method and other traditional resampling methods.



Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Data availability
The datasets used during the training and testing are available from the public data repository https://sci2s.ugr.es/keel/imbalanced.php.
References
Vladimiro C, Zelaya G (2019) Towards explaining the effects of data preprocessing on machine learning. In: Proceedings of the 2019 IEEE 35th International Conference on Data Engineering (ICDE) 18739923. https://doi.org/10.1109/ICDE.2019.00245
Luque A, Carrasco A, Martín A et al (2019) The impact of class imbalance in classification performance metrics based on the binary confusion matrix. Pattern Recognit 91:216–231. https://doi.org/10.1016/j.patcog.2019.02.023
Thabtah F, Hammoud S, Kamalov F et al (2020) Data imbalance in classification: experimental evaluation. Inf Sci 513:429–441. https://doi.org/10.1016/j.ins.2019.11.004
Hud S, Liu K, Abdelrazek M et al (2018) An ensemble oversampling model for class imbalance problem in software defect prediction. IEEE Access 6:24184–24195. https://doi.org/10.1109/ACCESS.2018.2817572
Gong L, Jiang S, Wang R et al (2020) Empirical evaluation of the impact of class overlap on software defect prediction. In: Proceedings of the 2019 34th IEEE/ACM International Conference on Automated Software Engineering (ASE) 19265283. https://doi.org/10.1109/ASE.2019.00071
Liang P, Liu G, Xiong Z et al (2022) A fault detection model for edge computing security using imbalanced classification. J Syst Archit 133:102779. https://doi.org/10.1016/j.sysarc.2022.102779
Prati RC, Batista GEAPA, Monard MC (2004) Class imbalances versus class overlapping: an analysis of a learning system behavior. In: MICAI 2004: Adv Intell Syst Compu Lecture Notes in Computer Science 2972:312–321. https://doi.org/10.1007/978-3-540-24694-7_32
Spelmen VS, Porkodi R (2018) A review on handling imbalanced Data. In: Proceedings of the 2018 International Conference on Current Trends towards Converging Technologies (ICCTCT) 18290605. https://doi.org/10.1109/ICCTCT.2018.8551020
Denil M, Trappenberg T (2010) Overlap versus imbalance. In: Advances in Artificial Intelligence Canadian AI 2010 Lecture Notes in Computer Science 6085:220–231
Vuttipittayamongkol P, Elyan E, Petrovski AV (2021) On the class overlap problem in imbalanced data classification. Knowl-Based Syst 212:106631
Santos MS, Abreu PH, Japkowicz N et al (2022) On the joint-effect of class imbalance and overlap: a critical review. Artif Intell Rev 55:6207–6275
Barua S, Islam MM, Yao X et al (2014) MWMOTE-majority weighted minority oversampling technique for imbalanced data set learning. IEEE Trans Knowl Data Eng 26:405–425. https://doi.org/10.1109/TKDE.2012.232
Nekooeimehr I, Lai-Yuen SK (2016) Adaptive semi-unsupervised weighted oversampling (A-SUWO) for imbalanced datasets. Expert Syst Appl 46:405–416. https://doi.org/10.1016/j.eswa.2015.10.031
Douzas G, Bacao F (2017) Self-Organizing Map Oversampling (SOMO) for imbalanced data set learning. Expert Syst Appl 82:40–52. https://doi.org/10.1016/j.eswa.2017.03.073
Lin WC, Tsai CF, Hu YH et al (2017) Clustering-based undersampling in class-imbalanced data. Inf Sci 409–410:17–26. https://doi.org/10.1016/j.ins.2017.05.008
Douzas G, Bacao F, Last F (2018) Improving imbalanced learning through a heuristic oversampling method based on k-means and SMOTE. Inf Sci 465:1–20. https://doi.org/10.1016/j.ins.2018.06.056
Wei J, Huang H, Yao L et al (2020) NI-MWMOTE: An improving noise-immunity majority weighted minority oversampling technique for imbalanced classification problems. Expert Syst Appl 158:113504
Hautamäki V, Cherednichenko S, Kärkkäinen I et al (2005) Improving k-means by outlier removal. Proc Scand Conf Image Anal 3540:978–987. https://doi.org/10.1007/11499145_99
Baadel S, Thabtah F, Lu J (2016) Overlapping clustering: a review. In: 2016 SAI Computing Conference (SAI), pp 233–237
Vorraboot P, Rasmequan S, Chinnasarn K et al (2015) Improving classification rate constrained to imbalanced data between overlapped and non-overlapped regions by hybrid algorithms. Neurocomputing 152:429–443. https://doi.org/10.1016/j.neucom.2014.10.007
Ofek N, Rokach L, Stern R et al (2017) Fast-CBUS: A fast clustering-based undersampling method for addressing the class imbalance problem. Neurocomputing 243:88–102. https://doi.org/10.1016/j.neucom.2017.03.011
Cervantes J, Garcia-Lamont F, Rodriguez L et al (2017) PSO-based method for SVM classification on skewed data sets. Neurocomputing 228:187–197. https://doi.org/10.1016/j.neucom.2016.10.041
Koziarski M, Woźniak M, Krawczyk B (2020) Combined Cleaning and Resampling algorithm for multi-class imbalanced data with label noise. Knowl-Based Syst 204:106223. https://doi.org/10.1016/j.knosys.2020.106223
Vuttipittayamongkol P, Elyan E (2020) Neighbourhood-based undersampling approach for handling imbalanced and overlapped data. Inf Sci 509:47–70. https://doi.org/10.1016/j.ins.2019.08.062
Xu Z, Shen D, Nie T et al (2021) A cluster-based oversampling algorithm combining SMOTE and k-means for imbalanced medical data. Inf Sci 572:574–589
Soltanzadeh P, Hashemzadeh M (2021) RCSMOTE: Range-Controlled synthetic minority over-sampling technique for handling the class imbalance problem. Inf Sci 542:92–111. https://doi.org/10.1016/j.ins.2020.07.014
Xie X, Liu H, Zeng S et al (2021) A novel progressively undersampling method based on the density peaks sequence for imbalanced data. Knowl-Based Syst 213:106689. https://doi.org/10.1016/j.knosys.2020.106689
Ma CK, Park YJ (2021) A new instance density-based synthetic minority oversampling method for imbalanced classification problems. Eng Optim 54:1743–1757. https://doi.org/10.1080/0305215X.2021.1982929
Mayabadi S, Saadatfar H (2022) Two density-based sampling approaches for imbalanced and overlapping data. Knowl-Based Syst 241:108217. https://doi.org/10.1016/j.knosys.2022.108217
Yan Y, Jiang Y, Zheng Z et al (2022) LDAS: Local density-based adaptive sampling for imbalanced data classification. Expert Syst Appl 191:116213. https://doi.org/10.1016/j.eswa.2021.116213
Sun A, Lim EP, Liu Y (2009) On strategies for imbalanced text classification using SVM: a comparative study. Decis Support Syst 48:191–201. https://doi.org/10.1016/j.dss.2009.07.011
Tang Y, Zhang YQ, Chawla NV et al (2009) SVMs modeling for highly imbalanced classification. IEEE Trans Syst Man Cybern B 39:281–288. https://doi.org/10.1109/TSMCB.2008.2002909
Tian J, Gu H, Liu W (2011) Imbalanced classification using support vector machine ensemble. Neural Comput Appl 20:203–209. https://doi.org/10.1007/s00521-010-0349-9
Kang Q, Shi L, Zhou MC et al (2018) A distance-based weighted undersampling scheme for support vector machines and its application to imbalanced classification. IEEE Trans Neur Netw Lear 29:18042986. https://doi.org/10.1109/TNNLS.2017.2755595
Wang Q, Tian Y, Liu D (2019) Adaptive FH-SVM for imbalanced classification. IEEE Access 7:19001876. https://doi.org/10.1109/ACCESS.2019.2940983
Song Y, Peng Y (2019) A MCDM-based evaluation approach for imbalanced classification methods in financial risk prediction. IEEE Access 7:18789126. https://doi.org/10.1109/ACCESS.2019.2924923
Shu T, Zhang B, Tang YY (2020) Sparse supervised representation-based classifier for uncontrolled and imbalanced classification. IEEE Trans Neur Netw Learn 31:20068464. https://doi.org/10.1109/TNNLS.2018.2884444
Sanz J, Sesma-Sara M, Bustince H (2021) A fuzzy association rule-based classifier for imbalanced classification problems. Inf Sci 577:265–279. https://doi.org/10.1016/j.ins.2021.07.019
Sun Y, Kamel MS, Wong AKC et al (2007) Cost-sensitive boosting for classification of imbalanced data. Pattern Recognit 40:3358–3378. https://doi.org/10.1016/j.patcog.2007.04.009
Seiffert C, Khoshgoftaar TM, Hulse JV et al (2010) RUSBoost: a hybrid approach to alleviating class imbalance. IEEE Trans Syst Man Cybern A 40(1):185–197. https://doi.org/10.1109/TSMCA.2009.2029559
Hanifah FS, Wijayanto H, Kurnia A (2015) SMOTE bagging algorithm for imbalanced dataset in logistic regression analysis. Appl Math Sci 9:6857–6865. https://doi.org/10.12988/ams.2015.58562
Li Y, Guo H, Liu X et al (2016) Adapted ensemble classification algorithm based on multiple classifier system and feature selection for classifying multi-class imbalanced data. Knowl-Based Syst 94:88–104. https://doi.org/10.1016/j.knosys.2015.11.013
Kirshners A, Parshutin S, Gorskis H (2017) Entropy-based classifier enhancement to handle imbalanced class problem. Procedia Comput Sci 104:586–591. https://doi.org/10.1016/j.procs.2017.01.176
Tanha J, Abdi Y, Samadi N et al (2020) Boosting methods for multi-class imbalanced data classification: an experimental review. J Big Data 7:70. https://doi.org/10.1186/s40537-020-00349-y
Zhao J, Jin J, Chen S et al (2020) A weighted hybrid ensemble method for classifying imbalanced data. Knowl-Based Syst 203:106087. https://doi.org/10.1016/j.knosys.2020.106087
Jimenez-Castaño CA, Alvarez-Meza AM, Orozco-Gutierrez AA (2020) Enhanced automatic twin support vector machine for imbalanced data classification. Pattern Recognit 107:107442. https://doi.org/10.1016/j.patcog.2020.107442
Shi P, Wang Z (2021) An Ensemble Tree Classifier for Highly Imbalanced Data Classification. J Syst Sci Complex 34:2250–2266
Chawla NV, Bowyer KW, Hall LO et al (2002) SMOTE: synthetic minority over-sampling technique. J Artif Intell Res 16:321–357. https://doi.org/10.1613/jair.953
Han H, Wang WY, Mao BH (2005) Borderline-SMOTE: A new over-sampling method in imbalanced data sets learning. In: Advances in Intelligent Computing. ICIC 2005 Lecture Notes in Computer Science 3644:878887
He H, Bai Y, Garcia EA et al (2008) ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In: Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), pp 1322–1328. https://doi.org/10.1109/IJCNN.2008.4633969
Bunkhumpornpat C, Sinapiromsaran K, Lursinsap C (2009) Safe-Level-SMOTE: Safe-level-synthetic minority over-sampling technique for handling the class imbalanced problem. In: Advances in Knowledge Discovery and Data Mining. PAKDD 2009 Lecture Notes in Computer Science 5476:475–482
Rivera WA (2017) Noise reduction a priori synthetic over-sampling for class imbalanced data sets. Inf Sci 408:146–161
Chen Q, Zhang ZL, Huang WP et al (2022) PF-SMOTE: A novel parameter-free SMOTE for imbalanced datasets. Neurocomputing 498:75–88
Funding
This work has been supported by the General Research Program funded by the Ministry of Science and Technology, Taiwan, (Grant No. MOST 110-2221-E-027-106-MY3).
Author information
Authors and Affiliations
Contributions
The concept and design of the study were developed by You-Jin Park. Material preparation, data collection and analysis were performed by Ke-Yong Cheng. The first draft of the manuscript was written by You-Jin Park and Ke-Yong Cheng, and all authors commented on previous versions of the manuscript. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethical approval and informed consent
The datasets used and analyzed during the current study are available from the public data repository.
Competing interests
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Park, YJ., Cheng, KY. A cluster impurity-based hybrid resampling for imbalanced classification problems. Appl Intell 54, 9671–9684 (2024). https://doi.org/10.1007/s10489-024-05644-2
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10489-024-05644-2