
Abstract
Hardware accelerators such as GPUs or Intel Xeon Phi comprise hundreds or thousands of cores on a single chip and promise to deliver high performance. They are widely used to boost the performance of highly parallel applications. However, because of their diverging architectures programmers are facing diverging programming paradigms. Programmers also have to deal with low-level concepts of parallel programming that make it a cumbersome task. In order to assist programmers in developing parallel applications Algorithmic Skeletons have been proposed. They encapsulate well-defined, frequently recurring parallel programming patterns, thereby shielding programmers from low-level aspects of parallel programming. The main contribution of this paper is a comparison of two skeleton library implementations, one in C++ and one in Java, in terms of library design and programmability. Besides, on the basis of four benchmark applications we evaluate the performance of the presented implementations on two test systems, a GPU cluster and a Xeon Phi system. The two implementations achieve comparable performance with a slight advantage for the C++ implementation. Xeon Phi performance ranges between CPU and GPU performance.







Similar content being viewed by others



Notes
In this paper, we focus on the data structures array and matrix. The sparse matrix currently does not provide accelerator skeletons.
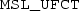
is a contraction for
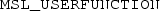
.
The

in
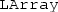
and
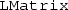
stands for “local” and is thought to denote that only the local partition of a distributed data structure can be accessed locally.





References
Intel Corp: Intel Xeon Phi Coprocessor—The Architecture (Website). https://software.intel.com/en-us/articles/intel-xeon-phi-coprocessor-codename-knights-corner. Accessed Jan 2016
Cole, M.: Algorithmic Skeletons: Structured Management of Parallel Computation. MIT Press, Cambridge (1989)
Cole, M.: Bringing skeletons out of the closet: a pragmatic manifesto for skeletal parallel programming. Parallel Comput. 30(3), 389–406 (2004)
Nickolls, J., Buck, I., Garland, M., Skadron, K.: Scalable parallel programming with CUDA. Queue 6(2), 40–53 (2008)
Ernsting, S., Kuchen, H.: Algorithmic skeletons for multi-core, multi-GPU systems and clusters. Int. J. High Perform. Comput. Netw. 7(2), 129–138 (2012)
Ernsting, S., Kuchen, H.: Data parallel skeletons in java. In: Proceedings of the International Conference on Computational Science (ICCS), pp. 1817–1826. Omaha, Nebraska, USA (2012)
Ciechanowicz, P.: Algorithmic skeletons for general sparse matrices on multi-core processors. In: Proceedings of the 20th IASTED International Conference on Parallel and Distributed Computing and Systems (PDCS), pp. 188–197 (2008)
Poldner, M., Kuchen, H.: Skeletons for divide and conquer algorithms. In: Proceedings of the IASTED International Conference on Parallel and Distributed Computing and Networks (PDCN). ACTA Press (2008)
Poldner, M., Kuchen, H.: Algorithmic skeletons for branch and bound. In: Proceedings of the 1st International Conference on Software and Data Technology (ICSOFT), vol. 1, pp. 291–300 (2006)
Kuchen, H., Striegnitz, J.: Higher-order functions and partial applications for a C++ skeleton library. In: Proceedings of the 2002 Joint ACM-ISCOPE Conference on Java Grande, pp. 122–130. ACM (2002)
Ernsting, S., Kuchen, H.: Java implementation of data parallel skeletons on GPUs. In: Proceedings of the International Conference on Parallel Computing, ParCo 2015. Publication status, Edinburgh (2015) In press
Shafi, A., Carpenter, B., Baker, M.: Nested parallelism for multi-core HPC systems using Java. J. Parallel Distrib. Comput. 69(6), 532–545 (2009)
Frost, G.: A parallel API. http://developer.amd.com/tools-and-sdks/opencl-zone/aparapi/ (2011). Accessed Jan 2016
Aparapi Github pages. https://aparapi.github.io/. Accessed Jan 2016
OpenCL Working Group: The OpenCL Specification, Version 1.2. (2011)
jCuda Website. http://jcuda.org. Accessed Jan 2016
Yan, Y., Grossman, M., Sarkar, V.: JCUDA: a programmer-friendly interface for accelerating java programs with Cuda. In: Euro-Par 2009 Parallel Processing, Lecture Notes in Computer Science, pp. 887–899. Springer (2009)
jOCL Website. http://jocl.org. Accessed Jan 2016
JogAmp Website. http://jogamp.org. Accessed Jan 2016
Docampo, J., Ramos, S., Taboada, G.L., Expósito, R.R., Touriño, J., Doallo, R.: Evaluation of java for general purpose GPU computing. In: 27th International Conference on Advanced Information Networking and Applications Workshops, pp. 1398–1404. Barcelona, Spain (2013)
Nvidia Corp: NVIDIA CUDA C Programming Guide 7.5. Nvidia Corporation (2015)
Gamma, E., Helm, R., Johnson, R., Vlissides, J.: Design Patterns: Elements of Reusable Object-Oriented Software. Addison-Wesley Longman Publishing Co., Inc, Boston (1995)
Quinn, M.J.: Parallel Programming in C with MPI and OpenMP. McGraw-Hill Education Group, New York (2003)
Intel Corp: Vectorization Essentials (Website). https://software.intel.com/en-us/articles/vectorization-essential. Accessed Jan 2016
Steuwer, M., Kegel, P., Gorlatch, S.: SkelCL—a portable skeleton library for high-level GPU programming. In: HIPS ’11: Proceedings of the 16th IEEE Workshop on High-Level Parallel Programming Models and Supportive Environments, Anchorage, AK, USA (2011)
Enmyren, J., Kessler, C.W.: SkePU: a multi-backend skeleton programming Library for multi-GPU systems. In: Proceedings of the Fourth International Workshop on High-Level Parallel Programming and Applications. HLPP ’10, pp. 5–14. ACM, New York, NY, USA (2010)
Aldinucci, M., Torquati, M., Drocco, M., Peretti Pezzi, G., Spampinato, C.: An Overview of FastFlow: Combining Pattern-Level Abstraction and Efficiency in GPGPUs. In: GPU Technology Conference (GTC 2014). San Jose, CA, USA (2014)
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Ernsting, S., Kuchen, H. Data Parallel Algorithmic Skeletons with Accelerator Support. Int J Parallel Prog 45, 283–299 (2017). https://doi.org/10.1007/s10766-016-0416-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10766-016-0416-7