
Abstract
Recently, edge-cloud has attracted much attention by its promising prospect in terms of facilitating the benefits of edge and cloud together. It is promising for urban video systems that require efficient and effective processing for their intelligent monitoring drives on various ends, like sky drones and land cameras. For instance, to support crowd recognition for public safety, the tasks to crowd recognition need to be placed into all processing nodes in the video systems for processing effectively. This is a challenging problem to facilitate the edge-cloud orchestrated scenarios. However, the variability of tasks based on their complexities is not considered fully in existing strategies. In this regard, we model and analyse task placement for crowd recognition in edge-cloud intelligent video systems. Then, our strategies are proposed which are referred to Node-Graph based Task Placement (NGTP) and Cluster-Graph based Task Placement (CGTP). Specifically, with the help of data dependencies, NGTP utilises the greedy approach with node graphs in the centralised way for general scenarios. Comparatively, CGTP utilises data dependency and similarity for task placing in the decentralised way for emergency scenarios. The experiments demonstrate the superior and effectiveness performance in forming tasks cost and running time of our proposed approaches.
Similar content being viewed by others



1 Introduction
Recently, edge-cloud systems [1] have become a widely-discussed computing paradigm which have been viewed as a promising approach to seamlessly connect ends, edges and clouds. In the view of cloud computing, it focuses on the virtualisation and flexibility of resources, which merges huge various resources (computing, storage, network, etc.) together in the pay-as-you-go manner. In the view of edge computing, it involves Internet of Things (IoTs) by enabling computing capabilities for end devices. Therefore, the combination of them, i.e., the edge-cloud paradigm [2, 3], could provide effective solutions which can leverage their individual features, especially in large-scale intelligent video systems.
In the view of public safety, intelligent video systems [2] provide important approaches for effective, efficient and timely monitoring on crowd movements. It is valuable in supporting emergency management, disaster control and so on, which requires deep investigations on various points, like the computing paradigm in this paper.
Regarding intelligent video systems, particularly in those large-scale urban ones, numerous varied video cameras and computing nodes require the scalability [4] in the aspects of sensing, computing, storage, transmission, and so on, making it a suitable circumstance for edge-cloud’s utilisation. Specifically, various cameras produce plenty of video data in monitoring urban areas. Recently, drone systems have been utilised to monitor urban areas effectively by enhancing traditional video devices. To process these video data intelligently, multiple edges and clouds are crucial to cooperate together. In other words, varied urban-range static and dynamic cameras (ends) produce plenty of video data, then the edge-cloud paradigm could then manage the processing tasks accordingly among clouds and edges (clouds provide “unlimited” computing capacities, edges provide computing capacities near ends). Therefore, edge-cloud is a promising approach for urban intelligent video systems, which is referred to Edge-Cloud based Urban Intelligent Video Systems (ECUIVSs).
Considering the large-scale urban areas, it is reasonable to involve flying drones to provide versatile and dynamic video surveillance for public safety [5, 6], not just fixed land cameras [7, 8]. There are two main types of cameras in these systems: some cameras have been installed on the ground, such as traffic monitors covering roads and crosses, security monitors covering crowded places or valuable issues, and so on. They are referred as “land ends” in this paper. Another is “sky ends”, and these ends are deployed on drones to enhance the existing systems by their flexibility and wide vision. For example, the urban areas without existing land nodes covered can be monitored by the drones with related cameras as needed. These two types provide rich video data together for “intelligent” monitoring, forming the data sources.
Based on video data from these data sources, ECUIVSs include cloud services, edge devices, and cameras (ends): cameras are sensing terminals to produce video data, e.g., land cameras and sky cameras. The rest are two kinds of processing nodes: cloud services are the remote cloud processing services; edge devices are the “local” processing servers, which can process data close to the terminals. Edge devices could be further categorized into two different types: one is deployed with drones and sky cameras to form sky nodes; another is deployed on land called land nodes: some of them can be deployed with land cameras, the rest could be deployed with base stations, or deployed solely. In these sky and land nodes, some of them have edge devices and the related capacities on task processing, and some don’t due to incompatible platforms or some other circumstantial constraints. In this paper, edge devices are also called edge servers or simply edges.
Based on ECUIVSs, crowd recognition (including crowd counting [7], crowd abnormal detection [8], etc. ) has been viewed as a critical task in public security areas, like emergency evacuation and crowd management [9, 10], urban and traffic management [11, 12], etc. For instance, it can recognise crowd movement from multiple video sources and analyse important principles to encounter emergent situations by guiding crowd moving effectively to protect lives. Currently, it has attracted several machine learning methods and their distributed extensions, like distributed deep neural networks (DDNNs) [5, 13,14,15,16] to be utilised. Shortly, this computing-intensive task can match the edge-cloud paradigm: firstly, multiple cameras in these systems, as ends, provide video data for the computing task; then the crowd recognition tasks are operated on various edge devices and cloud services.
Specifically, these tasks have some features on computing strengths which need to be considered: for one specific task and its video data, the area of the video covering and related number of crowds could influence the specific computing strength changing. Taking the popular neutral network-based methods [17, 18] as an example, if the specific video covering a large area and many persons, it is necessary to use a high-resolution image/video data to guarantee the accuracy of crowd recognition, which will increase the computing strength clearly: more data input for related models [19]. This paper focuses on the processing phrase, not the training phrase, like [20], to pursue a real-time or a “nearly” real-time processing for these video data.
However, for crowd recognition in ECUIVSs, current placement and scheduling strategies in edge-cloud systems are investigated from diverse perspectives, such as energy-minimization task offloading [21], task offloading for energy efficiency of mobile devices [22], user allocation process in terms of cost-effectiveness [23], and so on. The task placement methods [24] are also presented by considering the tasks’ dependency, which formulates the whole application into various “steps” (tasks) to pursue better performances. But it is a challenge for them to match these crowd recognition tasks in this paper, requiring adequate investigations on the complexity issue of these tasks. In other words, to recognise crowd effectively, these whole systems should consider the monitoring targets: areas and crowds, in terms of the complexities of tasks.
In this regard, focusing on the task placement problem in ECUIVSs, the main contributions of this paper are listed as follows:
-
(1)
The task placement problem is newly formulated for crowd recognition in ECUIVSs upon general or emergency scenarios.
-
(2)
To improve the efficiency of solving this problem, a Node-Graph based Task Placement strategy (NGTP) is proposed by uniting the greedy approach with the “relations” of nodes (graph) together, which is a centralized strategy used for general scenarios.
-
(3)
A Cluster-graph approach is also involved to discover the “relations” and similarities among various processing nodes comprehensively, termed as the novel Cluster-Graph based Task Placement strategy (CGTP), which is a decentralized strategy used for emergency scenarios.
In other words, CGTP is similar to the greedy approach of NGTP, with the extra involving of “locality” of task flowing, which is necessary for a “pure” distributed edge environment without a “powerful” central control on the task placement, like disaster scenarios (fire or earthquake).
The rest of this paper is organised as follows: Sect. 2 illustrates the motivating example of this paper. In Sect. 3, the related work is introduced. Then, the problem formulation and proposed strategies are discussed in Sect. 4. In Sect. 5, a specific use case is discussed based on the motivating example. Lastly, conclusions and future work are given in Sect. 6.
2 Motivating example
In this paper, our work is motivated by the following public safety use case. In a large-scale urban area, it is crucial to discover urban situations and crowd movements, which can effectively protect human’s lives. In this regard, various devices (like drones, land cameras and edge servers) are utilised and deployed concretely to support a system which can recognise crowd effectively and efficiently and also monitor the urban areas and related crowd. Hence, one key objective of the whole system is to recognise the crowd movement by video data to support crowd management, like crowd evacuation, decision making, and so on. To reach the objective, edge-cloud is involved: the crowd recognition function is flexibly in either edge devices or cloud services, as the focusing point of this paper. Hence, how to allocate these tasks into these nodes is the core problem for the whole systems. These crowd recognition tasks could share similar algorithms for simplification due to their common function in this paper.

The architecture of the motivating example
The specific architecture is presented in Fig. 1, where these are three kinds of nodes: sky nodes, land nodes, and cloud nodes. As introduced in Sect. 1, sky nodes are drones with cameras to cover urban areas. They include cameras (end devices), and possible embedded servers (edges). Land nodes are deployed based on existing mature land facilities, like traffic cameras, communication base stations, and so on. Moreover, some land cameras also have (edge) servers deployed together for video data processing. Hence, the land nodes are versatile and irreplaceable. Cloud nodes provide remote cloud services and focus on task assignment and abstract processing of video data from other nodes. In Fig. 1, the crowd recognition tasks work as follow: firstly, cameras on land and sky nodes produce video data to generate these crowd recognition tasks. Then, these tasks are allocated to land, sky or cloud nodes for effective and efficient processing. Lastly, these tasks’ recognition results are integrated to support further functions, like crowd management and related decision makings.
In the architecture, sky nodes communicate with land nodes to send video data or recognition results. Then land nodes communicate with cloud services or other land nodes to send video data or recognition results. One important benefit of this is that the existing land nodes’ equipment can be fully exploited in terms of flexible hardware structures. Currently, all nodes’ communications are via specific wireless media, e.g., WiFi, 5G, etc., or wired lines, e.g., optical fibre, Ethernet, etc. Because these communications are pre-configured and often fixed, the transmission cost in this scenario is much lower than the computing cost.
In more details, some “mini” servers (ARM-based embedded computers) installed on drones (customizable flight platforms), and some x86 servers deployed with land cameras and communication stations can process crowd recognition tasks. Both sky and land nodes can process video data (analyzing and recognizing to the crowd in videos) collected from their cameras, which are worked as edge servers in this paper. They are supported by the cloud services which are the final servers to them.
For the crowd recognition tasks in the scale of a whole urban area, the task placement is one core problem to facilitate edge-clouds for a better performance, which can monitor urban situations and protect lives effectively and efficiently. In this paper, we introduce centralized task placement for general scenarios and decentralized task placement for emergency scenarios separately.
Task placement adopts a centralized strategy in a general scenario. Cloud nodes support the whole placement strategy of relevant tasks (crowd recognition), and can finally control other kinds of nodes (land nodes and sky nodes) for task placement by wired and wireless connections. However, when disasters (fire, earthquake and so on) burst out, the connections between some nodes could be almost unavailable. The centralized strategy will be greatly challenged due to the long time cost on identifying the state of nodes (available or broken), which leads to a high probability of casualties among the crowd in emergency. Therefore, in an emergency scenario, we adopt a distributed strategy: each node finds suitable neighbor nodes to connect for live-saving task placement (like crowd recognition, fire monitoring). This strategy is more flexible and efficient on recognising situations of crowd in the disaster to reduce the probability of casualties.
Other problems, such as designing specific crowd recognition methods or algorithms, like CNN [13], ResNet [25], etc., are out of the range of this paper.
3 Related work
In this section, the existing work on intelligent video systems, edge-cloud systems and distributed deep learning are introduced, which correspond to the basis of this paper, the focusing point and supporting technologies, respectively.
3.1 Intelligent video systems
Intelligent video systems have been widely used for crowd recognition, like pedestrian behaviour modelling [26]. Its application is the basis of our paper. In addition, to detect abnormal moving objects, these video systems can play an important role in unattended object identification [27]. For instance, the reinforcement method is utilised to support the intelligent video surveillance [4].
Considering urban intelligent video systems’ requirements, drone systems have been involved into to enhance video data in the views of flexibility, performance, and so on. Mozaffari et al. [28] discuss the IoT communications in mobile drones for energy efficiency. Sultani et al. [29] focus on the human action recognition of drone videos based on GANs. Similar to our use case, Wu et al. [30] utilise the drone swarms in urban monitoring to present ADDSEN, and Jing et al. [6] discuss the UAV cluster in smart cities with related scheduling problem.
These above works on the application of video system and drone respectively supports the construction of our methods and scenes in ECUIVSs. However, they only focus on a certain, rather than the combination of video system and drone. In our approaches, we link between video system and drone, which makes up for the gap.
3.2 Edge-cloud systems
As another basis of this paper, edge-cloud has been investigated in many views, like the VM migration and transmission power control [31], GPU-based edge configuration and offloading [32], wireless computing optimization [33], and so on.
Considering task management in edge-cloud, Wu et al. [2] discuss video task collaboration, based on video caching and delivery decisions. While Du et al. [34] investigate cost-driven computation offloading by considering diverse communication costs. In another view, Zafari et al. [3] investigate game theory to support the resouce sharing to faciliate the whole edge-cloud systems.
By involving drones, Jeong et al. [35] focus on the bit allocation and path planning by involving the drones into mobile-edge. Similarly, Zhu at al. [36] discuss Multi-Agent Reinforcement Learning (MARL) algorithms to offload related tasks effectively. In comparison, ours focuses on task placement with related complexities in urban intelligent video systems with the help of drones.
Furtherly, task placement or scheduling [37] is important to coordinate multiple parts together in Edge-cloud systems. For example, in large-scale cloud storage, the dynamic scheduling strategy is investigated for QoS guarantee [38]. Current placement and scheduling strategies in edge-cloud systems are investigated from diverse perspectives, such as energy-awareness task offloading [21], task offloading for energy efficiency in mobile devices [22], user allocation process for cost-effectiveness [23], task allocation considering tasks’ dependency [24] . In general, works in Edge-cloud systems provide technical support and we further apply in ECUIVSs.
3.3 Distributed deep learning
Distributed deep learning is recently in the spotlight, Teerapittayanon et al. [16] propose the Distributed Deep Neural Network (DDNN) to map sections of a DNN onto the edge system. Furthermore, DDNN models can running on the surveillance systems [39]. Considering system performance, Lyu et al. [40] reduce the communication cost considering privacy and accuracy.
To guarantee the QoS, Li et al. [41] discuss maximise the inference accuracy while promising application latency requirement. While Gacoin et al. [42] focus on balancing the computing load among the whole swarm in order to maximise the lifetime by the example of drones.Those work in DDNN provide the useful reference and mutual promotion with our work.
4 Task placement in edge-cloud based urban intelligent video systems
In this section, we present task placement for ECUIVSs in the order of (1) general framework, (2) task modelling, and (3) problem formulation. The task modelling is based on the framework, and our problem is formulated based on this modelling.
4.1 Framework
As shown in Fig. 2, the general framework of whole systems in this paper includes three levels: sensing level, processing level and integration level in terms of data flow. Specially, these levels execute these systems from raw data to valuable crowd recognition knowledge.
-
1.
In the sensing level, various video sensors compose of the complicated data input sources, likes video data from land cameras, drones, and so on. In other words, the various “end” devices from the edge-cloud architecture sense the crowd in urban areas for crowd recognition.
Fig. 2 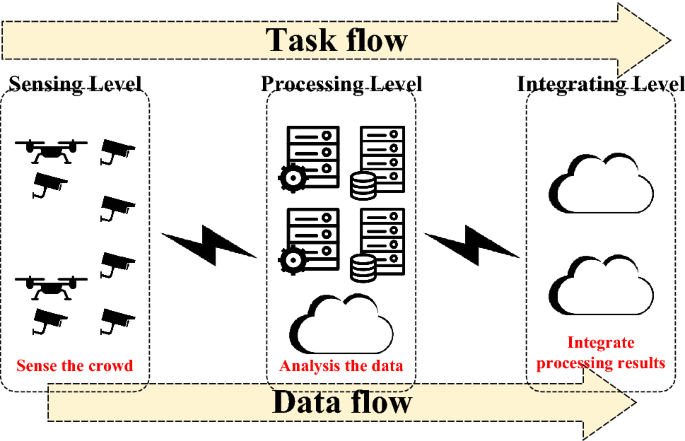
Framework of task placement in this paper
-
2.
In the processing level, sensing data (video, images, etc.) from sensors (end devices) are processed as the main step of crowd recognition: these data are analysed to find out crowd’s movements. There are various kinds of servers in this level: some devices (drones or smart monitors) have light-scale embedded computers which can process video data locally. Some servers deployed with land cameras or communication base stations, which are the important power to process video data. Cloud services are the final servers to process crowd recognition tasks in the whole systems.
-
3.
In the integrating level, the primary objective is to integrate all processing results from the processing level, e.g., crowd recognition results from video data. In this level, cloud nodes (cloud services) are the final step of transmission and computing. They receive processed data (recognition results) and integrate to produce a general picture of urban-scale crowd movement. Shortly, it is the afterword task of crowd recognition tasks, which is not the focusing point of this paper.
-
4.
Network structure and data flow: firstly, various sensors collect video data and transmit them to processing nodes, edge servers or cloud services. After these processing nodes, processed results could transmit to cloud nodes in the integration level. The network structure of these systems in this paper are built on wireless or wired connections based on communication infrastructures. And in these existing infrastructures, these established complicated network connections are without changing frequently.

Data flows are the routes of video data, which are determined by previous transmissions. For instance, if sky node A transmit its video data to land node B, this transmission represents one flow as one certain part of whole data flows. Data flows are the basis of our crowd recognition tasks in this paper. In this regard, these previous dependencies of these tasks are discussed to introduce Task Flows, which are the routes of tasks’ potential flowing among the previous nodes. Task Flows are determined by previous Data flows. For example, if there is a data flow from sky node A to land node B, a task flow exists from A to B to describe the possible flowing route (a task can “flow” from A to B for processing).
4.2 Task modelling in edge-clouds
As introduced before, tasks in this paper focus on video data processing, which are generated by related cameras on sky and land nodes. In other words, these video data “produce” and decide crowd recognition tasks. Hence, these tasks only can be processed by the nodes which “have” the corresponding video data. For example, one sky node (if the node has an edge; Otherwise, it is just a pure sensor without any processing capabilities) can process the video data sensed by itself, and other nodes which receive the video data can also process the task (if the nodes have edges).
Hence, tasks in this paper compose of set T, including various task \(t_j\), which can be described by 4-tuple as below:
In Eqs. (1, 2), TID is the set of tasks’ ID, \(TID=\{{tid}_1,\ldots ,{tid}_J\}\). TDQ is the set to video data qualities of tasks, \(TDQ=\{{tdq}_1,\ldots ,{tdq}_J\}\). TDZ is the set to data zones of tasks, \(TDZ=\{{tdz}_1,\ldots ,{tdz}_J\}\). TC is the set to complexities of tasks, \(TC=\{{tc}_1,\ldots ,{tc}_J\}\).
In these components, the qualities of tasks TDQ are to describe the qualities of their video data in terms of crowd recognition, and they are five levels: very high, high, medium, low, and very low. The complexities of tasks TC are to describe the complexities as shown by Eq. (3), and this equation expresses that the processing complexity replies on the specific zone’s area as introduced in Sect. 1. Since the complication of specific crowd recognition approaches, its number of crowds may be included into the abstract function.
The Data zones TDZ in the components: in ECUIVSs, each camera has a specific zone in the urban area to observe. There are two assumptions on data zones: (1) these data zones are fixed during the placing processes, due to that the systems relies on existing equipment, like land cameras. (2) These cameras together should cover the whole urban area “target” for adequate video data for the intelligent processing and related task placement. To narrow down the topic of this paper, we assume that the video data are “adequate”, which means that the area covering problem is solved and out of the range of this paper.
Centralised and decentralised placement: in ECUIV Ss, there are two main deployment ways on task placement: a centralized way means that task placement is operated by a centralized control node (like cloud nodes). The control node computes suitable task allocations and sends commands to other nodes (like land nodes and sky nodes); a decentralized way means that task placement is operated without a centralized control. Every node will run the task placement function based on their own “vision”: neighbour nodes. In the real world, both ways play their own roles to match different circumstances for public safety scenarios as discussed in Sect. 2.
4.3 Problem formulation
In this subsection, the task placement problem is formulated.
Firstly, all nodes in one system compose of set N, including various node \(n_i\), which can be described by 5-tuple as below:
In Eqs. (4, 5), NID is the set of nodes’ ID, \(NID=\{{nid}_1, \ldots , {nid}_I\}\). NT is the set of types of nodes, \(NT=\{{nt}_1,\ldots ,{nt}_I\}\). NL is the set of locations of nodes, \(NL=\{{nl}_1,\ldots ,{nl}_I\}\). NC is the set of computing capacities of nodes, \(NC=\{{nc}_1,\ldots ,{nc}_I\}\) . NDZ is the set of data zones of nodes, \(NDZ=\{{ndz}_1,\ldots ,{ndz}_I\}\)
Based on previous discussions, the objective of this paper is to complete all tasks as soon as possible. Hence, the core problem of this paper is to minimise the tasks’ processing time by placing multiple tasks to multiple nodes. For one specific task, the placement is to pick one node from multiple nodes to process the task.
Problem 1: task placement
In Eqs. (6–8), the purpose on minimising the tasks’ processing time is demonstrated and the tasks’ processing times are discussed: Eq. (6) represents the processing time of the whole system which is determined by the processing time of slowest node. Eq. (7) represents the processing time of one specific node which is summed up by the processing times of all tasks allocated to this node. Eq. (8) represents the single processing time of task \(t_{ik}\) processed by node \(n_i\). It is clear that its result has a positive relation with the complexity of the task \({tc}_{ik}\), and has a negative relation with the capability of the node \({nc}_i\) (High capability can decrease the processing time).
In Eqs. (9–11), some constraints are provided: task \(t_{ik}\) are from T, and all task \(t_j\) from T need to be placed to one specific node \(n_i\). Eq. (12) is another constraint on task placement: the data zone of the specific node should contain the data zones of the tasks which are placed to this node.
Clearly, the purpose of problem can be summarized as finding out the placement to minimise the general processing time, and the placement should include all tasks and their placed nodes respectively.
Theorem 1
(Problem Type) Problem 1 is a \(NP-Complete\) (NPC) problem.
Proof
For Problem 1, to measure placements, Eqs. (6, 7) can be utilised to obtain specific values. The polynomial sorting process on these values decides the problem is a NP problem. The given task set T can be viewed as the set S, node set N can be viewed as the list of subsets, and Eq. (8) \(Time(n_i,t_{ik} )\) can be used to calculate the weights of each subset, the task placement problem can be reduced to a classical NP-complete problem: Set packing problem [43]. Therefore, Problem 1 is an NPC problem. \(\square\)
Based on system modelling in this section, we will present our novel strategies in the next subsection.
5 Task placement strategies
In this section, we present our work on task placement strategies for ECUIVSs. Separately, for task placement with central control we present NGTP and for placement without central control CGTP approach is presented.
5.1 Task placement strategy in a centralized way
One instinctive approach for task placement is the greedy approach. Based on the task flows discussed before, the graph of nodes is another powerful tool. Hence, we present our Node-Graph based Task Placement strategy (NGTP).
In Algorithm (1), nodes graphing are the first step to organise nodes by video data’s dependencies. Secondly, tasks are placed to nodes by flowing tasks to all reachable nodes since the graph, and selecting the right one (Line 7 in Step2 of NGTP) by the greedy approach.Lastly, placement A is generated as a 0-1 matrix.

Theorem 2
(Complexity) The computing complexity of the NGTP is \(O({JI}^{2})\).
Proof
The strategy includes two main steps.
For step 1: the complexity of this step depends on the numbers of nodes and possible links, so, it is \(O(I^{2})\) .
For step 2: in the placing step, the complexity depends on nodes and tasks, and its complexity is \(O(J \times log(J)+I+I+J \times (I^{2}+I+I+I))=O({JI}^{2})\).
Hence, the final complexity is \(O(I^{2})+O({JI}^{2})=O({JI}^{2})\) . \(\square\)
Theorem 3
(Approximation ratio) NGTP is an \(2-approximation\) algorithm.
Proof
The result of NGTP is an placement of tasks to nodes. It relies on the resources of nodes N, and the tasks T. Its overall processing time is OT. The optimal solution’s the overall time is \({OT}^{*}\), which can be viewed as the result of a traversing strategy. Considering that the number of tasks J is an important factor in our problem, we will discuss the relation between OT and \({OT}^{*}\) progressively based on it.
When the number of tasks is one, OT is equal to \({OT}^{*}\), as shown by Eq. (13). Because there is only one task, and it will be allocated the most “powerful” node to obtain the shortest processing time in both strategies.
When the number of tasks is two, considering Eq. (13) and the incremental processing from one task to two tasks, we can obtain the following relation.
Ulteriorly, considering the greedy placing process of NGTP (“larger” tasks will be placed preferentially), we can obtain the following relation.
Similarly, when the number of tasks is three, we can obtain the following relations.
Therefore, when the number of tasks is J (\(J > 2\)), we have the following relations.
Based on Eq. (17) and the “simple” fact \(0 \le OT(J-2) \le OT(J-1)\), we have:
Therefore, NGTP is an \(2-approximation\) algorithm. \(\square\)
Clearly, NGTP is a practicable strategy with \(O({JI}^2)\) complexity and \(2-approximation\).
5.2 Task placement strategy in a decentralized way
As introduced in Sects. 1 and 2, a decentralized task placement strategy is crucial for reducing probability of casualties upon emergency scenarios. Hence, we present a novel Cluster-Graph based Task Placement strategy (CGTP).
As shown in Algorithm (2), CGTP includes three main steps: (1) Node Clustering is the first step to organise nodes by their capabilities; (2) Node graphing is the second step to organise nodes by the video data dependency, which is the same to NGTP; (3) Task flowing is the third step to place tasks into suitable nodes, by flowing tasks to all reachable nodes, based on the clustering structure in the graph. In this step, these different clusters represent a decentralised way to place tasks for the general purpose. Lastly, matrix A is generated as the result.

Theorem 4
(Complexity) The computing complexity of CGTP is \(O({JI}^2)\).
Proof
The strategy includes two main steps.
For step 1: the complexity of clustering algorithm depends on specific algorithms. In this paper, DBSCAN is selected as the clustering approach with a complexity of \(O(J \times log(J))\) [44];
For step 2: the complexity of this step depends on the numbers of nodes and possible links, so, it is \(O(I^2)\) ;
For step 3: the complexity of these instructions before the loop is \(O(I^2+I+I)=O(I^2)\) . For the loop, the complexity is \(O(J \times (I+J+{JI}^2))=O(J^2 I^2)\) , so, the general complexity is \(O(J \times (I+I+I^2+I+I+I+I))=O({JI}^2)\) .
Hence, the final complexity is \(O({JI}^2)\) . \(\square\)
Theorem 5
(Approximation ratio) CGTP is an \(J-approximation\) algorithm.
Proof
Similar to NGTP, the result of CGTP is an placement of tasks to nodes. It relies on the resources of nodes N, and the tasks T. Its overall processing time is OT. And the optimal solution’s the overall time is \(OT^*\), which can be viewed as the result of a traversing strategy.
Compared to NGTP , CGTP allocate tasks to nodes “locally” depended on “visions” of nodes. Hence, considering the “worst” case, we can obtain.
Like NGTP , we have:
Hence, we can obtain the following relation:
Therefore, NGTP is an \(J-approximation\) algorithm, and J is a constant to describe the number of tasks, which depends on specific cases. \(\square\)
In summary, this section presents NGTP and CGTP to manage tasks among the edge-cloud environments effectively.
6 Case study
In this section, we take the motivating example as the use case to discuss task placement with related strategies.
6.1 Background
As introduced in Sect. 2, the motivating example utilises video data from cameras on land nodes and sky nodes together for observing crowd movement.
Systems Basis the infrastructure of the system in this paper includes several components as follows:
-
1.
Cloud nodes (services) the private cloud platform is deployed based on CentOS, OpenStack, and physical servers. It generates three VMs as cloud services with the same configuration: one is the root one to collect all video data and recognition results, the other two oversee half nodes (including sky and land ones) respectively.
-
2.
Land nodes land nodes are fixed facilities with private line connections. Some of them have affiliated cameras (traffic cameras, security cameras, and so on) as ends; the rest are “pure” edge devices, which are regular x86 computers.
-
3.
Sky nodes In this use case, some of sky nodes have affiliated computers as edge servers, such as DJI drones and DJI Manifolds [45], which are ARM-based embedded computers designed for some light-scale tasks; The rest are “pure” cameras (drones). During monitoring, all drones are fixed in their locations and heights because of the monitoring requirements. The flying time and battery issues of drones are out of the range of this paper.
-
4.
Communication from the previous introductions, cloud services run on a private cloud, and their internal communication are inside the cloud. Land nodes send video data to cloud services directly via wired lines. Sky nodes send video data to land nodes, due to the widespread distribution of land nodes, via wireless media.
Computing tasks in this use case, all computing tasks have different video data inputs (data zones).
Figure 3(a) shows a sample of urban area (the Melbourne CBD area in Australia) and related computing tasks. It includes black roads, blue circles (land nodes’ data zones) and red circles (sky nodes’ data zones). These data zones decide tasks respectively. Two cloud services oversee the left and right parts of the area, and another one supports these two. To show the details clearly, in Fig. 3(b) we give its top left part in enlarged figure.

A sample of urban area
The general pictures between the complexity and the computing cost of tasks are provided by Eqs. (3) and (8). To implement them, a simple linear function is utilised to link the complexity \({tc}_j\) and the area of data zone area(\({tdz}_j\)) in this section, just like discussed in Sect. 1: the larger area of video covering, the more video data involved for the processing. Taking one popular real-time object recognition neural network: YOLO [46] as an example, except the well-trained network structure, its complexity depends on the input video images’ resolutions, which are closely related to the area of video covered (the larger area requires the higher resolution to guarantee the quality of recognition). Hence, the simple linear function is reasonable and representative. For other different crowd recognition solutions, the specific function could be adjusted respectively. For example, the number of crowds could be involved for other crowd recognition solutions.
6.2 System analysis and comparison
In this subsection, we operate our proposed strategies. Meanwhile, as an effective and wide-used optimisation solution, GA (Generic Algorithm) can be adapted into this use case based on [47]. Based on [47], we define the difference between twice GA results less than \(10^{-9}\) as stopping criteria. Similarly, MCF (Most Capacity First) approach is a powerful greedy tool for EUA problem in edge computing [23], which can be utilized in the situation of this paper. Compared to our strategies, its greedy approach focuses on the computing capacity of nodes, and has not considered the task flows constraint (Eq. (12)). So, it could need to “rollback” to find out the suitable result. Considering the task placement, we will compare the performances of these strategies, during nodes increasing.
When nodes increase, these added nodes may have edge devices or not. Hence, these are three classes: (1) added nodes have same edge devices, (2) added nodes don’t have, and (3) some added nodes have and some haven’t. The proportion is decided by initial fixed settings. What's more, tasks have data zones which may overlap with other tasks as shown in Fig. 3(a). Hence, there are two classes: (1) tasks with overlapped data zones can be viewed as repetitive tasks to be removed, (2) these repetitive tasks are kept. As shown in Table 2, there are six situations based on previous classes.
Accordingly, Figs. 4, 5, 6, 7, 8 and 9 represent these strategies’ performances in these six situations respectively. The horizontal coordinates are the numbers of nodes; the left vertical coordinates are the performances of forming tasks cost (FTC) (the times to operate all tasks based on allocations). To normalize them, the FTC are measured by SU (Standard Unit), and one SU means the time that the strongest capacity’ node processes the task with the smallest data zone, based on Eqs. (5–7). In these figures, we define solid lines as the FTC and dotted as running time. What's more, lines in blue signifying NGTP’s results, red signifying CGTP’s, green signifying GA’s and yellow signifying MCF’s. In this example, the right vertical coordinates are the calculating times of obtaining the allocations, which is operated on an X86 computer (Intel i5-8250U CPU, 16 GB memory, and Windows 10 Home).
From these figures, we can find out that: in all cases, NGTP performs better in FTC than CGTP during nodes increasing, and CGTP runs faster than NGTP in most cases. Since NGTP generates the node graph first, by using the node graph to manage the nodes, which improve the task management, but slows down the running speed. In the view of FTC, due to premature convergence occurs, GA preforms between the previous two approaches in most cases, but its running speed is slower. MCF is close to NGTP in the view of FTC, and they are worse than NGTP’s in some spots, due to the possible rollbacks in the greedy searching process. In other words, NGTP obtains the best result in the centralised way with medium costs in most cases. CGTP runs fastest, but its decentralised way causes the inadequate optimisation on task placement, compared to other strategies. As a centralised strategy, GA fails to produced better result than NGTP in these cases. And it runs slower than NGTP in some cases like Fig. 5, some parts of Figs. 6 and 8, due to its instability. Shortly, NGTP and CGTP are stable and practicable in centralised and decentralised ways, respectively, both are better than GA and MCF.

Results in Situation 1

Results in Situation 2

Results in Situation 3

Results in Situation 4

Results in Situation 5

Results in Situation 6
6.3 Further discussions
In this subsection, we discuss some issues furtherly.
Firstly, let’s take Situation 1 as an example: during the nodes increasing, the results increase, meaning that added nodes (tasks) raise the general processing time. Then, they become stable, even decreasing, implying that more nodes also involve more edges to enhance the capacity and balance tasks increasing.
Secondly, let’s take Situations 1, 2 and 3 together as an example to consider edges: during nodes increasing, results in Situation 1 are the lowest, ones in Situation 2 are the highest, and ones in Situation 3 are in the middle. It is clear that added nodes without edges can increase the results as Situation 2 (tasks increase but the general computing capacity keeps stable), but added nodes with edges can control the increasing in different levels as shown in Situations 1 and 3.
Thirdly, considering Situations 2 and 5, if the added nodes have no edges, the results decrease subtle when repetitive tasks can be removed. But if the added nodes with edges in various levels (Situations 1 and 4, Situations 3 and 6), the differences are noticeably. It means that added nodes with edges has the effect on decreasing the general processing times, but removing repetitive tasks cannot has the same effort. In other words, the repetitive task moving approach is not a necessary mean for the whole systems.
Finally, in the real world, NGTP and CGTP can be utilized together: NGTP is the common-used one to place tasks, which is deployed on one cloud node as the centralized control, and CGTP can be deployed on various nodes to handle accidents, like NGTP failed (or partial failed).
In summary, our strategies are indeed practicable on task placement with efficient improvements in both centralized and decentralized ways.
7 Conclusions and future work
Recently, intelligent urban video systems play essential roles in public management. To improve the systems with edge-cutting techniques, edge-cloud systems can be adopted as an emerging computing paradigm. In this regard, the task placement is one crucial problem. In this paper, the problem was formulated and analysed. To improve the efficiency, we presented two strategies, namely NGTP and CGTP the greedy-graph approach and the cluster-graph approach can be implemented in the centralized way and the decentralized way to enhance task placement, respectively. Lastly, the experiments demonstrate the superior performance in forming tasks cost and running time of our approaches.
In future, we will improve our work in the view of energy-saving and hybrid algorithm: the battery saving on drones can prolong drones’ flight times without battery charging or replacing, which can then improve the reliability for security-critical situations. Similarly, the hybrid algorithm of decentralized and centralized could be adapted to both general and emergency scenarios which can be without switching. The hybrid algorithm could save switching time to place the life-saving tasks quickly and efficiently and could also improve the performance on forming tasks cost, running time and the robustness for various situations.
Data availability
All data generated or analysed during this study are included in this published article (and its additional files).
References
Mäkitalo, N., Ometov, A., Kannisto, J., Andreev, S., Koucheryavy, Y., Mikkonen, T.: Safe, secure executions at the network edge: coordinating cloud, edge, and fog computing. IEEE Softw. 35(1), 30–37 (2018). https://doi.org/10.1109/MS.2017.4541037
Wu, D., Bao, R., Li, Z., Wang, H., Wang, R.: Edge-cloud collaboration enabled video service enhancement: A hybrid human-artificial intelligence scheme. arXiv:abs/2103.12516 (2021)
Zafari, F., Leung, K., Towsley, D., Basu, P., Swami, A., Li, J.: Let’s share: a game-theoretic framework for resource sharing in mobile edge clouds. arXiv:abs/2001.00567 (2020)
Hu, H., Shan, H., Wang, C., Sun, T., Zhen, X., Yang, K., Yu, L., Zhang, Z., Quek, T.Q.S.: Video surveillance on mobile edge networks—a reinforcement-learning-based approach. IEEE Internet Things J. 7(6), 4746–4760 (2020). https://doi.org/10.1109/JIOT.2020.2968941
Bisagno, N., Xamin, A., De Natale, F., Conci, N., Rinner, B.: Dynamic camera reconfiguration with reinforcement learning and stochastic methods for crowd surveillance. Sensors 20(17), 4691 (2020). https://doi.org/10.3390/s20174691
Jin, Y., Qian, Z., Yang, W.: Uav cluster-based video surveillance system optimization in heterogeneous communication of smart cities. IEEE Access 8, 55654–55664 (2020). https://doi.org/10.1109/ACCESS.2020.2981647
Gao, J., Yuan, Y., Wang, Q.: Feature-aware adaptation and density alignment for crowd counting in video surveillance. (2020)
Bansod, S.D., Nandedkar, A.V.: Crowd anomaly detection and localization using histogram of magnitude and momentum. Vis. Comput. 36(3), 609–620 (2020)
Zhang, G., Lu, D., Liu, H.: Iot-based positive emotional contagion for crowd evacuation. IEEE Internet Things J. 8(2), 1057–1070 (2021). https://doi.org/10.1109/JIOT.2020.3009715
Zhou, M., Dong, H., Wang, X., Hu, X., Ge, S.: Modeling and simulation of crowd evacuation with signs at subway platform: a case study of beijing subway stations. IEEE Trans. Intell. Transp. Syst. (2020). https://doi.org/10.1109/TITS.2020.3027542
Nawaratne, R., Kahawala, S., Nguyen, S., De Silva, D.: A generative latent space approach for real-time road surveillance in smart cities. IEEE Trans. Ind. Inform. 17(7), 4872–4881 (2021). https://doi.org/10.1109/TII.2020.3037286
Liu, C., Huynh, D.Q., Sun, Y., Reynolds, M., Atkinson, S.: A vision-based pipeline for vehicle counting, speed estimation, and classification. IEEE Trans. Intell. Transp. Syst. (2020). https://doi.org/10.1109/TITS.2020.3004066
Chen, J., Xiu, S., Chen, X., Guo, H., Xie, X.: Flounder-net: an efficient cnn for crowd counting by aerial photography. Neurocomputing 420, 82–89 (2021). https://doi.org/10.1016/j.neucom.2020.09.001.
Chen, J., Li, K., Deng, Q., Li, K., Yu, P.S.: Distributed deep learning model for intelligent video surveillance systems with edge computing. IEEE Trans. Ind. Inform. (2019). https://doi.org/10.1109/TII.2019.2909473
Tian, Y., Lei, Y., Zhang, J., Wang, J.Z.: Padnet: pan-density crowd counting. IEEE Trans. Image Process. 29, 2714–2727 (2020). https://doi.org/10.1109/TIP.2019.2952083
Kang, M., Yang, G., Yoo, Y., Yoo, C.: Tensorexpress: In-network communication scheduling for distributed deep learning. (2020). https://doi.org/10.1109/CLOUD49709.2020.00014
Pudasaini, D., Abhari, A.: In: Scalable object detection, tracking and pattern recognition model using edge computing. Society for Computer Simulation International, San Diego, CA, USA (2020)
Li, J., Xue, Y., Wang, W., Ouyang, G.: Cross-level parallel network for crowd counting. IEEE Trans. Ind. Inform. 16(1), 566–576 (2020). https://doi.org/10.1109/TII.2019.2935244
Langer, M., He, Z., Rahayu, W., Xue, Y.: Distributed training of deep learning models: a taxonomic perspective. IEEE Trans. Parallel Distrib. Syst. 31(12), 2802–2818 (2020). https://doi.org/10.1109/TPDS.2020.3003307
Xu, C., Zheng, G., Zhao, X.: Energy-minimization task offloading and resource allocation for mobile edge computing in noma heterogeneous networks. IEEE Trans. Veh. Technol. 69(12), 16001–16016 (2020). https://doi.org/10.1109/TVT.2020.3040645
Chen, Y., Zhang, N., Zhang, Y., Chen, X., Wu, W., Shen, X.S.: Toffee: task offloading and frequency scaling for energy efficiency of mobile devices in mobile edge computing. IEEE Trans. Cloud Comput. (2019). https://doi.org/10.1109/TCC.2019.2923692
Lai, P., He, Q., Grundy, J., Chen, F., Abdelrazek, M., Hosking, J.G., Yang, Y.: Cost-effective app user allocation in an edge computing environment. IEEE Trans. Cloud Comput. (2020). https://doi.org/10.1109/TCC.2020.3001570
Lee, J., Ko, H., Kim, J., Pack, S.: Data: dependency-aware task allocation scheme in distributed edge clouds. IEEE Trans. Ind. Inform. 16(12), 7782–7790 (2020). https://doi.org/10.1109/TII.2020.2990674
Zhang, C., Du, H.: Dmora: decentralized multi-sp online resource allocation scheme for mobile edge computing. IEEE Trans. Cloud Comput. (2020). https://doi.org/10.1109/TCC.2020.3044852
Yi, S., Li, H., Wang, X.: Pedestrian behavior modeling from stationary crowds with applications to intelligent surveillance. IEEE Trans. Image Process. 25(9), 4354–4368 (2016). https://doi.org/10.1109/TIP.2016.2590322
Filonenko, A., Jo, K.H.: Unattended object identification for intelligent surveillance systems using sequence of dual background difference. IEEE Trans. Ind. Inform. 12(6), 2247–2255 (2016). https://doi.org/10.1109/TII.2016.2605582
Mozaffari, M., Saad, W., Bennis, M., Debbah, M.: Mobile unmanned aerial vehicles (UAVS) for energy-efficient internet of things communications. IEEE Trans. Wirel. Commun. 16(11), 7574–7589 (2017). https://doi.org/10.1109/TWC.2017.2751045
Sultani, W., Shah, M.: Human action recognition in drone videos using a few aerial training examples. arXiv e-prints arXiv:1910.10027 (2019)
Wu, D., Arkhipov, D.I., Kim, M., Talcott, C.L., Regan, A.C., McCann, J.A., Venkatasubramanian, N.: Addsen: Adaptive data processing and dissemination for drone swarms in urban sensing. IEEE Trans. Comput. 66(2), 183–198 (2017). https://doi.org/10.1109/TC.2016.2584061
Rodrigues, T.G., Suto, K., Nishiyama, H., Kato, N.: Hybrid method for minimizing service delay in edge cloud computing through vm migration and transmission power control. IEEE Trans. Comput. 66(5), 810–819 (2017). https://doi.org/10.1109/TC.2016.2620469
Kim, J., Ullah, S., Kim, D.H.: Gpu-based embedded edge server configuration and offloading for a neural network service. J. Supercomput. (2021)
Wang, F., Xu, J., Wang, X., Cui, S.: Joint offloading and computing optimization in wireless powered mobile-edge computing systems. IEEE Trans. Wirel. Commun. 17(3), 1784–1797 (2018). https://doi.org/10.1109/TWC.2017.2785305
Du, M., Wang, Y., Ye, K., Xu, C.: Algorithmics of cost-driven computation offloading in the edge-cloud environment. IEEE Trans. Comput. 69(10), 1519–1532 (2020). https://doi.org/10.1109/TC.2020.2976996
Jeong, S., Simeone, O., Kang, J.: Mobile edge computing via a UAV-mounted cloudlet: optimization of bit allocation and path planning. IEEE Trans. Veh. Technol. 67(3), 2049–2063 (2018). https://doi.org/10.1109/TVT.2017.2706308
Zhu, S., Gui, L., Zhao, D., Cheng, N., Zhang, Q., Lang, X.: Learning-based computation offloading approaches in UAVS-assisted edge computing. IEEE Trans. Veh. Technol. 70(1), 928–944 (2021). https://doi.org/10.1109/TVT.2020.3048938
Kim, K., Cho, Y., Eo, J., Lee, C., Han, J.: System-wide time versus density tradeoff in real-time multicore fluid scheduling. IEEE Trans. Comput. 67(7), 1007–1022 (2018). https://doi.org/10.1109/TC.2018.2793919
Zhang, Y., Wei, Q., Chen, C., Xue, M., Yuan, X., Wang, C.: Dynamic scheduling with service curve for QoS guarantee of large-scale cloud storage. IEEE Trans. Comput. 67(4), 457–468 (2018). https://doi.org/10.1109/TC.2017.2773511
Garey, M., Johnson, D.: Computers and intractability: a guide to the theory of NP-completeness (1979)
Ester, M., Kriegel, H., Sander, J., Xu, X.: In: Simoudis, E., Han, J., Fayyad, U.M. (eds.) A density-based algorithm for discovering clusters in large spatial databases with noise, pp. 226–231. AAAI Press, Portland (1996). http://www.aaai.org/Library/KDD/1996/kdd96-037.php
DJI: Manifold-dji. https://www.dji.com/manifold. (2021)
Redmon, J., Divvala, S., Girshick, R., Farhadi, A.: You only look once: unified, real-time object detection. (2016). https://doi.org/10.1109/CVPR.2016.91
Huang, S., Jiau, M., Lin, C.: A genetic-algorithm-based approach to solve carpool service problems in cloud computing. IEEE Trans. Intell. Transp. Syst. 16(1), 352–364 (2015). https://doi.org/10.1109/TITS.2014.2334597
Teerapittayanon, S., McDanel, B., Kung, H.T.: Distributed deep neural networks over the cloud, the edge and end devices. (2017). https://doi.org/10.1109/ICDCS.2017.226
Cheng, M., Sun, Q., Tu, C.: An adaptive computation framework of distributed deep learning models for internet-of-things applications. (2018). https://doi.org/10.1109/RTCSA.2018.00019
Lyu, L., Bezdek, J.C., He, X., Jin, J.: Fog-embedded deep learning for the internet of things. IEEE Trans. Ind. Inform. 15(7), 4206–4215 (2019). https://doi.org/10.1109/TII.2019.2912465
Li, E., Zeng, L., Zhou, Z., Chen, X.: Edge ai: on-demand accelerating deep neural network inference via edge computing. IEEE Trans. Wirel. Commun. 19(1), 447–457 (2020). https://doi.org/10.1109/TWC.2019.2946140
Gacoin, V., Kolar, A., Ren, C., Guinvarc’h, R.: Distributing deep neural networks for maximising computing capabilities and power efficiency in swarm. (2019). https://doi.org/10.1109/ISCAS.2019.8702672
Acknowledgements
This work is supported by the National Natural Science Foundation of China (Grant Nos. 61702155, 61972128), the Natural Science Foundation of Anhui Province, China (Grant No. 1808085MF176), and the Fundamental Research Funds for the Central Universities, China (PA2021KCPY0050).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Zhang, G., Xu, B., Liu, E. et al. Task placement for crowd recognition in edge-cloud based urban intelligent video systems. Cluster Comput 25, 249–262 (2022). https://doi.org/10.1007/s10586-021-03392-3
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10586-021-03392-3