
Abstract
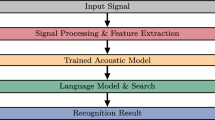
One of the problems in the speech recognition of Modern Standard Arabic (MSA) is the cross-word pronunciation variation. Cross-word pronunciation variations alter the phonetic spelling of words beyond their listed forms in the phonetic dictionary, leading to a number of Out-Of-Vocabulary (OOV) wordforms. This paper presents a knowledge-based approach to model cross-word pronunciation variation at both phonetic dictionary and language model levels. The proposed approach is based on modeling cross-word pronunciation variation by expanding the phonetic dictionary and corpus transcription. The Baseline system contains a phonetic dictionary of 14,234 words from a 5.4 hours corpus of Arabic broadcast news. The expanded dictionary contains 15,873 words. Also, the corpus transcription is expanded according to the applied Arabic phonological rules. Using Carnegie Mellon University (CMU) Sphinx speech recognition engine, the Enhanced system achieved Word Error Rate (WER) of 9.91% on a test set of fully discretized transcription of about 1.1 hours of Arabic broadcast news. The WER is enhanced by 2.3% compared to the Baseline system.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.References
Abdullah, H. (2008). Almoyassar Almofeed fe Ilm Altajweed, Jordan. http://www.islamhouse.com/p/320902.
Alghamdi, M., Almuhtasib, H., & Elshafei, M. (2004). Arabic phonological rules. King Saud University Journal: Computer Sciences and Information, 16, 1–25.
Alghamdi, M., Elshafei, M., & Almuhtasib, H. (2009). Arabic broadcast news transcription system. International Journal of Speech and Technology, 10, 183–195.
Ali, M., Moustafa, E., Mansour, A., Husni, A., & Atef, A. (2009). Arabic phonetic dictionaries for speech recognition. Journal of Information Technology Research, 2(4), 67–80.
Amdal, I., Fossler-Lussier E. (2003). Pronunciation variation modeling in automatic speech recognition, Telektronikk, 99(2).
Amdal, I., Korkmazskiy, F., & Surendran, A. C. (2000). Joint pronunciation modeling of non-native speakers using data-driven methods. In ICSLP, Beijing, China (pp. 622–625).
Al-Haj, H., Hsiao, R., Lane, I., Black, W. A., & Waibel, A. (2009). Pronunciation modeling for dialectal Arabic speech recognition. In ASRU 2009: IEEE workshop, Italy.
Benzeghiba, M., De Mori, R., Deroo, O., Dupont, S., Erbes, T., Jouvet, D., Fissore, L., Laface, P., Mertins, A., Ris, C., Rose, R., Tyagi, V., & Wellekens, C. (2007). Automatic speech recognition and speech variability: a review. Speech Communication, 49(10–11), 763–786.
Beulen, K., Ortmanns, S., Eiden, A., Martin, S., Welling, L., Overmann, J., & Ney, H. (1998). Pronunciation modeling in the RWTH large vocabulary speech recognizer. In Proceedings of the ESCA workshop: modeling pronunciation variation for automatic speech recognition (pp. 13–16).
Biadsy, F., Habash, N., & Hirschberg, J. (2009). Improving the Arabic pronunciation dictionary for phone and word recognition with linguistically-based pronunciation rules. In The 2009 annual conference of the North American chapter of the ACL, Colorado (pp. 397–405).
Billa et al. (2002). Arabic speech and test in tides on tap. In Proceedings of HLT.
Boulianne, G., Brousseau, J., Ouellet, P., & Dumouchel, P. (2000). French large vocabulary recognition with cross-word phonology transducers. ICASSP Proceedings, 3, 1675–1678.
Elshafei, A. M. (1991). Toward an Arabic text-to-speech system. The Arabian Journal of Science and Engineering, 16(4B), 565–583.
Elshafei, M., Almuhtasib, H., & Alghamdi, M. (2002). Techniques for high quality text-to-speech. Information Sciences, 140(3–4), 255–267.
Finke, M., & Waibel, A. (1997). Speaking mode dependent pronunciation modeling in large vocabulary conversational speech recognition. In Proc. of EuroSpeech-97, Rhodes (pp. 2379–2382).
Fosler-Lussier, E., Greenberg, S., & Morgan, N. (1999). Incorporating contextual phonetics into automatic speech recognition. In International congress of phonetic sciences (ICPhS’99), San Francisco, California (pp. 611–614).
Giachin, E. P., Rosenberg, A. E., & Lee, C.-H. (1991). Word juncture modeling using phonological rules for HMM-based continuous speech recognition. Computer Speech and Language, 5(2), 155–168.
Helmer, S. (2001). Pronunciation adaptation at the lexical level. In Proceedings ISCA ITRW workshop adaptation methods for speech recognition, Sophia Antipolis, France.
Kessens, J. M., Strik, H., & Cucchiarini, C. (2000). A bottom-up method for obtaining information about pronunciation variation. In ICSLP, Beijing, China.
Kim, M., Oh, Y. R., & Kim, H. K. (2007). Non-native pronunciation variation modeling using an indirect data-driven method. In Proceedings of the ASRU, Japan.
Kyong-Nim, L., & Minhwa, C. (2007). Morpheme-based modeling of pronunciation variation for large vocabulary continuous speech recognition in Korean. IEICE Transactions on Information and Systems, E90-D(7), 1063–1072.
Lyu, D., Lyu, R., Chiang, Y., & Hsu, C. (2005). Modeling pronunciation variation for bi-lingual Mandarin/Taiwanese speech recognition. Computational Linguistics & Chinese Language Processing, 10(3).
McAllister, D., et al. (1998). Fabricating conversational speech data with acoustic models: a program to examine model-data mismatch. In Proceedings of the ICSLP, Sydney (pp. 1847–1850).
Nock, H. J., & Young, S. J. (1998). Detecting and correcting poor pronunciations for multiword units. In ESCA workshop.
Plötz, T. (2005). Advanced stochastic protein sequence analysis. PhD Thesis, Bielefeld University.
Pousse, L., & Perennou, G. (1997). Dealing with pronunciation variants at the language model level for automatic continuous speech recognition of French. In Proceedings of the EuroSpeech-97, Rhodes (pp. 2727–2730).
Ravishankar, M., & Eskenazi, M. (1997). Automatic generation of context-dependent pronunciations. In Proceedings of the EuroSpeech-97, Rhodes (pp. 2467–2470).
Riley, M., & Ljolje, A. (1995). Automatic generation of detailed pronunciation lexicons. In Automatic speech and speaker recognition: advanced topics (pp. 285–302). Dordrecht: Kluwer Academic.
Saraçlar, M., Nock, H., & Khudanpur, S. (2000). Pronunciation modeling by sharing Gaussian densities across phonetic models. Computer Speech and Language, 14, 137–160.
Seman, N., & Jusoff, K. (2008). Automatic segmentation and labeling for spontaneous standard Malay speech recognition. In 2008 international conference on advanced computer theory and engineering, Thailand (pp. 59–63).
Saon, G., & Padmanabhan, M. (2001). Data-driven approach to designing compound words for continuous speech recognition. IEEE Transactions on Speech and Audio Processing, 9(4), 327–332.
Sloboda, T., & Waibel, A. (1996). Dictionary learning for spontaneous speech recognition. In Proceedings of the ICSLP-96, Philadelphia (PA), USA (pp. 2328–2331).
Tajchman, G., Fosler, E., & Jurafsky, D. (1995). Building multiple pronunciation models for novel words using exploratory computational phonology. In EuroSpeech-95, Madrid, Spain (pp. 2247–2250).
Wester, M. (2003). Pronunciation modeling for ASR, knowledge-based and data-derived methods. Computer Speech & Language, 17(1), 69–85.
Wester, M., & Fosler-lussier, E. (2000). A comparison of data-derived and knowledge-based modeling of pronunciation variation. In Proceedings of the ICSLP’00, Beijing.
Yang, J., Wu, P., & Xu, D. (2008). Mandarin speech recognition for nonnative speakers based on pronunciation dictionary adaptation. New York: IEEE.
Yang, Q., & Martens, J.-P. (2000). Data-driven lexical modeling of pronunciation variations for ASR. In Proceedings of the ICSLP-2000, Beijing (pp. 417–420).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
AbuZeina, D., Al-Khatib, W., Elshafei, M. et al. Cross-word Arabic pronunciation variation modeling for speech recognition. Int J Speech Technol 14, 227–236 (2011). https://doi.org/10.1007/s10772-011-9098-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10772-011-9098-0