
Abstract
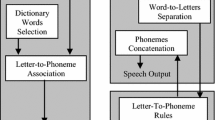
This paper presents a hybrid Artificial Neural Network (ANN)/rule-based phoneme synthesizer for Farsi text. A new variable called Vowel State (VS) is also introduced which efficiently decreases the size of computations. The proposed system uses VS along with the written form of the words to determine their pronunciation. Some rules are also applied to the system to decrease network interconnections. These rules are performed in the Normalization Unit and the Phoneme Extraction Unit before and after the ANN. A multilayer perceptron with 48, 90 and 3 neurons in the input layer, hidden layer and output layer respectively is chosen to determine the Vowel State of each letter. Each letter in a word enters the ANN in the heart of a window in order to recognize the VS of the letter. An asymmetric 8-letter windowing is suggested; 3 letters before the letter along with 4 letters after it enter the ANN as the input.
For training and testing the system, 2359 words are extracted from some online available resources. The results of test show that using 65% of the corpus as training set and testing over the entire corpus gives the result of 84% correct answers for the ANN, and 90% correct answer for the entire system considering additional rules. The performance index of the ANN increases to 88, 92, 98 and 99 percent when the percentage of the training set increases to 75, 85, 95 and 100, respectively. The system also shows the performance of 93% correct answers on an independent word database.
The proposed hybrid ANN/rule-based method imposes small size of calculation in comparison with similar systems. In this system, the output of ANN is a 5-value variable Vowel State instead of numerous phonemes. This fact decreases the neurons in the output layer of ANN considerably. Besides, adding some rules before and after the network helps to increase performance.
The overall system shows a decrement of 70% in the size of computations comparing with other reported approaches.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.References
Aboutalebi, H. (1998). An implementation of a robust Farsi speech synthesizer. M.S. thesis. Tehran, Iran, Sharif University of Technology.
An, Z. G., Mniszewski, S. M., Lee, Y. C., Papcun, G., & Doolen, G. D. (1988). HIERtalker: a default hierarchy of high order neural networks that learns to read English aloud. In IEEE annual international conference on neural networks, San Diego, CA (Vol. 2, pp. 221–228) 1988.
Braspenning, P. J., Thuijsman, F., & Weijters, A. J. M. M. (1995). Artificial neural networks: an introduction to ann theory and practice. London: Springer.
Burniston, J. D., & Curtis, K. M. (1992). A hybrid rule based/rule following parallel processing architecture. In Conference on parallel computing and transputers applications, Barcelona, Spain (Vol. 1, pp. 729–735) 1992.
Comrie, B. (1991). Persian. In The world’s major languages. Kent: Oxford University Press.
Embrechts, M. J., & Arciniegas, F. (2000). Neural networks for text-to-speech phoneme recognition. In IEEE international conference on systems, man and cybernetics, Nashville, TN (Vol. 5, pp. 3582–3587) 2000.
Gubbins, P., Curtis, K., & Burniston, J. (1994). A hybrid neural network/rule based architecture used as a text to phoneme transcriber. In International symposium on speech, image processing and neural networks (Vol. 1, pp. 113–116) 1994.
Hochberg, J., Mniszewski, S. M, Calleja, T., & Papcun, G. J. (1991). A default hierarchy for pronouncing English. IEEE Transactions on Pattern Analysis and Machine Intelligence, 13(9), 957–964.
Homayonpour, M. M., & Hosaini, N. A. (2000). Farsi text-to phoneme conversion applying neural networks. In 8th Iranian conference on electrical engineering. Tehran, Iran (Vol. 2, pp. 134–137) 2000 (in Farsi)
Mahootian, S. (1997). Persian. London: Routledge.
Samare, Y. (1984). Farsi language phonology. Tehran: Tehran University Press (in Farsi)
Sejnowski, T. J., & Rosenberg, C. R. (1987). NETtalk: parallel networks that learn to pronounce English text. Complex Systems, 1, 145–168.
Torkkola, K. (1993). An efficient way to learn English grapheme-to-phoneme rules automatically. In IEEE international conference on acoustics, speech, and signal processing. Minneapolis, MN (Vol. 2, pp. 199–202) 1993.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Rasekh, E., Eshghi, M. An efficient hybrid solution for pronouncing Farsi text. Int J Speech Technol 10, 153–161 (2007). https://doi.org/10.1007/s10772-009-9018-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10772-009-9018-8