
Abstract
Along with COVID-19 ravaging almost 3 years, restricted working time and limited online working efficiency for the whole population results in social produced resource shortage sharpening. But how would the resource shortage affect the evolution of social population’s competition strategies? The concepts of involution, sit-up and lying-flat are put forward to describe such abnormal social competition phenomena and simulate individuals’ behaviour strategies, and a replicator dynamics game method with three strategies is proposed to solve the question. It is found that resource decrease and population increase result in involution degree relieving, while working time decreasing promotes involution. The increasing of sit-up cost and the utility of involution leads to severe involution, while the increase in involution cost will relieve involution. Moreover, it’s interesting to find that bad strategy drives out good when the resource becomes scarce. The robustness of results is tested by Derivative-free spectral approach, dual annealing and traversal method. The research sorts the evolution of involution concept and remaining qualitative & quantitative researches, and complements it from sit-up and lying-flat concept. The evolution of the three competition strategies is deduced from mathematics and proved by the simulation results. The research pays attention to the social involution concerns, in which the method and the results are meaningful to help give some insights for the deteriorative social competition. The R code and results can be reached at https://github.com/ZuoRX/replicator-dynamics/tree/main/codeA1.













Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Data availability
No empirical data were generated during the current study.
Code availability
The dynamic visualization R, python and matlab code for the simulation model, supplemental results, and dual annealing simulation results are available on the github. (https://github.com/ZuoRX/replicator-dynamics/tree/main/codeA1).
References
Alvarez-Rodriguez U, Battiston F, Arruda GF, Moreno Y, Perc M, Latora V (2021) Evolutionary dynamics of higher-order interactions in social networks. Nat Hum Behav 5(5):586–595. https://doi.org/10.1038/s41562-020-01024-1
Barrick MR, Mount MK, Li N (2013) The theory of purposeful work behavior: the role of personality, higher-order goals, and job characteristics. Acad Manage Rev 38(1):132–153. https://doi.org/10.5465/amr.2010.0479
Chan CK, Zhou Y, Wong KH (2019) An equilibrium model of the supply chain network under multi-attribute behaviors analysis. Eur J Oper Res 275(2):514–535. https://doi.org/10.1016/j.ejor.2018.11.068
He CC, Huang Q, Li XR, Zuo RX, Liu FZ, Wei YC, Wu J (2023) Involution-cooperation-lying flat game on a network-structured population in the group competition. IEEE Trans Comput Soc Syst.11(2): 2160-2178. https://doi.org/10.1016/j.ejor.2018.11.068
Chen X (2022) Choosing to "lying flat"? Two-way representation of employees under competition climate perception and job embedding. World Sci Res J 8(2):468–475. https://doi.org/10.6911/WSRJ.202202_8(2).0060
Chen W, Wu T, Li Z, Wang L (2019) Evolution of fairness in the mixture of the ultimatum game and the dictator game. Physica A 519:319–325. https://doi.org/10.1016/j.physa.2018.12.022
Cheng L, Liu G, Huang H, Wang X, Chen Y, Zhang J, Meng A, Yang R, Yu T (2020) Equilibrium analysis of general n-population multi-strategy games for generation-side long-term bidding: an evolutionary game perspective. J Clean Prod 276:124123. https://doi.org/10.1016/j.jclepro.2020.124123
Cheng C, Diao Y, Wang X, Zhou W (2024) Withdrawing from involution: the “lying flat’’ phenomenon of music teachers in China. Teach Teach Educ 147:10465. https://doi.org/10.1016/j.tate.2024.104651
Damanik EL (2020) Identity-based administrative involution in Indonesia: how political actors and community figures do it? SAGE Open 10(4). https://doi.org/10.1177/2158244020974015
Deci EL, Ryan RM (2000) The "what" and "why" of goal pursuits: human needs and the self-determination of behavior. Psychol Inq 11(4):227–268. https://doi.org/10.1207/S15327965PLI1104_01
Donie O’Sullivan CD (2022) Elon Musk gives ultimatum to Twitter employees: Do ’extremely hardcore’ work or get out. [EB/OL]. https://edition.cnn.com/2022/11/16/tech/elon-musk-email-ultimatum-twitter/index.html. Accessed 16 Nov 2022
Friedman D (1991) Evolutionary games in economics. Econometrica 59(3):637. https://doi.org/10.2307/2938222
Geertz C (1969) Agricultural involution: the processes of ecological change in Indonesia. University of California Press, Franklin St, Oakland. https://www.ucpress.edu/book/9780520004597/agricultural-involution. Accessed 16 Nov 2022
Goldenweiser A (1936) Loose ends of theory on the individual, pattern, and involution in primitive society. In: Essays in anthropology, pp 99–104. Berkeley: University of California Press.
Guerrieri V, Kondor P (2012) Fund managers, career concerns, and asset price volatility. Am Econ Rev 102(5):1986–2017. https://doi.org/10.1257/aer.102.5.1986
Harter J (2022) Is quiet quitting real? [EB/OL]. https://www.gallup.com/workplace/398306/quiet-quitting-real.aspx. Accessed 6 Sept 2022
Hauert C, Monte SD, Hofbauer J, Sigmund K (2002) Replicator dynamics for optional public good games. J Theor Biol 218(2):187–194. https://doi.org/10.1006/jtbi.2002.3067
Huang PCC (1990) The peasant family and rural development in the Yangzi delta, 1350–1988. Stanford University Press, Broadway St, Redwood City, CA. http://www.sup.org/books/title/?id=2761. Accessed 16 Nov 2022
Kang L, Jin Y (2020) A review of involution and its psychological interpretation. Filozofia Publiczna i Edukacja Demokratyczna 9(1):7–28. https://doi.org/10.14746/fped.2020.9.1.1
Li G, Song W (2022) The rise of think tanks as institutional involution in post-socialist China. China Rev 22(1):159–178. https://doi.org/10.2307/48653983
Li M, Kang H, Sun X, Shen Y, Chen Q (2022) Replicator dynamics of public goods game with tax-based punishment. Chaos Solitons Fractals 164:112747. https://doi.org/10.1016/j.chaos.2022.112747
Liu L, Chen X (2020) Evolutionary game dynamics in multiagent systems with prosocial and antisocial exclusion strategies. Knowl-Based Syst 188:104835. https://doi.org/10.1016/j.knosys.2019.07.006
Liu L, Chen X, Szolnoki A (2019) Evolutionary dynamics of cooperation in a population with probabilistic corrupt enforcers and violators. Math Models Methods Appl Sci 29(11):2127–2149. https://doi.org/10.1142/s0218202519500428
Loewenstein GF, Thompson L, Bazerman MH (1989) Social utility and decision making in interpersonal contexts. J Pers Soc Psychol 57(3):426–441. https://doi.org/10.1037/0022-3514.57.3.426
Luo R, Feng W, Xu Y (2022) Collective memory and social imaginaries of the epidemic situation in covid-19-based on the qualitative research of college students in wuhan, china. Front Psychol 13:998121. https://doi.org/10.3389/fpsyg.2022.998121
Luthi L, Tomassini M, Pestelacci E (2009) Evolutionary games on networks and payoff invariance under replicator dynamics. Biosystems 96(3):213–222. https://doi.org/10.1016/j.biosystems.2009.02.002
Ma X, Ma J, Li H, Jiang Q, Gao S (2016) RTRC: a reputation-based incentive game model for trustworthy crowdsourcing service. China Commun 13(12):199–215. https://doi.org/10.1109/cc.2016.7897544
Majek T, Hayter R (2008) Hybrid branch plants: Japanese lean production in Poland’s automobile industry. Econ Geogr 84(3):333–358. https://doi.org/10.1111/j.1944-8287.2008.tb00368.x
Mihara R (2018) Involution: a perspective for understanding Japanese animation’s domestic business in a global context. Jpn Forum 32(1):102–125. https://doi.org/10.1080/09555803.2018.1442362
Mirzaev I, Williamson DF, Scott JG (2018) egtplot: a python package for 3-strategy evolutionary games. J Open Source Sof 3(26):735. https://doi.org/10.1101/300004
Mulvey B, Wright E (2022) Global and local possible selves: differentiated strategies for positional competition among Chinese university students. Br Edu Res J 48(5):841–858. https://doi.org/10.1002/berj.3797
Nowak A, Rychwalska A, Borkowski W (2013) Why simulate? To develop a mental model. J Artif Soc Soc Simul.16(3), 12. https://doi.org/10.18564/jasss.2235
Perc M, Jordan JJ, Rand DG, Wang Z, Boccaletti S, Szolnoki A (2017) Statistical physics of human cooperation. Phys Rep 687:1–51. https://doi.org/10.1016/j.physrep.2017.05.004
Phelps S (2016) An empirical game-theoretic analysis of the dynamics of cooperation in small groups. J Artif Soc Soc Simul 19(2):4. https://doi.org/10.18564/jasss.3060
Roca CP, Cuesta JA, Sánchez A (2009) Evolutionary game theory: temporal and spatial effects beyond replicator dynamics. Phys Life Rev 6(4):208–249. https://doi.org/10.1016/j.plrev.2009.08.001
Santos MD, Pinheiro FL, Santos FC, Pacheco JM (2012) Dynamics of n-person snowdrift games in structured populations. J Theor Biol 315:81–86. https://doi.org/10.1016/j.jtbi.2012.09.001
Sasaki T, Unemi T (2011) Replicator dynamics in public goods games with reward funds. J Theor Biol 287:109–114. https://doi.org/10.1016/j.jtbi.2011.07.026
Sasaki T, Uchida S, Chen X (2015) Voluntary rewards mediate the evolution of pool punishment for maintaining public goods in large populations. Sci Rep. 5(1), 8917. https://doi.org/10.1038/srep08917
Semasinghe P, Hossain E, Zhu K (2015) An evolutionary game for distributed resource allocation in self-organizing small cells. IEEE Trans Mob Comput 14(2):274–287. https://doi.org/10.1109/tmc.2014.2318700
Si J (2022) No other choices but involution: understanding Chinese young academics in the tenure track system. J High Educ Policy Manage. 45(1), 53-67. https://doi.org/10.1080/1360080x.2022.2115332
Solansky ST (2015) Self-determination and leader development. Manage Learn 46(5):618–635. https://doi.org/10.1177/1350507614549118
Szabó G, Tőke C (1998) Evolutionary prisoner’s dilemma game on a square lattice. Phys Rev E 58(1):69–73. https://doi.org/10.1103/physreve.58.69
Szolnoki A, Perc M (2017) Second-order free-riding on antisocial punishment restores the effectiveness of prosocial punishment. Phys Rev X. 7(4), 041027. https://doi.org/10.1103/physrevx.7.041027
Toupo DFP, Strogatz SH (2015) Nonlinear dynamics of the rock-paper-scissors game with mutations. Phys Rev E. 91(5), 052907. https://doi.org/10.1103/physreve.91.052907
Vega-Redondo F (2003) Economics and the theory of games. Cambridge University Press, Cambridge. https://doi.org/10.1017/CBO9780511753954
Vilone D, Robledo A, Sánchez A (2011) Chaos and unpredictability in evolutionary dynamics in discrete time. Phys Rev Lett. 107(3), 038101. https://doi.org/10.1103/physrevlett.107.038101
Wang Q, He N, Chen X (2018) Replicator dynamics for public goods game with resource allocation in large populations. Appl Math Comput 328:162–170. https://doi.org/10.1016/j.amc.2018.01.045
Wang C, Hui K (2021) Replicator dynamics for involution in an infinite well-mixed population. Phys Lett A 420:127759. https://doi.org/10.1016/j.physleta.2021.127759
Wang C, Szolnoki A (2022) Involution game with spatio-temporal heterogeneity of social resources. Appl Math Comput 430:127307. https://doi.org/10.1016/j.amc.2022.127307
Wang C, Huang C, Pan Q, He M (2022) Modeling the social dilemma of involution on a square lattice. Chaos Solitons Fractals 158:112092. https://doi.org/10.1016/j.chaos.2022.112092
Wikipedia (2021) 996 working hour system. [EB/OL]. https://en.wikipedia.org/wiki/996_working_hour_system. Accessed 23 Nov 2022
Wu Y, Chang S, Zhang Z, Deng Z (2017) Impact of social reward on the evolution of the cooperation behavior in complex networks. Sci Rep. 7(1), 41076. https://doi.org/10.1038/srep41076
Xie L, Luan TH, Su Z, Xu Q, Chen N (2022) A game-theoretical approach for secure crowdsourcing-based indoor navigation system with reputation mechanism. IEEE Internet Things J 9(7):5524–5536. https://doi.org/10.1109/jiot.2021.3111999
Yan D, Zhang H, Guo S, Zeng W (2022) Influence of anxiety on university students’ academic involution behavior during COVID-19 pandemic: mediating effect of cognitive closure needs. Front Psychol. 13, 1005708. https://doi.org/10.3389/fpsyg.2022.1005708
Yi D, Wu J, Zhang M, Zeng Q, Wang J, Liang J, Cai Y (2022) Does involution cause anxiety? an empirical study from Chinese universities. Int J Environ Res Public Health 19(16):9826. https://doi.org/10.3390/ijerph19169826
Yin J, Ji Y, Ni Y (2023) Does “Nei Juan’’ affect “Tang Ping’’ for hotel employees? the moderating effect of effort-reward imbalance. Int J Hosp Manage 109:103421. https://doi.org/10.1016/j.ijhm.2022.103421
Zhang X-J, Tang Y, Xiong J, Wang W-J, Zhang Y-C (2020) Ranking game on networks: the evolution of hierarchical society. Physica A 540:123140. https://doi.org/10.1016/j.physa.2019.123140
Acknowledgement
This research is funded by Key Project of National Natural Science Foundation of China(72232006), National Natural Science Foundation of China (72204189), China Association for Science and Technology Graduate Students' Science Popularization Ability Improvement Project (KXYJS2024016), and Guangdong Basic and Applied Basic Research Foundation (2022A1515110972).
Author information
Authors and Affiliations
Corresponding authors
Ethics declarations
Conflict of interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix A The variants of replicator dynamics with three strategies
A denominator \({\bar{P}}\) added into Eq. (6) would not affect the final equilibrium result. When \({\bar{P}}=0\), the denominator is nonsense and is therefore abandoned.
A denominator \({\log (M + 1)}\) added into Eq. (6) would also not affect the final equilibrium result. But the influence of huge resource to relative payoffs can be controlled and the visualization in experimental part can be more vivid. While for simple rule, it is also not adopted.
Appendix B Transform replicator dynamics with three strategies into two strategies
1.1 Remove sit-up strategy
The proposed replicator dynamics with three strategies model is compatible to two strategies. When sit-up strategy is abandoned, \({z_C}{\mathrm{= }}1 - {x_L} - {y_{\textrm{D}}}{\mathrm{= }}0\) and \({{\textrm{N}}_{\textrm{C}}} = 0\). Even if \(c \ne 0,{\beta _C} \ne 0\), the model is robust.
Therefore, the payoff of an individual with \(N_D\) involution individuals, \(N_C=0\) sit-up individuals and \(N_L\) lying-flat individuals in current status is calculated by Eq. (B3).
The probabilities of selecting \(N_D\), \(N_C=N-N_L-N_D\), and \(N_L\) individuals with high, medium, and low effort are therefore:
The payoff expected value of three strategies, respectively \(P_D\), \(P_C\), and \(P_L\) with all possible \(N_D\)s and \(N_L\)s is thus calculated by Eq. (B5).
The average payoff of three strategies for the whole individuals then follows Eq. (B6).
And an individual’s payoff expectation value can also be calculated as:
As a result, the equilibrium values of the three strategies without sit-up strategy are
1.2 Remove involution strategy
When sit-up strategy is abandoned, \({y_{\textrm{D}}}{\mathrm{= }}0\) and \({{\textrm{N}}_{\textrm{D}}} = 0\). Even if \(d \ne 0,{\beta _D} \ne 0\), the model is robust.
Therefore, the payoff of an individual with \(N_D=0\) involution individuals, \(N_C\) sit-up individuals and \(N_L\) lying-flat individuals in current status is calculated by Eq. (B9).
The probabilities of selecting \(N_D=0\), \(N_C=N-N_L-N_D\), and \(N_L\) individuals with high, medium, and low effort are therefore:
The payoff expected value of three strategies, respectively \(P_D\),\(P_C\), and \(P_L\) with all possible \(N_D=0\) and \(N_L\)s is thus calculated by Eq. (B11).
The average payoff of three strategies for the whole individuals then follows Eq. (B12).
And an individual’s payoff expectation value can also be calculated as:
As a result, the equilibrium values for the three strategies without involution strategy are
1.3 Remove lying-flat strategy
When lying-flat strategy is abandoned, \({x_L}{\mathrm{= }}0\) and \({{\textrm{N}}_{\textrm{L}}} = 0\). Even if \(l \ne 0\), the model is robust.
Therefore, the payoff of an individual with \(N_D\) involution individuals, \(N_C\) sit-up individuals and \(N_L=0\) lying-flat individuals in current status is calculated by Eq. (B15).
The relative utility of involution compared to sit-up is therefore \(\beta = \frac{{{\beta _D}}}{{{\beta _C}}}\), and \({{\beta _C}} \ne 1\) do not affect the result.
The probabilities of selecting \(N_D\), \(N_C=N-N_L-N_D\), and \(N_L\) individuals with high, medium, and low effort are therefore:
The payoff expected value of three strategies, respectively \(P_D\),\(P_C\), and \(P_L\) with all possible \(N_D\)s and \(N_L\)s is thus calculated by Eq. (B17).
The average payoff of three strategies for the whole individuals then follows Eq. (B18).
And an individual’s payoff expectation value can also be calculated as:
As a result, the equilibrium values for the three strategies without sit-up strategy are
Appendix C Scenario of involution utility declining
In reality, the utility of high effort is relative to the population who chooses the same strategy. Namely, the utility is relatively large when just a few individuals choose such strategy. However, given all staff in the department are working overtime and do not rest in the weekends, the possible utility of high effort, e.g., leader’s recognition or post promotion for example, can decrease to a very limited value.
Logistic function has been widely used to simulate population increasing with S shape curve. And Sigmoid function is a common format.
This equation is the best mathematical model to describe the population growth law under the condition of limited resources. In the context of economic downturn, external resource is becoming very limited. The model is therefore suited to modeling the growth of the population who adopted high effort strategy.
In this experimental design, its variant is used to depict that the utility of an individual decreases with population increasing. Equation (C22) models the trend of high effort strategy community’s utility.
where \({{\beta _C}< {{\beta '}_D} < {\beta _D}}\). k is a parameter to adjust the curve degree and is set to 10 as default. And 1/2 is set to depict the utility value of the middle state when \(N_C = \frac{1}{2}N\). \({\beta '}_D\) is close to \(\beta _D\) when \(N_D\) is close to 0, and close to \(\beta _C\) when \(N_C\) is close to N.
Equation (C23) models the trend of middle effort strategy community’s utility. And \({1< {{\beta '}_C} < {\beta _C}}\). \(\beta '_C\) is close to \(\beta _C\) when \(N_C\) is close to 0, and close to 1, or the relative utility of lying-flat, when \(N_C\) is close to N.
Then the equilibrium value of the three strategies also follow Eqs. (1–6).
Appendix D Python-based implementation
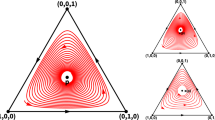
Another approach is adopted to further verify the result of the experiment. Instead of an infinite population, the game takes place among just three individuals. Figure 14 is done using a python package Egtplot (Mirzaev et al. 2018).

The phase diagram for three strategies in three individuals. Given the default parameters of \(M=10\), \(\beta _D=1.5\), \(\beta _C=1.1\), \(d=4\), \(c=1\) and \(l=0.5\), the proportion of each strategy stabilizes at \(x_D=1\), with \(x_C=1\) as a saddle point
Except from the plot above, other sets of parameters are explored, and the proportion always stabilizes around \(x_D=1\), \(x_C=1\) or \(x_L=1\). Namely, three strategies stabilize into two.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Zuo, R., He, C., Wu, J. et al. Simulating the impact of social resource shortages on involution competition: involution, sit-up, and lying-flat strategies. Comput Math Organ Theory 31, 27–62 (2025). https://doi.org/10.1007/s10588-025-09398-1
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10588-025-09398-1