
Abstract
Over the last few decades, graphs have become increasingly important in many applications and domains for managing Big data. Big data analysis in a graph database is described as an analysis of exponentially increasing massive interconnected data concerning time. However, analyzing big connected data in social networks and synthetic identity detection is challenging. In previous approaches, fraud detection has been done on the complete graph data, which is a time-consuming process and will create bottlenecks while query execution. To overcome the issue, this paper proposes a new fraud detection technique to unveil synthetic identities involved in the Panama Paper leak dataset (unprecedented leak of 11.5 m data from the database of the world’s fourth-biggest offshore law arm, Mossack Fonseca) using a Node rank-based fraud detection algorithm by integrating distributed data profiling techniques on a minimized graph by minimizing the least influential nodes. The proposed model is verified on the three nodes cluster to improve data scalability, reduce the query execution time by an average of 30–36% and finally reduce the fraud detection time by 18.2%.













Similar content being viewed by others

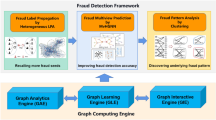

Data availability
Not applicable.
Code availability
Not applicable.
References
Basak, A., Li, S., Hu, X., Oh, S. M., Xie, X., Zhao, L., ..., Xie, Y.: Analysis and optimization of the memory hierarchy for graph processing workloads. In: 2019 IEEE International Symposium on High Performance Computer Architecture (HPCA), pp. 373–386. IEEE (2019)
Cattuto, C., Quaggiotto, M., Panisson, A., Averbuch, A.: Time-varying social networks in a graph database: a Neo4j use case. In: First international workshop on graph data management experiences and systems, pp. 1–6 (2013)
Chen, D.B., Gao, H., Lü, L., Zhou, T.: Identifying influential nodes in large-scale directed networks: the role of clustering. PloS one 8(10), (2013)
Drakopoulos, G., Gourgaris, P., Kanavos, A.: Graph communities in Neo4j. Evolving Systems 1–11 (2018)
Elyasi, N., Choi, C., Sivasubramaniam, A.: Large-scale graph processing on emerging storage devices. In: 17th USENIX Conference on File and Storage Technologies (FAST 19), pp. 309–316 (2019)
Gomez, L., Kuijpers, B., Vaisman, A.: Performing OLAP over graph data: query language, implementation, and a case study. In: Proceedings of the International Workshop on Real-Time Business Intelligence and Analytics, pp. 1–8 (2017)
Gubichev, A., Then, M.: Graph pattern matching: do we have to reinvent the wheel?. In: Proceedings of Workshop on GRAph Data management Experiences and Systems, pp. 1–7 (2014)
Harding, L.: What are the Panama Papers? A guide to history’s biggest data leak. The Guardian 5(04) (2016)
Holzschuher, F., Peinl, R.: Performance of graph query languages: comparison of cypher, gremlin and native access in Neo4j. In: Proceedings of the Joint EDBT/ICDT 2013 Workshops, pp. 195–204 (2013)
Huang, S.Y., Lin, C.C., Chiu, A.A., Yen, D.C.: Fraud detection using fraud triangle risk factors. Inf. Syst. Front. 19(6), 1343–1356 (2017)
Junghanns, M., Petermann, A., Neumann, M., Rahm, E.: Management and analysis of big graph data: current systems and open challenges. In: Handbook of Big Data Technologies, pp. 457–505. Springer, Cham (2017)
Liu, Q., Xiang, B., Yuan, N.J., Chen, E., Xiong, H., Zheng, Y., Yang, Y.: An influence propagation view of pagerank. ACM Trans. Knowl. Discov. Data (TKDD) 11(3), 1–30 (2017)
Liu, X., Tian, Y., He, Q., Lee, W.C., McPherson, J.: Distributed graph summarization. In: Proceedings of the 23rd ACM International Conference on Conference on Information and Knowledge Management, pp. 799–808 (2014)
Maduako, I., Cavalheri, E., Wachowicz, M.: Exploring the use of time-varying graphs for modelling transit networks (2018). arXiv preprint arXiv:1803.07610
Mahfoud, H.: Graph pattern matching with counting quantifiers and label-repetition constraints. Clust. Comput. 23(3), 1529–1553 (2020)
Maiolo, S., Etcheverry, L., Marotta, A.: Data profiling in property graph databases. J. Data Inform. Qual. (JDIQ) 12(4), 1–27 (2020)
Mathew, A.B.: Efficient query retrieval from social data in neo4j using lindex. KSII Trans. Internet Inform. Syst. (TIIS) 12(5), 2211–2232 (2018)
Neo4j Powers the Panama Papers Investigation (2019). https://Neo4j.com/news/Neo4j-powers Panama-papersinvestigation
Obermaier, F., Obermayer, B.: The Panama Papers: Breaking the story of how the rich and powerful hide their money. Simon and Schuster (2017)
O’Donovan, J., Wagner, H.F., Zeume, S.: The value of offshore secrets: Evidence from the Panama Papers. The Review of Financial Studies 32(11), 4117–4155 (2019)
Pourhabibi, T., Ong, K.L., Kam, B.H., Boo, Y.L.: Fraud detection: a systematic literature review of graph-based anomaly detection approaches. Decis. Support Syst. 133, 113303 (2020)
Qiu, L., Zhang, J., Tian, X.: Ranking influential nodes in complex networks based on local and global structures. Appl. Intell. 14, 1–14 (2021)
Roumelis, G., Velentzas, P., Vassilakopoulos, M., Corral, A., Fevgas, A., Manolopoulos, Y.: Parallel processing of spatial batch-queries using xBR+-trees in solid-state drives. Clust. Comput. 23(3), 1555–1575 (2020)
Sarma, D., Alam, W., Saha, I., Alam, M.N., Alam, M.J., Hossain, S.: Bank fraud detection using community detection algorithm. In: 2020 Second International Conference on Inventive Research in Computing Applications (ICIRCA), pp. 642–646. IEEE (2020)
Sarstedt, M., Mooi, E.: A concise guide to market research. Process, Data, and, 12 (2014)
Shakya, S.: IoT based F-RAN architecture using cloud and edge detection system. J. ISMAC 3(01), 31–39 (2021)
Spyropoulos, V., Vasilakopoulou, C., Kotidis, Y.: Digree: A middleware for a graph databases polystore. In: 2016 IEEE International Conference on Big Data (Big Data), pp. 2580–2589. IEEE (2016)
Srivastava, S., Singh, A.K.: Graph based analysis of panama papers. In: 2018 Fifth International Conference on Parallel, Distributed and Grid Computing (PDGC), pp. 822–827. IEEE (2018)
Szárnyas, G.: Incremental view maintenance for property graph queries. In: Proceedings of the 2018 International Conference on Management of Data, pp. 1843–1845 (2018)
Tanase, G., Suzumura, T., Lee, J., Chen, C. F., Crawford, J., Kanezashi, H., ..., Vijitbenjaronk, W.D.: System G distributed graph database (2018). arXiv preprint arXiv:1802.03057
The five most important Graphs from the Panama Papers leaks (2019). https://qz.com/654027/the-five-most-important-graphs-from-these-.panama-papers-leaks
van Rest, O., Hong, S., Kim, J., Meng, X., Chafi, H.: PGQL: a property graph query language. In: Proceedings of the Fourth International Workshop on Graph Data Management Experiences and Systems, pp. 1–6 (2016)
Webber, J., Robinson, I.: A Programmatic Introduction to Neo4j. Addison-Wesley Professional, Boston (2018)
What is the Secret Behind the Panama Papers? (2019). https://datafloq.com/read/panama-papers-its-all-about-the-data/2072
Yelmewad, P., Talawar, B.: Parallel deterministic local search heuristic for minimum latency problem. Clust. Comput. 24(2), 969–995 (2021)
Zhu, J., Tirumala, S.S., Babu, G.A.: A technical evaluation of Neo4j and elasticsearch for mining twitter data. In: International Conference on Advances in Computing and Data Sciences, pp. 359-369. Springer, Singapore (2018)
Funding
The authors would like to thank the Technical Education Quality Improvement Programme (TEQIP-III), to support the research.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
On behalf of all authors, the corresponding author states that there is no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Srivastava, S., Singh, A.K. Fraud detection in the distributed graph database. Cluster Comput 26, 515–537 (2023). https://doi.org/10.1007/s10586-022-03540-3
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10586-022-03540-3