
Abstract
In many applications with great potential, safety is critical as it needs to meet strict safety specifications within physical constraints. This paper studies the decentralized event-triggered control problem of a class of partially unknown nonlinear interconnected systems with state constraints under the reinforcement learning approach. First, by introducing a control barrier function into the performance function of each auxiliary subsystem with state constraints, the system state can be operated within a user-defined safe set. And then, the original control problem can be translated equivalently into finding or searching optimal event-triggered control policies that combine to form the desired decentralized controller, resulting in significant savings in communication resources. Compared with the traditional actor-critic network structure approach, the proposed identifier-critic network structure can loosen the constraints on the system dynamics and eliminate the errors arising from approximating the actor network. Updating the weight vectors in the critic network by gradient descent and concurrent learning techniques removes the need for the traditional persistence of excitation conditions. Furthermore, it is rigorously proved that all the signals of the interconnected nonlinear system are bound according to the Lyapunov stability theory. Last, the effectiveness of the proposed control scheme is verified by simulation examples.





















Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Data Availability
The authors can confirm that all relevant data are included in the article.
References
Wang S, Shang M, Levin MW, Stern R (2023) A general approach to smoothing nonlinear mixed traffic via control of autonomous vehicles. Transp Res C Emerg Technol 146:103967
Shao X, Ye D (2022) Event-based adaptive fuzzy fixed-time control for nonlinear interconnected systems with non-affine nonlinear faults. Fuzzy Sets Syst 432:1–27
Yu L, Wang R (2022) Researches on adaptive cruise control system: A state of the art review. Proc IME D J Automob Eng 236(2–3):211–240
Ames AD, Xu X, Grizzle JW, Tabuada P (2016) Control barrier function based quadratic programs for safety critical systems. IEEE Trans Autom Control 62(8):3861–3876
Zhao Y, He Y, Feng Z, Shi P, Du X (2018) Relaxed sum-of-squares based stabilization conditions for polynomial fuzzy-model-based control systems. IEEE Trans Fuzzy Syst 27(9):1767–1778
He Y, Chang X-H, Wang H, Zhao X (2023) Command-filtered adaptive fuzzy control for switched mimo nonlinear systems with unknown dead zones and full state constraints. Int J Fuzzy Syst 25(2):544–560
Marvi Z, Kiumarsi B (2021) Safe reinforcement learning: A control barrier function optimization approach. Int J Robust Nonlinear Control 31(6):1923–1940
Qin C, Zhang Z, Shang Z, Zhang J, Zhang D (2023) Adaptive optimal safety tracking control for multiplayer mixed zero-sum games of continuous-time systems. Appl Intell 1–16
Xu J, Wang J, Rao J, Zhong Y, Wang H (2022) Adaptive dynamic programming for optimal control of discrete-time nonlinear system with state constraints based on control barrier function. Int J Robust Nonlinear Control 32(6):3408–3424
Tang F, Niu B, Zong G, Zhao X, Xu N (2022) Periodic event-triggered adaptive tracking control design for nonlinear discrete-time systems via reinforcement learning. Neural Netw 154:43–55
Roman R-C, Precup R-E, Hedrea E-L, Preitl S, Zamfirache IA, Bojan-Dragos C-A, Petriu EM (2022) Iterative feedback tuning algorithm for tower crane systems. Procedia Comput Sci 199:157–165
Zamfirache IA, Precup R-E, Petriu EM (2024) Adaptive reinforcement learning-based control using proximal policy optimization and slime mould algorithm with experimental tower crane system validation. Appl Soft Comput 160:111687
Yao D, Li H, Shi Y (2022) Adaptive event-triggered sliding-mode control for consensus tracking of nonlinear multiagent systems with unknown perturbations. IEEE Trans Cybern 53(4):2672–2684
Huang F, Xu J, Yin L, Wu D, Cui Y, Yan Z, Chen T (2022) A general motion control architecture for an autonomous underwater vehicle with actuator faults and unknown disturbances through deep reinforcement learning. Ocean Eng 263:112424
Elhaki O, Shojaei K (2022) Output-feedback robust saturated actor-critic multi-layer neural network controller for multi-body electrically driven tractors with n-trailer guaranteeing prescribed output constraints. Robot Auton Syst 154:104106
Dou L, Cai S, Zhang X, Su X, Zhang R (2022) Event-triggered-based adaptive dynamic programming for distributed formation control of multi-uav. J Frankl Inst 359(8):3671–3691
Wang X, Li Y, Quan Z, Wu J (2023) Optimal trajectory-tracking guidance for reusable launch vehicle based on adaptive dynamic programming. Eng Appl Artif Intell 117:105497
Precup R-E, Roman R-C, Safaei A (2021) Data-driven Model-free Controllers. CRC Press, Boca Raton, FL
Yang X, Liu D, Huang Y (2013) Neural-network-based online optimal control for uncertain non-linear continuous-time systems with control constraints. IET Control Theory Appl 7(17):2037–2047
Bakule L (2008) Decentralized control: An overview. Annu Rev Control 32(1):87–98
Wang H, Liu X, Liu K (2015) Robust adaptive neural tracking control for a class of stochastic nonlinear interconnected systems. IEEE Trans Neural Netw Learn Syst 27(3):510–523
Zhao Y, Zhang H, Chen Z, Wang H, Zhao X (2022) Adaptive neural decentralised control for switched interconnected nonlinear systems with backlash-like hysteresis and output constraints. Int J Syst Sci 53(7):1545–1561
Sun J, Liu C (2019) Decentralised zero-sum differential game for a class of large-scale interconnected systems via adaptive dynamic programming. Int J Control 92(12):2917–2927
Aggarwal RK, Dave M (2012) Filterbank optimization for robust asr using ga and pso. Int J Speech Technol 15:191–201
Saberi A (1988) On optimality of decentralized control for a class of nonlinear interconnected systems. Automatica 24(1):101–104
Wang T, Wang H, Xu N, Zhang L, Alharbi KH (2023) Sliding-mode surface-based decentralized event-triggered control of partially unknown interconnected nonlinear systems via reinforcement learning. Inf Sci 641:119070
Chen Y (2022) Interconnected backlash inverse compensation in neural decentralized control for switched nonlinear systems. Appl Intell 52(9):10135–10147
Tang F, Wang H, Chang X-H, Zhang L, Alharbi KH (2023) Dynamic event-triggered control for discrete-time nonlinear markov jump systems using policy iteration-based adaptive dynamic programming. Nonlinear Anal Hybrid Syst 49:101338
Shi Z, Zhou C (2022) Distributed optimal consensus control for nonlinear multi-agent systems with input saturation based on event-triggered adaptive dynamic programming method. Int J Control 95(2):282–294
Xu L-X, Wang Y-L, Wang X, Peng C (2022) Decentralized event-triggered adaptive control for interconnected nonlinear systems with actuator failures. IEEE Trans Fuzzy Syst 31(1):148–159
Hentout A, Maoudj A, Kouider A (2024) Shortest path planning and efficient fuzzy logic control of mobile robots in indoor static and dynamic environments. Sci Technol 27(1):21–36
Liu K, Ji Z (2022) Dynamic event-triggered consensus of general linear multi-agent systems with adaptive strategy. IEEE Trans Circ Syst II Express Briefs 69(8):3440–3444
Huo Y, Wang D, Qiao J (2022) Adaptive critic optimization to decentralized event-triggered control of continuous-time nonlinear interconnected systems. Optim Control Appl Methods 43(1):198–212
Tan LN, Tran H-T, Tran T-T (2022) Event-triggered observers and distributed \(h_{\infty }\) control of physically interconnected nonholonomic mechanical agents in harsh conditions. IEEE Trans Syst Man Cybern Syst 52(12):7871–7884
Yang X, He H (2019) Decentralized event-triggered control for a class of nonlinear-interconnected systems using reinforcement learning. IEEE Trans Cybern 51(2):635–648
Zhao Y, Wang H, Xu N, Zong G, Zhao X (2023) Reinforcement learning-based decentralized fault tolerant control for constrained interconnected nonlinear systems. Chaos, Solitons Fractals 167:113034
Qin C, Wang J, Zhu H, Zhang J, Hu S, Zhang D (2022) Neural network-based safe optimal robust control for affine nonlinear systems with unmatched disturbances. Neurocomputing 506:228–239
Yang X, He H (2019) Adaptive critic learning and experience replay for decentralized event-triggered control of nonlinear interconnected systems. IEEE Trans Syst Man Cybern Syst 50(11):4043–4055
Xue S, Luo B, Liu D, Yang Y (2020) Constrained event-triggered \(h_{\infty }\) control based on adaptive dynamic programming with concurrent learning. IEEE Trans Syst Man Cybern Syst 52(1):357–369
Xu J, Wang J, Rao J, Zhong Y, Wang H (2022) Adaptive dynamic programming for optimal control of discrete-time nonlinear system with state constraints based on control barrier function. Int J Robust Nonlinear Control 32(6):3408–3424
Huo X, Karimi HR, Zhao X, Wang B, Zong G (2021) Adaptive-critic design for decentralized event-triggered control of constrained nonlinear interconnected systems within an identifier-critic framework. IEEE Trans Cybern 52(8):7478–7491
Acknowledgements
This work was supported by science and technology research project of the Henan province (222102240014).
Author information
Authors and Affiliations
Contributions
C.Q. and D.Z. provided methodology, validation, and writing—original draft preparation; Y.W. and T.Z. provided conceptualization and writing—review; J.K. provided supervision; C.Q. provided funding support. All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Ethical and informed consent for data used
This study did not involve ethical approval.
Conflicts of Interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
A Appendix A
A Appendix A
A Proof of Exclusion of Zeno Behavior
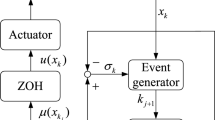
According to the (19), the event-triggered error \(\mathcal {Z} _{a,k}(t)\) has the derivative with respect to t as
By utilizing the optimal DETC policy and the optimal event-triggered auxiliary control provided by (54) and (55), we obtain
Note that the function \(f_{a}(x_{a})\) is locally Lipschitz continuous. That is, there exists a non-negative constant \(K_{f,a}\) such that \(\left\| f_{a}(x_{a}) \right\| \le K_{f,a}\left\| x_{a} \right\| \) holds. In addition, under Assumptions 2 and 7, we have
where \(\mathfrak {D}_{a}=\frac{1}{2R_{a}}d^{2}_{g_{a}}d_{\sigma _{a}}\left\| \hat{W} _{a} \right\| + \frac{1}{2\xi _{a}}d^{2}_{\eta _{a}}d_{\sigma _{a}}\left\| \hat{W} _{a} \right\| \). According to [27,28], we can obtain the inequality related to (a3), i.e.
Thus, the kth sampling period can be denoted as
where \(\mathfrak {D}_{m_{a}}=\frac{K_{f,a}\left\| \tilde{x}_{a,k}) \right\| +\mathfrak {D}_{a}}{K_{f,a}}\). From the above discussion, we can find the minimum sampling period \(\left( \triangle t_{k} \right) _{min}>0,\;k\in \mathbb {N}\). Thus, Zeno behavior will not happen.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Qin, C., Wu, Y., Zhu, T. et al. Reinforcement-learning-based decentralized event-triggered control of partially unknown nonlinear interconnected systems with state constraints. Appl Intell 55, 164 (2025). https://doi.org/10.1007/s10489-024-06072-y
Accepted:
Published:
DOI: https://doi.org/10.1007/s10489-024-06072-y