
Abstract
Although the Arab world has an estimated number of 250 million Arabic speakers, there has been little research on Arabic speech recognition when compared to other languages of similar importance (e.g. Mandarin). Due to the lack of diacritic Arabic text and the lack of Pronunciation Dictionary (PD), most of previous work on Arabic Automatic Speech Recognition has been concentrated on developing recognizers using Romanized characters i.e. let the system recognizes the Arabic word as an English one, then map it to Arabic word from lookup table that maps the Arabic word to its Romanized pronunciation.
In this work, we introduce the first SPHINX-IV-based Arabic recognizer and propose an automatic toolkit, which is capable of producing (PD) for both Holly Qura’an and standard Arabic language. Three corpuses are completely developed in this work, namely the Holly Qura’an Corpus HQC-1 about 18.5 hours, the command and control corpus CAC-1 about 1.5 hours and Arabic digits corpus ADC less than one hour of speech. The building process is completely described. Fully diacritic Arabic transcriptions, for all the three corpuses were developed too.
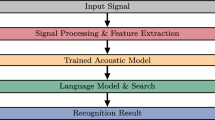
SPHINX-IV engine was customized and trained, for both the language model and the lexicon modules shown in the frame work architecture block diagram on next page.

Using the three mentioned corpuses; the (PD) developed by our automatic tool with the transcripts, SPHINX-IV engine is trained and tuned in order to develop three acoustic models, one for each corpus. Training is based on an HMM model that is built on statistical information and random variables distributions extracted from the training data itself. New algorithm is proposed to add unlabeled data to the training corpus in order to increase the corpus size. This algorithm is based on Neural Network confidence scorer and then is used to annotate the decoded speech in order to decide whether the proposed transcript is accepted and can be added to the seed corpus or not.
The model parameters were fine-tuned using simulated annealing algorithm; optimum values were tested and reported. Our major contribution is mainly using the open source SPHINX-IV model in Arabic speech recognition by building our own language and acoustic models without Romanization for the Arabic speech. The system is fine-tuned and data are refined for training and validation. Optimum values for number of Gaussian mixtures distributions and number of states in HMM’s have been found according to specified performance measures. Optimum values for confidence scores were found for the training data. Although much more work need to be done to complete the work with this size, we consider the corpus used in our system is enough to validate our approach. SPHINX has never been used before in this manner for Arabic speech recognition. The work is an invitation for all open source speech recognition developers and groups to take over and capitalize on what we have started.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.References
Al-Zabibi, M. (1990). An acoustic-phonetic approach in automatic Arabic speech recognition. The British Library in Association with UMI.
Alghamdi, M. (2001). Arabic phonetics. Riyadh: Altawbah Printing.
Alghamdi, M., Al-Muhtaseb, H., & Elshafei, M. (2004). Arabic phonological rules. Journal of King Saud University: Computer Sciences and Information, 16, 1–25 (in Arabic).
Andersen, O., & Kuhn, R., et al. (1996). Comparison of two tree-structured approaches for grapheme-to-phoneme conversion. In ICSLP ’96 (Vol. 3, pp. 1700–1703) Oct. 1996.
Baugh, A. C., & Cable, T. (1978). A history of the English language. Oxon: Redwood Burn Ltd.
Billa, J., et al. (2002a). Arabic speech and text in Tides On Tap. In Proceedings of HLT, 2002.
Billa, J., et al. (2002b). Audio indexing of broadcast news. In Proceedings of ICASSP, 2002.
Black, A., Lenzo, K., & Pagel, V. (1998). Issues in building general letter to sound rules. In Proceedings of the ESCA workshop on speech synthesis, Australia (p. 7780) 1998.
Christensen, H. (1996). Speaker adaptation of hidden Markov models using maximum likelihood linear regression. Ph.D. Thesis, Institute of Electronic Systems Department of Communication Technology, Aalborg University.
CMU SPHINX Open Source Speech Recognition Engines. URL:http://www.speech.cs.cmu.edu/ (2007).
CMU SPHINX trainer Open Source Speech Recognition Engines, URL: http//:www.cmusphinx.org/trainer (2008).
Doh, S.-J. (2000). Enhancements to transformation-based speaker adaptation: principal component and inter-class maximum likelihood linear regression. Ph.D. Thesis, Department of Electrical and Computer Engineering, Carnegie Mellon University.
El Choubassi, M. M., El Khoury, H. E., Jabra Alagha, C. E., Skaf, J. A., & Al-Alaoui, M. A. (2003). Arabic speech recognition using recurrent neural networks. Electrical and Computer Engineering Department, Faculty of Engineering and Architecture—American University of Beirut.
Essa, O. (1998). Using prosody in automatic segmentation of speech. In Proceedings of the ACM 36th annual south east conference (pp. 44–49). Apr. 1998.
Fukada, T., Yoshimura, T., & Sagisaka, Y. (1999). Automatic generation of multiple pronunciations based on neural networks. Speech Communication, 27, 63–73.
Ganapathiraju, A., Hamaker, J., & Picone, J. (2000). Hybrid SVM/HMM architectures for speech recognition. In Proceedings of the international conference on spoken language processing (Vol. 4, pp. 504–507). November 2000.
Gouvêa, E. B. (1996). Acoustic-feature-based frequency warping for speaker normalization. Ph.D. Thesis, Department of Electrical and Computer Engineering, Carnegie Mellon University.
Hadj-Salah, A. (1983). A description of the characteristics of the Arabic language. In Applied Arabic linguistics, signal & information processing, Rabat, Morocco, 26 September–5 October 1983.
Hain, T., et al. (2003). Automatic transcription of conversational telephone speech—development of the CU-HTK 2002 system. (Technical Report CUED/F-INFENG/TR. 465). Cambridge University Engineering Department. Available at http://mi.eng.cam.ac.uk/reports/.
Hermansky, H. (1990). Perceptual linear predictive (PLP) analysis of speech. Journal of the Acoustic Society of America, 87, 1738–1752.
Hiyassat, H., Nedhal, Y., & Asem, E. Automatic speech recognition system requirement using Z notation. In Proceedings of Amse’ 05, Roan, France, 2005.
Huang, X., Alleva, F., Wuen, H., Hwang, M.-Y., & Rosenfeld, R. (2003). The SPHINX-II speech recognition system: an overview . In School of Computer Science Carnegie Mellon University, Pittsburgh, 15213, 2003.
Huerta, J. M. (2000). Robust speech recognition in GSM codec environments. Ph.D. Thesis, Department of Electrical and Computer Engineering, Carnegie Mellon University.
Killer, M., Stüker, S., & Schultz, T. (2003). Grapheme based speech recognition. Eurospeech, Geneva, Switzerland, September 2003.
Killer, M., Stüker, S., & Schultz, T. (2004). A grapheme based speech recognition system for Russian. In SPECOM’2004: 9th conference, speech and computer, St. Petersburg, Russia, September 20–22.
Kirchhoff, K., Bilmes, J., Das, S., Duta, N., Egan, M., Ji, G., He, F., Henderson, J., Liu, D., Noamany, M., Schone, P., Schwartz, R., & Vergyri, D. (2007). Novel approaches to Arabic speech recognition. The 2002 Johns-Hopkins summer workshop, 2002.
Lee, K., Hon, H., & Reddy, R. (1990). An overview of the SPHINX speech recognition. IEEE Transactions on Acoustics, Speech, and Signal Processing, ASSP-28(1), 35–45.
Lee, T., Ching, P. C., & Chan, L. W. (1998). Isolated word recognition using modular recurrent neural networks. Pattern Recognition, 31(6), 751–760.
Liu, F.-H. (1994). Environmental adaptation for robust speech recognition. Ph.D. Thesis, Department of Electrical and Computer Engineering, Carnegie Mellon University, Pittsburgh, PA.
Mimer, B., Stuker, S., & Schultz, T. (2004). Flexible decision trees for grapheme based speech recognition. In Proceedings of the 15th conference elektronische sprach signal verarbeitung (ESSV), Cottbus, Germany, 2004.
Nedel, J. P. (2004). Duration normalization for robust recognition of spontaneous speech via missing feature methods. Ph.D. Thesis, Department of Electrical and Computer Engineering, Carnegie Mellon University.
Ohshima, Y. (1993). Environmental robustness in speech recognition using physiologically-motivated signal processing. Ph.D. Thesis, Department of Electrical and Computer Engineering, Carnegie Mellon University.
Pallet, D. S., et al. (1999). 1998 Broadcast news benchmark test results. In Proceedings of the DARPA broadcast news workshop, Herndon, Virginia, February 28–March 3, 1999.
Rabiner, L. R., & Juang, B.-H. (1993). Fundamentals of speech recognition. Englewood Cliffs: Prentice-Hall.
Raj, B. (2000). Reconstruction of incomplete spectrograms for robust speech recognition. Ph.D. Thesis, Department of Electrical and Computer Engineering, Carnegie Mellon University.
Rosti, A.-V.I. (2004). Linear Gaussian models for speech recognition. Ph.D. Thesis, Wolfson College, University of Cambridge.
Rozzi, W. A. (1991). Speaker adaptation in continuous speech recognition via estilsiation of correlated mean vectors. Ph.D. Thesis, Department of Electrical and Computer Engineering, Carnegie Mellon University.
Russell, S., Binder, J., Koller, D., & Kanazawa, K. (1995). Local learning in probabilistic networks with hidden variables. Computer Science, IJCAI.
Schultz, T. (2002). Globalphone: a multilingual speech and text database developed at Karlsruhe University. In Proceedings of the ICSLP, Denver, CO, 2002.
Schultz, T., Alexander, D., Black, A., Peterson, K., Suebvisai, S., & Waibel, A. (2004). A Thai speech translation system for medical dialogs. In Proceedings of the human language technologies (HLT), Boston, MA, May 2004.
Seltzer, M. L. (2000). Automatic detection of corrupt spectrographic features for robust speech recognition. Master degree Thesis, Department of Electrical and Computer Engineering, Carnegie Mellon University.
Siegler, M. A. (1999). Integration of continuous speech recognition and information retrieval for mutually optimal performance. Ph.D. Thesis, Department of Electrical and Computer Engineering, Carnegie Mellon University.
Young, S. J. (1994). The HTK hidden Markov model toolkit: design and philosophy (CUED/F-INFENG/TR.152). Engineering Department, University of Cambridge.
Zavagliakos, G., et al. (1998). The BNN Byblos 1997 large vocabulary conversational speech recognition system. In Proceedings of ICASSP, 1998.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Hyassat, H., Abu Zitar, R. Arabic speech recognition using SPHINX engine. Int J Speech Technol 9, 133–150 (2006). https://doi.org/10.1007/s10772-008-9009-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10772-008-9009-1