
Abstract
Multimodal sentiment analysis (MSA) aims to discern the emotional information expressed by users in the multimodal data they upload on various social media platforms. In most previous studies, these modalities (audio A, visual V, and text T) were typically treated equally, overlooking the lower representation quality inherent in audio and visual modalities. This oversight often results in inaccurate interaction information when audio or visual modalities are used as the primary input, thereby negatively impacting the model’s sentiment predictions. In this paper, we propose a text-dominant multimodal perception network with cross-modal transformer-based semantic enhancement. The network comprises primarily a text-dominant multimodal perception (TDMP) module and a cross-modal transformer-based semantic enhancement (TSE) module. TDMP leverages the text modality to dominate intermodal interactions, extracting high correlation and differentiation features from each modality, thereby obtaining more accurate representations for each modality. The TSE module uses a transformer architecture to convert the audio and visual modality features into text features. By applying KL divergence constraints, it ensures that the translated modality representations capture as much emotional information as possible while maintaining high similarity to the original text modality representations. This enhances the original text modality semantics while mitigating the negative impact of the input. Extensive experiments on the CMU-MOSI and CMU-MOSEI datasets demonstrate the effectiveness of our proposed model.
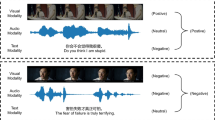
Graphical abstract
The overview of Text-dominant Multimodal Perception Network








Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Data availability and access
The data will be made available upon reasonable request.
References
Zhu L, Zhu Z, Zhang C, Xu Y, Kong X (2023) Multimodal sentiment analysis based on fusion methods: A survey. Inf Fusion 95:306–325. https://doi.org/10.1016/j.inffus.2023.02.028
Liu Z, Yang T, Chen W, Chen J, Li Q, Zhang J (2024) Sentiment analysis of social media comments based on multimodal attention fusion network. Appl Soft Comput 164:112011. https://doi.org/10.1016/j.asoc.2024.112011
Aruna AG, Vetriselvi V (2024) Sentiment analysis on a low-resource language dataset using multimodal representation learning and cross-lingual transfer learning. Appl Soft Comput 157:111553. https://doi.org/10.1016/j.asoc.2024.111553
Gandhi A, Adhvaryu K, Poria S, Cambria E, Hussain A (2023) Multimodal sentiment analysis: A systematic review of history, datasets, multimodal fusion methods, applications, challenges and future directions. Inf Fusion 91:424–444. https://doi.org/10.1016/j.inffus.2022.09.025
Zadeh A, Chen M, Cambria E, Poria S, Morency L-P (2017) Tensor fusion network for multimodal sentiment analysis. In: EMNLP 2017 - conference on empirical methods in natural language processing, Proceedings, Copenhagen, Denmark, pp 1103–1114
Liu Z, Shen Y, Lakshminarasimhan VB, Liang PP, Zadeh A, Morency L-P (2018) Efficient low-rank multimodal fusion with modality-specific factors. In: Gurevych I, Miyao Y (eds) Proceedings of the 56th annual meeting of the Association for Computational Linguistics (Acl), vol 1, pp 2247–2256
Li Z, Guo Q, Pan Y, Ding W, Yu J, Zhang Y, Liu W, Chen H, Wang H, Xie Y (2023) Multi-level correlation mining framework with self-supervised label generation for multimodal sentiment analysis. Inf Fusion 99:101891. https://doi.org/10.1016/j.inffus.2023.101891
Huang C, Zhang J, Wu X, Wang Y, Li M, Huang X (2023) Tefna: Text-centered fusion network with crossmodal attention for multimodal sentiment analysis. Knowl-Based Syst 269:110502. https://doi.org/10.1016/j.knosys.2023.110502
Yuan Z, Liu Y, Xu H, Gao K (2024) Noise imitation based adversarial training for robust multimodal sentiment analysis. IEEE Trans Multimed 26:529–539. https://doi.org/10.1109/TMM.2023.3267882
Liu W, Li W, Ruan Y-P, Shu Y, Chen J, Li Y, Yu C, Zhang Y, Guan J, Zhou S (2024) Weakly correlated multimodal sentiment analysis: New dataset and topic-oriented model. IEEE Trans Affect Comput 1–13. https://doi.org/10.1109/TAFFC.2024.3396144
Zhou J, Zhao J, Huang JX, Hu QV, He L (2021) Masad: A large-scale dataset for multimodal aspect-based sentiment analysis. Neurocomputing 455:47–58. https://doi.org/10.1016/j.neucom.2021.05.040
Poria S, Cambria E, Bajpai R, Hussain A (2017) A review of affective computing: From unimodal analysis to multimodal fusion. Inf Fusion 37:98–125. https://doi.org/10.1016/j.inffus.2017.02.003
Mai S, Hu H, Xing S (2019) Divide, conquer and combine: Hierarchical feature fusion network with local and global perspectives for multimodal affective computing. In: Korhonen A, Traum D, Màrquez L (eds) Proceedings of the 57th annual meeting of the association for computational linguistics, pp 481–492. Association for Computational Linguistics, Florence, Italy. https://doi.org/10.18653/v1/P19-1046
Hazarika D, Zimmermann R, Poria S (2020) Misa: Modality-invariant and -specific representations for multimodal sentiment analysis. In: Proceedings of the 28th ACM international conference on multimedia, pp 1122–1131. Association for Computing Machinery, New York, NY, USA. https://doi.org/10.1145/3394171.3413678
Tsai Y-HH, Bai S, Liang PP, Kolter JZ, Morency L-P, Salakhutdinov R (2019) Multimodal transformer for unaligned multimodal language sequences. In: Korhonen A, Traum D, Marquez L (eds) 57th Annual Meeting of the Association for Computational Linguistics (Acl 2019), pp 6558–6569
Tang J, Liu D, Jin X, Peng Y, Zhao Q, Ding Y, Kong W (2023) Bafn: Bi-direction attention based fusion network for multimodal sentiment analysis. IEEE Trans Circ Syst Video Technol 33(4):1966–1978. https://doi.org/10.1109/TCSVT.2022.3218018
Zadeh A, Liang PP, Poria S, Vij P, Cambria E, Morency L-P (2018) Multi-attention recurrent network human communication comprehension. In: Thirty-second AAAI conference on artificial intelligence / thirtieth innovative applications of artificial intelligence conference / eighth AAAI symposium on educational advances in artificial intelligence, pp 5642–5649
Wang Z, Wan Z, Wan X (2020) Transmodality: An end2end fusion method with transformer for multimodal sentiment analysis. In: Proceedings of the web conference 2020, pp 2514–2520. Association for Computing Machinery, New York, NY, USA. https://doi.org/10.1145/3366423.3380000
Chen C, Hong H, Guo J, Song B (2023) Inter-intra modal representation augmentation with trimodal collaborative disentanglement network for multimodal sentiment analysis. IEEE/ACM Trans Audio Speech Lang Process 31:1476–1488. https://doi.org/10.1109/TASLP.2023.3263801
Wu Y, Lin Z, Zhao Y, Qin B, Zhu L-N (2021) A text-centered shared-private framework via cross-modal prediction for multimodal sentiment analysis. In: Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pp 4730–4738
Han W, Chen H, Gelbukh A, Zadeh A, Morency L-P, Poria S (2021) Bi-bimodal modality fusion for correlation-controlled multimodal sentiment analysis. In: Proceedings of the 2021 international conference on multimodal interaction, pp 6–15. https://doi.org/10.1145/3462244.3479919
Devlin J, Chang M-W, Lee K, Toutanova K (2019) Bert: Pre-training of deep bidirectional transformers for language understanding. In: 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Naacl Hlt 2019), vol 1, pp 4171–4186
Hochreiter S, Schmidhuber J (1997) Long Short-Term Memory. Neural Comput 9(8):1735–1780. https://doi.org/10.1162/neco.1997.9.8.1735
Khosla P, Teterwak P, Wang C, Sarna A, Tian Y, Isola P, Maschinot A, Liu C, Krishnan D (2020) Supervised contrastive learning. In: Larochelle H, Ranzato M, Hadsell R, Balcan MF, Lin H (eds) Advances in neural information processing systems, vol 33, pp 18661–18673
Zadeh A, Zellers R, Pincus E, Morency L (2016) MOSI: multimodal corpus of sentiment intensity and subjectivity analysis in online opinion videos
Bagher Zadeh A, Liang PP, Poria S, Cambria E, Morency L-P (2018) Multimodal language analysis in the wild: CMU-MOSEI dataset and interpretable dynamic fusion graph. In: Gurevych I, Miyao Y (eds) Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp 2236–2246. Association for Computational Linguistics, Melbourne, Australia. https://doi.org/10.18653/v1/P18-1208
Sun Z, Sarma PK, Sethares WA, Liang Y (2020) Learning relationships between text, audio, and video via deep canonical correlation for multimodal language analysis. In: Thirty-fourth AAAI conference on artificial intelligence, the thirty-second innovative applications of artificial intelligence conference and the tenth AAAI symposium on educational advances in artificial intelligence, vol 34, pp 8992–8999
Yu W, Xu H, Yuan Z, Wu J (2021) Learning modality-specific representations with self-supervised multi-task learning for multimodal sentiment analysis. Proceedings of the AAAI conference on artificial intelligence, vol 35, no 12, pp 10790–10797. https://doi.org/10.1609/aaai.v35i12.17289
Yang B, Shao B, Wu L, Lin X (2022) Multimodal sentiment analysis with unidirectional modality translation. Neurocomputing 467:130–137. https://doi.org/10.1016/j.neucom.2021.09.041
Kim K, Park S (2023) Aobert: All-modalities-in-one Bert for multimodal sentiment analysis. Inf Fusion 92:37–45. https://doi.org/10.1016/j.inffus.2022.11.022
Wang J, Wang S, Lin M, Xu Z, Guo W (2023) Learning speaker-independent multimodal representation for sentiment analysis. Inf Sci 628:208–225. https://doi.org/10.1016/j.ins.2023.01.116
Wang D, Guo X, Tian Y, Liu J, He L, Luo X (2023) Tetfn: A text enhanced transformer fusion network for multimodal sentiment analysis. Pattern Recognit 136:109259. https://doi.org/10.1016/j.patcog.2022.109259
Tang Z, Xiao Q, Zhou X, Li Y, Chen C, Li K (2023) Learning discriminative multi-relation representations for multimodal sentiment analysis. Inf Sci 641:119125. https://doi.org/10.1016/j.ins.2023.119125
Issa B, Jasser MB, Chua HN, Hamzah M (2023) A comparative study on embedding models for keyword extraction using keybert method. In: ICSET 2023 - 2023 IEEE 13th international conference on system engineering and technology, Proceeding, pp 40–45. https://doi.org/10.1109/ICSET59111.2023.10295108
Loper E, Bird S (2002) Nltk: The natural language toolkit. In: ACL-02 Workshop on effective tools and methodologies for teaching natural language processing and computational linguistics, Proceedings, pp 63–70
Acknowledgements
The authors would like to express their gratitude for the assistance provided by our host institutions, whose support has been instrumental in making this collaborative work successful. Additionally, we extend our heartfelt thanks to friends and colleagues, who have provided valuable feedback on our work.
Funding
This work was supported in part by the National Natural Science Foundation of China under Grants 61702462 and 61906175; the Natural Science Foundation of Henan under Grants 242300421220 and XJTLU RDF-21-02-008; Jiangsu Double-Innova-tion Plan No. JSSCBS20230474; the Henan Provincial Science and Technology Research Project under Grants 232102211006, 232102210044, 232102211017, 232102210055 and 222102210214; the Science and Technology Innovation Project of Zhengzhou University of Light Industry under Grant 23XNKJTD0205; the Undergraduate Universities Smart Teaching Special Research Project of Henan Province under Grant Jiao Gao [2021] No. 489-29; and the Doctor Natural Science Foundation of Zhengzhou University of Light Industry under Grants 2021BSJJ025 and 2022BSJJZK13.
Author information
Authors and Affiliations
Contributions
Zuhe Li: Methodology design and development; creation of models; preparation, creation and/or presentation of the published work; specifically writing the initial draft (including substantive translation). Panbo Liu: Conducting the research and investigation process, specifically performing the experiments and data/evidence collection, programming, software development, designing computer programs, implementing computer code and supporting algorithms, and testing existing code components. Yushan Pan: Ideas: Formulation or evolution of overarching research goals and aims, development or design of methodology and creation of models. Oversight and leadership responsibility for research activity planning and execution, including mentorship external to the core team. Jun Yu: Verification, whether as part of the activity or separately, of the overall replication/reproducibility of the results/experiments and other research outputs. Weihua Liu: Preparation, creation, and/or presentation of the published work, specifically writing the initial draft (including substantive translations). Haoran Chen: Preparation, creation, and/or presentation of the published work, specifically, writing the initial draft (including substantive translation). Yiming Luo: Management activities to annotate (produce metadata), scrub data, and maintain research data (including software code where it is necessary to interpret the data) for initial use and later reuse. Hao Wang: Preparation, creation, and/or presentation of published work by those from the original research group, specifically critical review, commentary, or revision, including the pre- or post-publication stages.
Corresponding author
Ethics declarations
Competing interests
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Ethical and informed consent for data used
The authors confirm that there were no human research participants involved in this study and that the research received approval from the university’s ethical committee.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Li, Z., Liu, P., Pan, Y. et al. Text-dominant multimodal perception network for sentiment analysis based on cross-modal semantic enhancements. Appl Intell 55, 188 (2025). https://doi.org/10.1007/s10489-024-06150-1
Accepted:
Published:
DOI: https://doi.org/10.1007/s10489-024-06150-1