
Abstract
The coherence protocol presented in this work, denoted Mosaic, introduces a new approach to face the challenges of complex multilevel cache hierarchies in future many-core systems. The essential aspect of the proposal is to eliminate the condition of inclusiveness through the different levels of the memory hierarchy while maintaining the complexity of the protocol limited. Cost reduction decisions taken to reduce this complexity may introduce artificial inefficiencies in the on-chip cache hierarchy, especially when the number of cores and private cache size is large. Our approach trades area and complexity for on-chip bandwidth, employing an integrated broadcast mechanism in a directory structure. In energy terms, the protocol scales like a conventional directory coherence protocol, but relaxes the shared information inclusiveness. This allows the performance implications of directory size and associativity reduction to be overcome. As it is even simpler than a conventional directory, the results of our evaluation show that the approach is quite insensitive, in terms of performance and energy expenditure, to the size and associativity of the directory.












Similar content being viewed by others

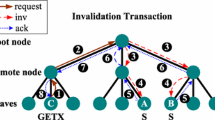
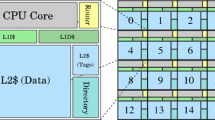
References
Rogers, B.M., Krishna, A., Bell, G.B., Vu, K., Jiang, X., Solihin, Y.: Scaling the bandwidth wall: challenges in and avenues for CMP scaling. Int. Symp. Comput. Archit (ISCA) 37(3), 371 (2009)
ITRS.: Roadmap 2012. http://www.itrs.net/links/2012itrs/home2012.htm (2012)
Prieto, P., Puente, V., Gregorio, J.A.: Multilevel cache modeling for chip-multiprocessor systems. IEEE Comput. Archit. Lett. 10(2), 49–52 (2011)
Butler, M.: “AMD ‘Bulldozer’ Core—a new approach to multithreaded compute performance for maximum efficiency and throughput,” In: IEEE HotChips Symposium on High-Performance Chips (HotChips 2010) (2010)
Hammarlund, P., Martinez, A.J., Bajwa, A.A., Hill, D.L., Hallnor, E., Jiang, H., Dixon, M., Derr, M., Hunsaker, M., Kumar, R., Osborne, R.B., Rajwar, R., Singhal, R., D’Sa, R., Chappell, R., Kaushik, S., Chennupaty, S., Jourdan, S., Gunther, S., Piazza, T., Burton, T.: Haswell: the fourth-generation intel core processor. IEEE Micro 34(2), 6–20 (2014)
Feehrer, J., Jairath, S., Loewenstein, P., Sivaramakrishnan, R., Smentek, D., Turullols, S., Vahidsafa, A.: The oracle sparc T5 16-core processor scales to eight sockets. IEEE Comput. Soc. 33(2), 48–57 (2013)
Kalla, R., Sinharoy, B., Starke, W.J., Floyd, M.: Power7: IBM’s next-generation server processor. IEEE Micro 30(2), 7–15 (2010)
Molka, D., Hackenberg, D., Schone, R., Muller, M.S.: Memory performance and cache coherency effects on an intel nehalem multiprocessor system. In: 2009 18th International Conference on Parallel Architectures and Compilation Techniques, pp. 261–270 (2009)
Busaba, F., Blake, M.A., Curran, B., Fee, M., Jacobi, C., Mak, P.-K., Prasky, B.R., Walters, C.R.: IBM zEnterprise 196 microprocessor and cache subsystem. IBM J. Res. Dev. 56(1), 1:1–1:12 (2012)
Starke, W.J., Stuecheli, J., Daly, D.M., Dodson, J.S., Auernhammer, F., Sagmeister, P.M., Guthrie, G.L., Marino, C.F., Siegel, M., Blaner, B.: The cache and memory subsystems of the IBM POWER8 processor. IBM J. Res. Dev. 59(1), 3:1–3:13 (2015)
Topol, A.W., La Tulipe, D.C., Shi, L., Frank, D.J., Bernstein, K., Steen, S.E., Kumar, A., Singco, G.U., Young, a M., Guarini, K.W., Ieong, M.: Three-dimensional integrated circuits. IBM J. Res. Dev. 50(4), 491–506 (2006)
Choi, B., Komuravelli, R., Sung, H., Smolinski, R., Honarmand, N., Adve, S.V., Carter, N.P., Chou, C.-T.: DeNovo: rethinking the memory hierarchy for disciplined parallelism. In: 20th International Conference on Parallel Architectures and Compilation Techniques (PACT), pp. 155–166 (2011)
Howard, J., Dighe, S., Vangal, S.R., Ruhl, G., Borkar, N., Jain, S., Erraguntla, V., Konow, M., Riepen, M., Gries, M., Droege, G., Lund-Larsen, T., Steibl, S., Borkar, S., De, V.K., Van Der Wijngaart, R.: A 48-core IA-32 processor in 45 nm CMOS using on-die message-passing and DVFS for performance and power scaling. IEEE J. Solid-State Circuits 46(1), 173–183 (2011)
Martin, M.M.K., Hill, M.D., Sorin, D.J.: Why on-chip cache coherence is here to stay. Commun. ACM 55(7), 78 (2012)
Kurd, N., Douglas, J., Mosalikanti, P., Kumar, R.: Next generation Intel®micro-architecture (Nehalem) clocking architecture. In: IEEE Symp. VLSI Circ., pp. 62–63 (2008)
Conway, P., Kalyanasundharam, N., Donley, G., Lepak, K., Hughes, B.: Cache hierarchy and memory subsystem of the AMD opteron processor. IEEE Micro 30(2), 16–29 (2010)
Raghavan, A., Blundell, C., Martin, M.M.K.: Token tenure: PATCHing token counting using directory-based cache coherence. In: 41st IEEE/ACM International Symposium on Microarchitecture (MICRO), pp. 47–58 (2008)
Menezo, L.G., Puente, V., Gregorio, J.A.: The case for a scalable coherence protocol for complex on-chip cache hierarchies in many-core systems. In: 22nd International Conference on Parallel Architectures and Compilation Techniques (PACT), pp. 279–288 (2013)
Gupta, A., Weber, W., Mowry, T.: Reducing memory and traffic requirements for scalable directory-based cache coherence schemes. In: International Conference on Parallel Processing, pp. 167–192 (1990)
Martin, M.M.K., Hill, M.D.D., Wood, D.A.: Token coherence: decoupling performance and correctness. In: 30th International Symposium on Computer Architecture (ISCA), pp. 182–193 (2003)
Baer, J.-L., Wang, W.-H.: On the inclusion properties for multi-level cache hierarchies. ACM SIGARCH Comput. Archit. News 16(2), 73–80 (1988)
Jaleel, A., Borch, E., Bhandaru, M., Steely Jr., S.C., Emer, J.: Achieving non-inclusive cache performance with inclusive caches: temporal locality aware (TLA) cache management policies. In: 43rd IEEE/ACM International Symposium on Microarchitecture (MICRO), pp. 151–162 (2010)
Huh, J., Kim, C., Shafi, H., Zhang, L., Burger, D., Keckler, S.W.: A NUCA substrate for flexible CMP cache sharing. IEEE Trans. Parallel Distrib. Syst. 18(8), 1028–1040 (2007)
Lee, K., Lee, S.J., Yoo, H.J.: Low-power network-on-chip for high-performance SoC design. IEEE Trans. Very Large Scale Integr. Syst. 14(2), 148–160 (2006)
Agarwal, N., Peh, L., Jha, N.K.: In-network snoop ordering (INSO): snoopy coherence on unordered interconnects. In: 15th International Symposium on High Performance Computer Architecture (HPCA), pp. 67–78 (2009)
Jerger, N.E., Peh, L.S., Lipasti, M.: Virtual circuit tree multicasting: a case for on-chip hardware multicast support. In: International Symposium on Computer Architecture (ISCA), pp. 229–240 (2008)
Abad, P., Puente, V., Menezo, L.G., Gregorio, J.A.: Adaptive-Tree Multicast: Efficient Multidestination Support for CMP Communication Substrate. IEEE Trans. Parallel Distrib. Syst. 23(11), 2010–2023 (2012)
Zebchuk, J., Srinivasan, V., Qureshi, M.K.M.K., Moshovos, A.: A tagless coherence directory. In: International Symposium on Microarchitecture (MICRO), pp. 423–434 (2009)
OpenSPARC T2 Core Microarchitecture Specification. Santa Clara, CA (2007)
Sorin, D.J., Plakal, M., Condon, A.E., Hill, M.D., Martin, M.M.K., Wood, D.A.: Specifying and verifying a broadcast and a multicast snooping cache coherence protocol. IEEE Trans. Parallel Distrib. Syst. 13(6), 556–578 (2002)
Sanchez, D., Kozyrakis, C.: SCD: a scalable coherence directory with flexible sharer set encoding. In: 18th IEEE International Symposium on High Performance Computer Architecture, pp. 1–12 (2012)
Sanchez, D., Kozyrakis, C.: The ZCache: decoupling ways and associativity. In: International Symposium on Microarchitecture (MICRO), pp. 187–198 (2010)
Menezo, L.G.: Mosaic coherence protocol specification. State Table (sparse design) (2016). https://www.ce.unican.es/docs/coherence_protocols/mosaic_sparse/index.html
Menezo, L.G.: Mosaic coherence protocol specification. State Table (in-cache design) (2016). https://www.ce.unican.es/docs/coherence_protocols/mosaic_incache/index.html
Shin, J.L., Park, H., Li, H., Smith, A., Choi, Y., Sathianathan, H., Dash, S., Turullols, S., Kim, S., Masleid, R., Konstadinidis, G., Golla, R., Doherty, M.J., Grohoski, G., McAllister, C.: The next-generation 64b SPARC core in a T4 SoC processor. IEEE J. Solid-State Circuits 48(1), 82–90 (2013)
Pinkston, T.M., Duato, J.: Appendix F: interconnection networks. In: Computer Architecture: A Quantitative Approach, 5th ed. Morgan Kaufmann, Burlington (2012)
Menezo, L.G., Puente, V., Abad, P., Gregorio, J.A.: Improving coherence protocol reactiveness by trading bandwidth for latency. In: ACM International Conference on Computing Frontiers (CF’12), pp. 143–152 (2012)
Martin, M.M.K., Sorin, D.J., Beckmann, B.M., Marty, M.R., Xu, M., Alameldeen, A.R., Moore, K.E., Hill, M.D., Wood, D.A.: Multifacet’s general execution-driven multiprocessor simulator (GEMS) toolset. ACM SIGARCH Comput. Archit. News 33(4), 92–99 (2005)
Muralimanohar, N., Balasubramonian, R., Jouppi, N.: Optimizing NUCA organizations and wiring alternatives for large caches with CACTI 6.0. In: 40th IEEE/ACM International Symposium on Microarchitecture (MICRO), pp. 3–14 (2007)
Sun, C., Chen, C.-H.O., Kurian, G., Wei, L., Miller, J., Agarwal, A., Peh, L.-S., Stojanovic, V.: DSENT—a tool connecting emerging photonics with electronics for opto-electronic networks-on-chip modeling. In: International Symposium on Networks-on-Chip (NOCS), pp. 201–210 (2012)
Jin, H., Frumkin, M., Yan, J.: The OpenMP implementation of NAS parallel benchmarks and its performance. Natl. Aeronaut. Sp. Adm. (NASA), Tech. Rep. NAS-99-011, Moffett Field, USA, no. October (1999)
Alameldeen, A.R., Martin, M.M.K., Mauer, C.J., Moore, K.E., Hill, M.D., Wood, D.A., Sorin, D.J.: Simulating a $2M commercial server on a $2K PC. Computer (Long. Beach. Calif) 36(2), 50–57 (2003)
Loh, G.H., Hill, M.D.: Efficiently enabling conventional block sizes for very large die-stacked DRAM caches. In: International Symposium on Microarchitecture (MICRO), p. 454 (2011)
Demetriades, S., Cho, S.: Stash directory: a scalable directory for many-core coherence. In: International Symposium for High-Performance, Computer Architecture (HPCA) (2014)
Cuesta, B.A., Ros, A., Gómez, M.E., Robles, A., Duato, J.F.: Increasing the effectiveness of directory caches by deactivating coherence for private memory blocks. In International Symposium on Computer Architecture (ISCA), p. 93 (2011)
Acknowledgements
Funding was provided by Spanish Government (Grant Nos. TIN2015-66979-R and TIN2016-80512-R).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Menezo, L.G., Puente, V., Abad, P. et al. Mosaic: A Scalable Coherence Protocol. Int J Parallel Prog 46, 1110–1138 (2018). https://doi.org/10.1007/s10766-018-0557-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10766-018-0557-y