
Abstract
Many real-world applications can usually be modeled as convex quadratic problems. In the present paper, we want to tackle a specific class of quadratic programs having a dense Hessian matrix and a structured feasible set. We hence carefully analyze a simplicial decomposition like algorithmic framework that handles those problems in an effective way. We introduce a new master solver, called Adaptive Conjugate Direction Method, and embed it in our framework. We also analyze the interaction of some techniques for speeding up the solution of the pricing problem. We report extensive numerical experiments based on a benchmark of almost 1400 instances from specific and generic quadratic problems. We show the efficiency and robustness of the method when compared to a commercial solver (Cplex).





Similar content being viewed by others


Notes
Code is available upon request.
References
Beasley, J.E.: Portfolio optimization data. http://people.brunel.ac.uk/~mastjjb/jeb/orlib/files/ (2016)
Bertsekas, D.P.: Convex Optimization Algorithms. Athena Scientific, Belmont (2015)
Bertsekas, D.P., Yu, H.: A unifying polyhedral approximation framework for convex optimization. SIAM J. Optim. 21(1), 333–360 (2011)
Birgin, E.G., Martínez, J.M., Raydan, M.: Nonmonotone spectral projected gradient methods on convex sets. SIAM J. Optim. 10(4), 1196–1211 (2000)
Boyd, S., Vandenberghe, L.: Convex Optimization. Cambridge University Press, Cambridge (2004)
Buchheim, C., Traversi, E.: Quadratic combinatorial optimization using separable underestimators. INFORMS J. Comput. 30(3), 424–437 (2018)
Cesarone, F., Tardella, F.: Portfolio datasets. http://host.uniroma3.it/docenti/cesarone/datasetsw3_tardella.html (2010)
Chen, S.S., Donoho, D.L., Saunders, M.A.: Atomic decomposition by basis pursuit. SIAM Rev. 43(1), 129–159 (2001)
Chu, P.C., Beasley, J.E.: A genetic algorithm for the multidimensional knapsack problem. J. Heuristics 4(1), 63–86 (1998)
Clarkson, K.L.: Coresets, sparse greedy approximation, and the Frank-Wolfe algorithm. ACM Trans. Algorithms (TALG) 6(4), 63 (2010)
Condat, L.: Fast projection onto the simplex and the l1-ball. Math. Program. 158(1), 575–585 (2016)
Cristofari, A.: An almost cyclic 2-coordinate descent method for singly linearly constrained problems. Comput. Optim. Appl. 73(2), 411–452 (2019)
Cristofari, A., De Santis, M., Lucidi, S., Rinaldi, F.: A two-stage active-set algorithm for bound-constrained optimization. J. Optim. Theory Appl. 172(2), 369–401 (2017)
Curtis, F.E., Han, Z., Robinson, D.P.: A globally convergent primal-dual active-set framework for large-scale convex quadratic optimization. Comput. Optim. Appl. 60(2), 311–341 (2015)
De Santis, M., Di Pillo, G., Lucidi, S.: An active set feasible method for large-scale minimization problems with bound constraints. Comput. Optim. Appl. 53(2), 395–423 (2012)
Demetrescu, C., Goldberg, A.V., Johnson, D.S.: The Shortest Path Problem: Ninth DIMACS Implementation Challenge, vol. 74. American Mathematical Soc., Providence (2009)
Desaulniers, G., Desrosiers, J., Solomon, M.M.: Column Generation, vol. 5. Springer, Berlin (2006)
Djerdjour, M., Mathur, K., Salkin, H.: A surrogate relaxation based algorithm for a general quadratic multi-dimensional knapsack problem. Oper. Res. Lett. 7(5), 253–258 (1988)
Dolan, E.D., Moré, J.J.: Benchmarking optimization software with performance profiles. Math. Program. 91(2), 201–213 (2002)
Drake, J.: Benchmark instances for the multidimensional knapsack problem (2015)
Elzinga, J., Moore, T.G.: A central cutting plane algorithm for the convex programming problem. Math. Program. 8(1), 134–145 (1975)
Ferreau, H.J., Kirches, C., Potschka, A., Bock, H.G., Diehl, M.: qpoases: a parametric active-set algorithm for quadratic programming. Math. Program. Comput. 6(4), 327–363 (2014)
Furini, F., Traversi, E., Belotti, P., Frangioni, A., Gleixner, A., Gould, N., Liberti, L., Lodi, A., Misener, R., Mittelmann, H., Sahinidis, N., Vigerske, S., Wiegele, A.: Qplib: a library of quadratic programming instances. Math. Program. Comput. 11, 237–265 (2018)
Glover, F., Kochenberger, G.: Critical event tabu search for multidimensional knapsack problems. In: Meta-Heuristics, pp. 407–427. Springer (1996)
Glover, F., Kochenberger, G., Alidaee, B., Amini, M.: Solving quadratic knapsack problems by reformulation and tabu search: single constraint case. In: Combinatorial and Global Optimization, pp. 111–121. World Scientific (2002)
Goffin, J.L., Gondzio, J., Sarkissian, R., Vial, J.P.: Solving nonlinear multicommodity flow problems by the analytic center cutting plane method. Math. Program. 76(1), 131–154 (1997)
Goffin, J.L., Vial, J.P.: Cutting planes and column generation techniques with the projective algorithm. J. Optim. Theory Appl. 65(3), 409–429 (1990)
Goffin, J.L., Vial, J.P.: On the computation of weighted analytic centers and dual ellipsoids with the projective algorithm. Math. Program. 60(1), 81–92 (1993)
Gondzio, J.: Interior point methods 25 years later. Eur. J. Oper. Res. 218(3), 587–601 (2012)
Gondzio, J., González-Brevis, P.: A new warmstarting strategy for the primal-dual column generation method. Math. Program. 152(1–2), 113–146 (2015)
Gondzio, J., González-Brevis, P., Munari, P.: New developments in the primal-dual column generation technique. Eur. J. Oper. Res. 224(1), 41–51 (2013)
Gondzio, J., González-Brevis, P., Munari, P.: Large-scale optimization with the primal–dual column generation method. Math. Program. Comput. 8(1), 47–82 (2016)
Gondzio, J., Kouwenberg, R.: High-performance computing for asset-liability management. Oper. Res. 49(6), 879–891 (2001)
Gondzio, J., du Merle, O., Sarkissian, R., Vial, J.P.: Accpm—a library for convex optimization based on an analytic center cutting plane method. Eur. J. Oper. Res. 94(1), 206–211 (1996)
Gondzio, J., Sarkissian, R., Vial, J.P.: Using an interior point method for the master problem in a decomposition approach. Eur. J. Oper. Res. 101(3), 577–587 (1997)
Gondzio, J., Vial, J.P., et al.: Warm start and -subgradients in a cutting plane scheme for block-angular linear programs. Comput. Optim. Appl. 14, 17–36 (1999)
Grippo, L., Lampariello, F., Lucidi, S.: A nonmonotone line search technique for newton’s method. SIAM J. Numer. Anal. 23(4), 707–716 (1986)
Grippo, L., Lampariello, F., Lucidi, S.: A truncated newton method with nonmonotone line search for unconstrained optimization. J. Optim. Theory Appl. 60(3), 401–419 (1989)
Grippo, L., Lampariello, F., Lucidi, S.: A class of nonmonotone stabilization methods in unconstrained optimization. Numer. Math. 59(1), 779–805 (1991)
Hager, W.W., Zhang, H.: A new active set algorithm for box constrained optimization. SIAM J. Optim. 17(2), 526–557 (2006)
Hearn, D.W., Lawphongpanich, S., Ventura, J.A.: Restricted simplicial decomposition: computation and extensions. In: Computation Mathematical Programming, pp. 99–118 (1987)
Holloway, C.A.: An extension of the Frank and Wolfe method of feasible directions. Math. Program. 6(1), 14–27 (1974)
IBM: Cplex (version 12.6.3). https://www-01.ibm.com/software/commerce/optimization/cplex-optimizer/ (2015)
Kiwiel, K.C.: Methods of Descent for Nondifferentiable Optimization, vol. 1133. Springer, Berlin (2006)
Levin, A.Y.: On an algorithm for the minimization of convex functions. Sov. Math. Dokl. 160, 1244–1247 (1965)
Markowitz, H.: Portfolio selection. J. Finance 7(1), 77–91 (1952)
Michelot, C.: A finite algorithm for finding the projection of a point onto the canonical simplex of \({\mathbb{R}}^n\). J. Optim. Theory Appl. 50(1), 195–200 (1986)
Munari, P., Gondzio, J.: Using the primal–dual interior point algorithm within the branch-price-and-cut method. Comput. Oper. Res. 40(8), 2026–2036 (2013)
Nesterov, Y., Nemirovskii, A.: Interior-Point Polynomial Algorithms in Convex Programming. SIAM, Philadelphia (1994)
Newman, D.J.: Location of the maximum on unimodal surfaces. J. ACM (JACM) 12(3), 395–398 (1965)
Nocedal, J., Wright, S.J.: Conjugate gradient methods. In: Numerical Optimization, pp. 101–134 (2006)
Nocedal, J., Wright, S.J.: Sequential Quadratic Programming. Springer, Berlin (2006)
Palomar, D.P., Eldar, Y.C.: Convex Optimization in Signal Processing and Communications. Cambridge University Press, Cambridge (2010)
Patriksson, M.: The Traffic Assignment Problem: Models and Methods. Courier Dover Publications, Mineola (2015)
Rostami, B., Chassein, A., Hopf, M., Frey, D., Buchheim, C., Malucelli, F., Goerigk, M.: The quadratic shortest path problem: complexity, approximability, and solution methods. Eur. J. Oper. Res. 268(2), 473–485 (2018)
Rostami, B., Malucelli, F., Frey, D., Buchheim, C.: On the quadratic shortest path problem. In: International Symposium on Experimental Algorithms, pp. 379–390. Springer (2015)
Syam, S.S.: A dual ascent method for the portfolio selection problem with multiple constraints and linked proposals. Eur. J. Oper. Res. 108(1), 196–207 (1998)
Tarasov, S., Khachiian, L., Erlikh, I.: The method of inscribed ellipsoids. Dokl. Akad. Nauk SSSR 298(5), 1081–1085 (1988)
Tibshirani, R.: Regression shrinkage and selection via the lasso. J. R. Stat. Soc. Ser. B (Methodol.) 58(1), 267–288 (1996)
Ventura, J.A., Hearn, D.W.: Restricted simplicial decomposition for convex constrained problems. Math. Program. 59(1), 71–85 (1993)
Von Hohenbalken, B.: Simplicial decomposition in nonlinear programming algorithms. Math. Program. 13(1), 49–68 (1977)
WolframAlpha: Mathematica (version 11.3). http://www.wolfram.com/mathematica/ (2018)
Wright, M.: The interior-point revolution in optimization: history, recent developments, and lasting consequences. Bull. Am. Math. Soc. 42(1), 39–56 (2005)
Wright, S.J.: Primal–Dual Interior-Point Methods. SIAM, Philadelphia (1997)
Ye, Y.: Interior Point Algorithms: Theory and Analysis, vol. 44. Wiley, Hoboken (2011)
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendices
1.1 Proofs of the propositions in Sect. 3
1.1.1 Proof of Proposition 5
Proof
Extreme point \({{\tilde{x}}}_k\), obtained approximately solving subproblem (2), can only satisfy one of the following conditions
- 1.
\(\nabla f(x_k)^{\top }({{\tilde{x}}}_k-x_k)\ge 0\), and subproblem (2) is solved to optimality. Hence we get
$$\begin{aligned} \min _{x \in X} \nabla f(x_k)^{\top }(x-x_k)= \nabla f(x_k)^{\top }({{\tilde{x}}}_k-x_k)\ge 0, \end{aligned}$$that is necessary and sufficient optimality conditions are satisfied and \(x_k\) minimizes f over the feasible set X;
- 2.
\(\nabla f(x_k)^{\top }({{\tilde{x}}}_k-x_k)<0,\) whether the pricing problem is solved to optimality or not, that is direction \(d_k={{\tilde{x}}}_k-x_k\) is descent direction and
$$\begin{aligned} {{\tilde{x}}}_k\notin conv(X_k). \end{aligned}$$(13)Indeed, since \(x_k\) minimizes f over \(conv(X_k)\) it satisfies necessary and sufficient optimality conditions, that is \(\nabla f(x_k)^{\top }(x-x_k)\ge 0\) for all \(x \in conv(X_k)\).
From (13) we thus have \({{\tilde{x}}}_k \notin X_k\). Since our feasible set X has a finite number of extreme points, case 2) occurs only a finite number of times, and case 1) will eventually occur. \(\square \)
1.1.2 Proof of Proposition 6
Proof
We first show that at each iteration the method gets a reduction of f when suitable conditions are satisfied. Since at Step 2 we get an extreme point \({{\tilde{x}}}_k\) by solving subproblem (11), if \(\nabla f(x_k)^{\top }({{\tilde{x}}}_k-x_k) <0\), we have that \(d_k={{\tilde{x}}}_k-x_k\) is a descent direction and there exists an \(\alpha _k\in (0,1]\) such that \(f(x_k+\alpha _kd_k)<f(x_k)\). Since at iteration \(k+1\), when solving the master problem, we minimize f over the set \(conv(X_{k+1})\) (including both \(x_k\) and \({{\tilde{x}}}_k\)), then the minimizer \(x_{k+1}\) must be such that
Extreme point \({{\tilde{x}}}_k\), obtained solving subproblem (11), can only satisfy one of the following conditions
- 1.
\(\nabla f(x_k)^{\top }({{\tilde{x}}}_k-x_k)\ge 0\). Hence we get
$$\begin{aligned} \min _{x \in X \cap C_k} \nabla f(x_k)^{\top }(x-x_k)= \nabla f(x_k)^{\top }({{\tilde{x}}}_k-x_k)\ge 0, \end{aligned}$$that is necessary and sufficient optimality conditions are satisfied and \(x_k\) minimizes f over the feasible set \(X \cap C_k\). Furthermore, if \(x \in X\setminus C_k\), we get that there exists a cut \(c_i\) with \(i \in \{0,\dots ,k-1\}\) such that
$$\begin{aligned} \nabla f(x_i)^{\top }(x-x_i)>0. \end{aligned}$$Then, by convexity of f, we get
$$\begin{aligned} f(x)\ge f(x_i)+\nabla f(x_i)^{\top }(x-x_i)>f(x_i)>f(x_k) \end{aligned}$$so \(x_k\) minimizes f over X.
- 2.
\(\nabla f(x_k)^{\top }({{\tilde{x}}}_k-x_k)<0\), that is direction \(d_k={{\tilde{x}}}_k-x_k\) is descent direction and
$$\begin{aligned} {{\tilde{x}}}_k\notin conv(X_k). \end{aligned}$$(14)Indeed, since \(x_k\) minimizes f over \(conv(X_k)\) it satisfies necessary and sufficient optimality conditions, that is we have \(\nabla f(x_k)^{\top }(x-x_k)\ge 0\) for all \(x~\in ~conv(X_k)\).
Since from a certain iteration \({{\bar{k}}}\) on we do not add any further cut (notice that we can actually reduce cuts by removing the non-active ones), then case 2) occurs only a finite number of times. Thus case 1) will eventually occur. \(\square \)
1.2 Preliminary tests
In this section, we describe the way we chose the Cplex optimizer for solving our convex quadratic instances. Then, we explain how we set the parameters in the different algorithms used to solve the master problem in the SD framework.
1.2.1 Choice of the Cplex optimizer
As already mentioned, we decided to benchmark our algorithm against Cplex. The aim of our first test was to identify, among the seven different options for the QP solver, the most efficient in solving instances with a dense Q and \(n \gg m\).
In Table 2, we present the results concerning instances with 42 constraints and three different dimensions n: 2000, 4000 and 6000. We chose problems with a small number of constraints in order to be sure to pick the best Cplex optimizer for those problems where the SD framework is supposed to give very good performances. For a fixed n, three different instances were solved of all six problem types. So, each entry of Table 2 represents the averages computing times over 18 instances. A time limit of 1000 seconds was imposed and in parenthesis we report (if any) the number of instances that reached the time limit.
The table clearly shows that the default optimizer, the barrier and the concurrent methods give poor performances when dealing with the quadratic programs we previously described. On the other side, the simplex type algorithms and the sifting algorithm seem to be very fast for those instances. In particular, sifting gives the overall best performance. Taking into account these results, we decided to use the Cplex sifting optimizer as the baseline method in our experiments. It is worth noting that the sifting algorithm is specifically conceived by Cplex to deal with problems with \(n \gg m\), representing an additional reason for comparing our algorithmic framework against this specific Cplex optimizer. When dealing with Quadratic Shortest Path problems, we used the quadratic Network optimizer, more suited for this type of problems.
1.2.2 Tolerance setting when solving the master problem
We have three options available for solving the master problem in the SD framework: ACDM, FGPM and Cplex. In order to identify the best choice, we need to properly set tolerances for those methods. When using Cplex as the master solver, we decided to keep the tolerance to its default value (that is 1E10−6). The peculiar aspect of ACDM is that no tolerance needs to be fixed a priori. On the other hand, with FGPM, the tolerance setting phase is very important since, as we will see, it can significantly affect the performance of the algorithm in the end.
In Table 3, we compare the different behaviours of our SD framework for the three different choices of master solver. Each line of the table represents the average values concerning the 54 instances used in the previous experiment. Column “T” represents the time (in seconds) spent by the algorithms. “Er” and “Max Er” represent the average and maximum relative errors with respect to the value found by Cplex (using sifting optimizer). “Ei” and “Max Ei” represent the average and maximum distance (calculated using \(\ell _{\infty }\) norm) from the solution found by Cplex. In the last column, “Dim” represents the dimension of the final master program.
From this table, one can observe that the ACDM based SD framework gets the best results in terms of errors with respect to Cplex. One can also see that the performance of the FGPM based one really changes depending on the tolerance chosen. If we want to get for FGPM the same errors as ACDM, we need to set the tolerance to very low values, thus considerably slowing down the algorithm. In the end, we decided to use a tolerance of 10E−6 for FGPM, which gives a good trade-off between computational time and accuracy. This means anyway that we need to give up precision to keep FGPM competitive in terms of time with respect to ACDM.
1.2.3 Choice of the \(\varepsilon \) parameter for the early stopping pricing option
In this section we discuss how to fix the threshold \(\varepsilon \) used in equation (9) for the Early Stopping option. We decided to fix the value of \(\varepsilon \) as a fraction \(\varepsilon _0\) of the quantity \(|\nabla f(x_k)^{\top } x_k|\):
The value of \(\varepsilon _0\) has been chosen after testing three different values on a subset of instances. We chose the subset of the randomly generated instances with random dense constraints and budget constraint, where SD has the worst behavior with respect to Cplex. The results are presented in Table 4, where we compare the average computational time T and the number of SD iterations N its. The table presents the results on the 67 instances solved by all the algorithms.
One can see that, with \(\varepsilon _0 = 0.5\) , the time and number of iterations are larger. On the other hand, if \(\varepsilon _0 = 1.5\), the threshold is too weak and the early stopping is never used. Hence, we chose the value of \(\varepsilon _0 = 1.0\), which improves the computational time while keeping the number of iterations unchanged.
1.3 Instances details
1.3.1 Generic quadratic instances
These are randomly generated quadratic programming instances. In particular, Q was built starting from its singular value decomposition using the following procedure:
the n eigenvalues were chosen in such a way that they are all positive and equally distributed in the interval \([10^{-4},3]\);
the \(n\times n\) diagonal matrix S, containing these eigenvalues in its diagonal, was constructed;
an orthogonal, \(n\times n\) matrix U was supplied by the QR factorization of a randomly generated \(n\times n\) square matrix;
finally, the desired matrix Q was given by \(Q=USU^{\top }\), so that it is symmetric and its eigenvalues are exactly the ones we chose.
The coefficients of the linear part of the objective function were randomly obtained in the interval [0.05, 0.4], in accordance with the quadratic terms and in order to make the solution of the problem quite sparse.
The m constraints (with \(m\ll n\)) were generated in two different ways: step-wise sparse constraints (S) or random dense ones (R). In the first case, for each constraint, the coefficients associated to short overlapping sequences of consecutive variables were set equal to 1 and the rest equal to 0. More specifically, if m is the number of constraints and n is the number of columns, we defined \(s=2*n/(m+1)\) and all the coefficients of each i-th constraint are zero except for a sequence of s consecutive ones, starting at the position \(1+(s/2)*(i-1)\). In the second case, each coefficient of the constraint matrix takes a uniformly generated random value in the interval [0, 1]. The right-hand side was generated in such a way to make all the problems feasible: for the step-wise constraints, the right hand side was set equal to \(f*s/n\), with \(0.4\le f\le 1\) and for a given random constraint, the corresponding right-hand side b was a convex combination of the minimum \(a_{min}\) and the maximum \(a_{max}\) of the coefficients related to the constraint itself, that is \(b=0.75*a_{min}+0.25*a_{max}\).
Each class of constraints was then possibly combined with two additional type of constraints: a budget type constraint (b) \(e^{\top }x =1\), and a “relaxed” budget type constraints (rb) \( slb \le e^{\top }x \le sub\). Summarizing, we obtained six different classes of instances:
S, instances with step-wise constraints only;
S-b, instances with both step-wise constraints and budget constraint;
S-rb, instances with both step-wise and relaxed budget constraints;
R, instances with dense random constraints only;
R-b, instances with both dense random constraints and budget constraint;
R-rb, instances with both dense random and relaxed budget constraints.
For each class, we fixed \(n=2000,3000,\dots ,10{,}000\), while the number of both step-wise and dense random constraints m was chosen in two different ways:
- (1)
\(m=2,\,22,\,42\) for each value of n;
- (2)
\(m = n/32\), n / 16, n / 8, n / 4, n / 2 for each value of n.
In the first case, we then have problems with a small number of constraints, while, in the second case, we have problems with a large number of constraints. Finally, for each class and combination of n and m we randomly generated five instances. Hence, the total number of instances with a small number of constraints was 450 and the total number of instances with a large number of constraints was 750.
1.3.2 Tests on instances with ill-conditioned and positive semidefinite Hessian matrices
In the paper, we presented results related to instances with positive definite Hessian having eigenvalues equally distributed in the range \([10^{-4},3]\) (i.e., with a condition number of \(3\times 10^4\)).
In here, we report results obtained when varying condition number and percentage of null eigenvalues in the Hessian matrix of the randomly generated QPs. More specifically, for each choice of condition number and percentage of null eigenvalues, we randomly generate 5 problems with 2000 variables and 5 problems with 4000 variables. We consider the following choices:
4 different percentages of null eigenvalues : \(0\%\), \(1\%\), \(5\%\), \(20\%\) ;
condition number of 5 different orders: \(10^4\), \(10^8\), \(10^{12}\), \(10^{16}\), \(10^{20}\).
Hence, we have 20 different combinations for a total number of 200 instances.
We notice that Cplex had a significant number of failures on those instances. Indeed, it was able to solve only the positive definite instances with condition number up to \(10^{12}\). It returned and error in the other cases: this is mainly due to the high density of the matrix that makes hard to detect the symmetry or the positive semidefiniteness of the Hessian.
SD ACDM was instead able to solve the vast majority of the instances (we only got a few failures for condition number \(10^{20}\)) and it was faster on those instances that Cplex was able to solve. In Table 5, the average CPU time in seconds is reported for SD ACDM (with the default pricing option). Each column represents the percentage of null eigenvalues and each row stands for the order of magnitude of each condition number considered. SD ACDM with the best pricing option, that for these instances is Sifting + Cuts, obtains similar results in terms of CPU time.
We would anyway like to remark that specific techniques, e.g. preconditioning strategies, can be used (and are actually used in many solvers) to tackle this class of problems. Some preconditioning might hence be embedded in our framework as well in order to improve the performance. This is surely an interesting point and might be subject of future research.
1.3.3 Chebyshev instances
We constructed our instances by randomly generating a matrix \(A\in {{\mathbb {R}}}^{m\times n}\) with normally distributed entries. The linear term is given by the euclidean norm of each column of A. We consider
\(n\in \{\)2048\(,\ \)4096\(,\ \)8192\(\}\);
\(m\in \{\)10\(,\ \)100\(,\ \)1000\(\}\).
For each combination, we generated three different problems, thus getting 27 instances in total.
1.3.4 LASSO instances
We constructed each instance by randomly generating a matrix \(A\in {{\mathbb {R}}}^{m\times n}\) with normally distributed entries. We chose:
\(n \in \{2048,\ 4096,\ 8192\}\),
\(m \in \{n/4, n\}\).
Then, we generated the solution point \({\bar{x}} \) with different percentages of nonzero components, that is 0.01, 0.05, and 0.1. We further set \(b=A{\bar{x}}+\varepsilon \), with a random noise \(\varepsilon \). For each combination we generated three different instances, thus getting a benchmark of 54 LASSO instances.
1.3.5 Portfolio instances
We used data based on time series provided in [1] and [7]. Those data are related to sets of assets of dimension \(n = \) 226, 457, 476, 2196. The expected return and the covariance matrix are calculated by the related estimators on the time series related to the values of the assets.
In order to analyze the behaviour of the algorithm on larger dimensional problems, we created additional instances using data series obtained by modifying the existing ones. More precisely, we considered the set of data with \(n=2196\), and we generated bigger series by adding additional values to the original ones: in order not to have a negligible correlation, we assumed that the additional data have random values close to those of the other assets. For each asset and for each time, we generate from 1 to 4 new values, thus obtaining 4 new instances whose dimensions are multiples of 2196 (that is 4392, 6588, 8784, 10980).
For each of these 8 instances, we chose 5 different thresholds for the expected return: 0.006, 0.007, 0.008, 0.009, 0.01, we thus obtained 40 portfolio optimization instances.
1.3.6 Quadratic multidimensional knapsack instances
The instances we used for the quadratic multidimensional knapsack problem are provided by J. Drake in [20]. This benchmark collects various instances, including the ORLib dataset proposed by Chu and Beasley in [9] and the GK dataset proposed by Glover and Kochenberger, mentioned in [24]. In particular, we considered only problems with n greater than 1000. Hence, we kept instances gk09, gk10 and gk11 of Glover and Kochenberger from [20], and we generated other instances using the same criteria described in [9], but using larger values of n, that is 5000, 7500 and 10000. We kept \(m = 100\) in this last case and we considered two different options to obtain the right hand side. So we generated 6 instances. As regards the objective function, the coefficients of the linear part were already included in the instances and we changed their signs in order to obtain minimization problems; for the quadratic part we used again matrices generated in the same way as for the general problems described before. In order to get meaningful results in the end, we suitably scaled the two terms in the objective function with a parameter \(\rho \). We used two different seeds to generate the matrix and three different values for \(\rho \). So, we have 6 combinations for the objective function for each of the 9 linear problems (the instances gk09, gk10 and gk11 from the literature and the 6 problems generated by us) so we have 54 instances globally.
1.3.7 Quadratic shortest path instances
The directed graphs used in the experiments are related to two different kind of problems:
- 1.
Grid shortest path problem, that is graphs represented by a squared grid;
- 2.
Random shortest path problem, that is randomly generated graphs (obtained by the generator ch9-1-1 used in the 9th DIMACS implementation challenge [16]).
For grid shortest path instances, we considered square grids of 5 different sizes k, that is \(k= 30, 40, 50, 60, 70\). We fixed the source and the sink respectively as the top-left and the bottom-right node. The number of variables n, same as the number of arcs, is \(2*k*(k-1)\). Hence we get, respectively: \(n= 1740, 3120, 4900, 7080 \) and 9660. The number of constraints is the same as the number of vertices of the graph, that is \(k^2\).
When generating random shortest path instances, we fixed three values of n: 1000, 3000 and 5000; the number of constraints m was chosen in order to get similar densities in the graphs: we respectively chose \(m=100\) and 150 for \(n=1000\), \(m=150\) and 250 for \(n=3000\) and \(m=200\) and 300 for \(n=5000\). In this way we obtained graphs with densities (number of arcs over number of arcs of a complete graph with the same number of nodes) that vary between \(10\%\) and \(25\%\).
For both classes, we built up the objective function in this way: we defined the quadratic part with matrices generated same way as for the general problems described before; then we added linear coefficients for the linear part, generated in three different intervals: [0.05, 0.4], [0.5, 1.0] and [2.0, 3.0]. We used two different seeds for generating the quadratic part and for the linear part we considered three different choices, so we have 6 problems for each value of n and m. In this way we obtained 30 different problems for the Grid shortest path, where m is fixed depending on n, while we got 72 instances of Random shortest path, because for each n we got 2 different values for m and for each of them we used two different seeds for generating the graph.
1.4 CPU time usage in the SD framework
Now we analyze the way CPU time is used in the SD framework, that is we show the average CPU time needed for preprocessing data, solving the master problems and solving the pricing problems with the best master and pricing settings. In Figures 6 and 7, we report the aggregated results over the first three classes of instances and on the continuous relaxations of combinatorial instances, respectively. In each figure, we report the time spent by SD in the preprocessing phase of the algorithm (preprocessing) and in the solution of the master and pricing problems. The solving time of both the pricing and master problems is split in the time needed to update the data structures (updating) and the time needed to solve the problem (solvers). Figure 6 clearly suggests that for generic instances the percentage of computing time of the pricing problem increases with the increase of the size of the instances. On the other hand, the subdivision of CPU times differs significantly for the three continuous relaxations of combinatorial instances considered (QGSPP, QRSPP, QMKP). First of all, we observe that for quadratic shortest path instances the percentage of computing time for the pricing is lower than the one for the quadratic multidimensional knapsack instances. This is due to the fact that the pricing problem for a quadratic shortest path instance reduces to a simple shortest path problem and thus it can be handled efficiently by the LP Network solver of Cplex. Finally, we notice that the percentage for the preprocessing time in random shortest path is high. This happens because the overall computing time is significantly small, hence the total time needed to prepare the initial data structures is not negligible.

CPU time pie charts for Portfolio and General Problems

CPU time pie charts (continuous relaxations of combinatorial instances)

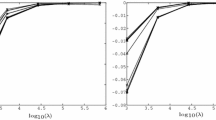
Objective function decay—Objective function ratio (y-axis) and CPU time ratio (x-axis)
1.5 In-depth analysis
In order to better analyze the behavior of the SD framework, we show now how the objective function value changes with respect to the elapsed time. Since we want to get meaningful results, we only consider generic instances solved in more than 10 seconds (but always within the time limit of 900 seconds). In particular, we consider instances with random dense constraints and we take a set of 25 instances for each of the three types of additional constraints (see “Appendix A.3.1”). Hence, we plot
on the x-axis the CPU time ratio, that is the CPU time elapsed divided by the overall time needed by Cplex to get a solution on the same instance.
on the y-axis the objective function ratio, that is the objective function value divided by the optimal value obtained by Cplex on the same instance.
All the results are averaged over the whole set of instances. For the SD framework, we plot the results up to twice the time needed by Cplex to get a solution. In the analysis, we always consider the setting that includes all the pricing options (and gives same performance as the best one). Figure 8a, b show the overall results for the 75 instances considered: the first figure shows the comparison between Cplex and SD FGPM, while the second one shows the comparison of the three different SD framework versions. From the comparison of Cplex and SD FGPM, it is easy to notice that SD gets a good objective function value very soon. Indeed, at a CPU time ratio 0.6 (i.e., \(60\%\) of the overall Cplex CPU time) corresponds an objective function ratio slightly bigger than 1 for SD FGPM, while at the same CPU time ratio Cplex still needs to find a feasible solution. Cplex gets a first feasible solution for a CPU time ratio equal to 0.7 (in this case the objective function ratio is bigger than 2.5), and it obtains an objective function ratio close to 1 only for a CPU time ratio bigger than 0.8. By taking a look at the comparison of the three different versions of our SD framework, we notice that SD FGPM actually takes longer than the others to get an objective function ratio close to 1. The better results obtained for SD FGPM hence depend, as we already noticed, on the way we choose the tolerance in the master solvers.
1.6 Embedding SD ACDM in a branch and bound scheme
Since the results seem to indicate that our algorithm is efficient for continuous problems, we tried to embed SD ACDM in a Branch and Bound scheme to solve mixed binary problems. Our first results are obtained with a depth first strategy, which requires less memory than any other branching strategy. As branching rule, we fixed the least fractional variable to the closest integer. We did not add any type of cuts in these experiments. We tested the algorithm on instances coming from the previous analysis: we used the 6 binary instances from the QPLIB library with a dense Hessian, then we used 6 instances of QGSPP, 6 of QRSPP and 12 instances of QMKP, generated as before but with a smaller size. We compared to Cplex with default options. The results are promising, even if we are aware that the code can be further improved. In Table 6, we report the computational time (in seconds) needed to solve the considered problems. If the algorithm does not solve the instance to optimality within the time limit of 2 hours, we have a failure and write TL (time limit) on the table.
Rights and permissions
About this article

Cite this article
Bettiol, E., Létocart, L., Rinaldi, F. et al. A conjugate direction based simplicial decomposition framework for solving a specific class of dense convex quadratic programs. Comput Optim Appl 75, 321–360 (2020). https://doi.org/10.1007/s10589-019-00151-4
Received:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10589-019-00151-4