
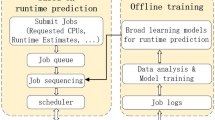
Abstract
Scheduling jobs for executing atop large-scale High-Performance Computing (HPC) infrastructures is a fundamental administrative challenge essential to maximize the productivity indicators of such complex Data Centers (DCs). Several policies were proposed by specialized literature, considering specific scenarios and applications, or proposing DC-tailored heuristics. However, the definition of the appropriate policy depends directly on the applications and infrastructure load, that is, indicators that vary over time. Given this context, this work advances the field on applying Machine Learning (ML) techniques to improve the existing scheduling policies. Specifically, we propose Knowledge-based Job Scheduler (KJS), which uses regression techniques to characterize the performance indicators of existing schedulers, composing a knowledge database, and instead of proposing a one-size-fits-all scheduling function, KJS consolidates the information and uses data classification for defining the jobs’ execution order. The simulation campaign demonstrates that KJS can adapt to different workloads when compared to the individual use of existing policies. Essentially, KJS combines polynomial data regression and classification for improving the performance indicators of HPC DC, in both the users’ and the administrators’ perspectives.







Similar content being viewed by others


Notes
PyBatSim available at: https://gitlab.inria.fr/batsim/pybatsim.
References
Dongarra, J., Luszczek, P.: TOP500. Boston, MA: Springer US, pp. 2055–2057. [Online]. Available: https://doi.org/10.1007/978-0-387-09766-4_157 (2011)
Reed, D., Gannon, D., Dongarra, J.: “Reinventing high performance computing: Challenges and opportunities,” (2022)
Abbasloo, S., Yen, C.-Y., Chao, H. J.: “Classic meets modern: a pragmatic learning-based congestion control for the internet,” in Proceedings of the Annual Conference of the ACM Special Interest Group on Data Communication on the Applications, Technologies, Architectures, and Protocols for Computer Communication, ser. SIGCOMM ’20. New York, NY, USA: Association for Computing Machinery, p. 632-647. [Online]. Available: https://doi.org/10.1145/3387514.3405892 (2020)
Yen, C.-Y., Abbasloo, S., Chao, H. J.: “Computers can learn from the heuristic designs and master internet congestion control,” in Proceedings of the ACM SIGCOMM 2023 Conference, ser. ACM SIGCOMM ’23. New York, NY, USA: Association for Computing Machinery, p. 255-274. [Online]. Available: https://doi.org/10.1145/3603269.3604838 (2023)
Carastan-Santos, D., de Camargo, R. Y.: “Obtaining dynamic scheduling policies with simulation and machine learning,” in Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, ser. SC ’17. New York, NY, USA: Association for Computing Machinery, (2017). [Online]. Available: https://doi.org/10.1145/3126908.3126955
Koslovski, G. P., Pereira, K., Albuquerque, P. R.: “Dag-based workflows scheduling using actor-critic deep reinforcement learning,” Future Generation Computer Systems, vol. 150, pp. 354–363, (2024). [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0167739X23003485
Li, J., Zhang, X., Wei, J., Ji, Z., Wei, Z.: “Garlsched: Generative adversarial deep reinforcement learning task scheduling optimization for large-scale high performance computing systems,” Future Generation Computer Systems, vol. 135, pp. 259–269, (2022). [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0167739X22001613
Yen, C.-Y., Abbasloo, S., Chao, H. J.: “Computers can learn from the heuristic designs and master internet congestion control,” in Proceedings of the ACM SIGCOMM 2023 Conference, (2023), pp. 255–274
Carastan-Santos, D., De Camargo, R.Y., Trystram, D., Zrigui, S.: “One can only gain by replacing easy backfilling: A simple scheduling policies case study,” in,: 19th IEEE/ACM International Symposium on Cluster. Cloud and Grid Computing (CCGRID) 2019, 1–10 (2019)
Blenk, A., Kalmbach, P., Kellerer, W., Schmid, S.: “O’zapft is: Tap your network algorithm’s big data!” in Proceedings of the Workshop on Big Data Analytics and Machine Learning for Data Communication Networks, (2017), pp. 19–24
Feitelson, D. G., Rudolph, L., Schwiegelshohn, U., Sevcik, K. C., Wong, P.: “Theory and practice in parallel job scheduling,” in Job Scheduling Strategies for Parallel Processing, D. G. Feitelson and L. Rudolph, Eds. Berlin, Heidelberg: Springer Berlin Heidelberg, pp. 8, 27 (1997)
Feitelson, D. G., Rudolph, L.: “Metrics and benchmarking for parallel job scheduling,” in Workshop on Job Scheduling Strategies for Parallel Processing. Springer, pp. 1–24 (1998)
Casagrande, L., Koslovski, G.,P. Miers, C.C., M.A., Gonzalez, N.: “Don’t hurry be green: scheduling servers shutdown in grid computing with deep reinforcement learning,” in International Journal of Grid and Utility Computing. Inderscience Publishers, (2022)
Liu, C.-L., Chang, C.-C., Tseng, C.-J.: Actor-critic deep reinforcement learning for solving job shop scheduling problems. IEEE Access 8, 71 752-71 762 (2020)
Feitelson, D.G., Tsafrir, D., Krakov, D.: Experience with using the parallel workloads archive. Journal of Parallel and Distributed Computing 74(10), 2967–2982 (2014)
Dutot, P.-F., Mercier, M., Poquet, M., Richard, O.: “Batsim: a realistic language-independent resources and jobs management systems simulator,” in Job Scheduling Strategies for Parallel Processing: 19th and 20th International Workshops, JSSPP: Hyderabad, India, May 26, 2015 and JSSPP 2016, Chicago, IL, USA, May 27, 2016, Revised Selected Papers 19. Springer 2017, 178–197 (2015)
Ontivero-Ortega, M., Lage-Castellanos, A., Valente, G., Goebel, R., Valdes-Sosa, M.: “Fast gaussian naïve bayes for searchlight classification analysis,” NeuroImage, vol. 163, pp. 471–479, (2017). [Online]. Available: https://www.sciencedirect.com/science/article/pii/S1053811917307371
Acknowledgements
This work was funded by the National Council for Scientific and Technological Development (CNPq), the Santa Catarina State Research and Innovation Support Foundation (FAPESC), Santa Catarina State University (UDESC), and developed at Laboratory of Parallel and Distributed Processing (LabP2D).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Diel, G., Nascimento Kraus, A.E. & Piêgas Koslovski, G. Knowledge-based job scheduling for HPC. Cluster Comput 28, 153 (2025). https://doi.org/10.1007/s10586-024-04734-7
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10586-024-04734-7