
Abstract
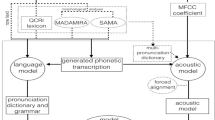
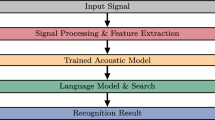
Pronunciation variation is a major obstacle in improving the performance of Arabic automatic continuous speech recognition systems. This phenomenon alters the pronunciation spelling of words beyond their listed forms in the pronunciation dictionary, leading to a number of out of vocabulary word forms. This paper presents a direct data-driven approach to model within-word pronunciation variations, in which the pronunciation variants are distilled from the training speech corpus. The proposed method consists of performing phoneme recognition, followed by a sequence alignment between the observation phonemes generated by the phoneme recognizer and the reference phonemes obtained from the pronunciation dictionary. The unique collected variants are then added to dictionary as well as to the language model. We started with a Baseline Arabic speech recognition system based on Sphinx3 engine. The Baseline system is based on a 5.4 hours speech corpus of modern standard Arabic broadcast news, with a pronunciation dictionary of 14,234 canonical pronunciations. The Baseline system achieves a word error rate of 13.39%. Our results show that while the expanded dictionary alone did not add appreciable improvements, the word error rate is significantly reduced by 2.22% when the variants are represented within the language model.
Similar content being viewed by others

References
AbuZeina, D., Al-Khatib, W., Elshafei, M., & Al-Muhtaseb, H. (2011). Cross-word Arabic pronunciation variation modeling for speech recognition. International Journal of Speech Technology.
Alghamdi, M., Almuhtasib, H., & Elshafei, M. (2004). Arabic phonological rules. Journal of King Saud University: Computer and Information Sciences, 16, 1–25.
Alghamdi, M., Elshafei, M., & Almuhtasib, H. (2009). Arabic broadcast news transcription system. International Journal of Speech and Technology, 10, 183–195.
Ali, M., Moustafa, E., Mansour, A., Husni, A., & Atef, A. (2009). Arabic phonetic dictionaries for speech recognition. Journal of Information Technology Research, 2(4), 67–80.
Alsuwaiyel, M. H. (2003). Algorithms: design techniques and analysis. Singapore: World Scientific.
Amdal, I., & Fossler-Lussier, E. (2003). Pronunciation variation modeling in automatic speech recognition. Telektronik, 99(2).
Al-Haj, H., Hsiao, R., Lane, I. W., Black, A., & Waibel, A. (2009). Pronunciation modeling for dialectal Arabic speech recognition. In ASRU 2009: IEEE workshop, Italy.
Benzeghiba, M., De Mori, R., Deroo, O., Dupont, S., Erbes, T., Jouvet, D., Fissore, L., Laface, P., Mertins, A., Ris, C., Rose, R., Tyagi, V., & Wellekens, C. (2007). Automatic speech recognition and speech variability: a review. Speech Communication, 49(10–11), 763–786.
Biadsy, F., Habash, N., & Hirschberg, J. (2009). Improving the Arabic pronunciation dictionary for phone and word recognition with linguistically-based pronunciation rules. In The 2009 annual conference of the North American chapter of the ACL, Colorado (pp. 397–405).
Billa, et al. (2002). Arabic speech and test in Tides on Tap. In Proceedings of HLT.
Elshafei, Ahmed M. (1991). Toward an Arabic text-to-speech system. The Arabian Journal of Science and Engineering, 16(4B), 565–583.
Elshafei, M., Almuhtasib, H., & Alghamdi, M. (2002). Techniques for high quality text-to-speech. Information Sciences, 140(3–4), 255–267.
Finke, M., & Waibel, A. (1997). Speaking mode dependent pronunciation modeling in large vocabulary conversational speech recognition. In Proceedings of EuroSpeech-97, Rhodes (pp. 2379–2382).
Fosler-Lussier, E., Greenberg, S., & Morgan, N. (1999). Incorporating contextual phonetics into automatic speech recognition. In International Congress of Phonetic Sciences (ICPhS ’99), San Francisco, California (pp. 611–614).
IPA for Arabic (2011). http://en.wikipedia.org/wiki/Wikipedia:IPA_for_Arabic.
Helmer, S. (2001). Pronunciation adaptation at the lexical level. In Proceedings ISCA ITRW workshop adaptation methods for speech recognition, Sophia Antipolis, France.
Jeon, J., Cha, S., Chung, M., Park, J., & Hwang, K. (1998). Automatic generation of Korean pronunciation variants by multistage applications of phonological rules. In ICSLP-1998 (paper 0675).
Jurafsky, D., & Martin, J. (2009). Speech and language processing (2nd ed.). Upper Saddle River: Pearson.
Kessens, J. M., Strik, H., & Cucchiarini, C. (2000). A bottom-up method for obtaining information about pronunciation variation. In ICSLP, Beijing, China.
Kyong-Nim, L., & Minhwa, C. (2007). Morpheme-based modeling of pronunciation variation for large vocabulary continuous speech recognition in Korean. IEICE Transactions on Information and Systems, E90-D(7), 1063–1072.
Liu, Y., & Fung, P. (2003, to appear). Modeling partial pronunciation variations for spontaneous Mandarin speech recognition. Computer Speech and Language.
McAllister, D., et al. (1998). Fabricating conversational speech data with acoustic models: a program to examine model-data mismatch. In Proceedings of the ICSLP, Sydney (pp. 1847–1850).
MITCogNet (2010). http://mitpdev.mit.edu/library/erefs/arbib/images/figures/A248_fig001.gif.
Plötz, T. (2005). Advanced stochastic protein sequence analysis. PhD Thesis, Bielefeld University.
Saraçlar, M., Nock, H., & Khudanpur, S. (2000). Pronunciation modeling by sharing Gaussian densities across phonetic models. Computer Speech and Language, 14, 137–160.
Seman, N., & Jusoff, K. (2008). Automatic segmentation and labeling for spontaneous standard Malay speech recognition. In International conference on advanced computer theory and engineering, Thailand (pp. 59–63).
Saon, G., & Padmanabhan, M. (2001). Data-driven approach to designing compound words for continuous speech recognition. IEEE Transactions on Speech and Audio Processing, 9(4), 327–332.
Sloboda, T., & Waibel, A. (1996). Dictionary learning for spontaneous speech recognition. In Proceedings of the ICSLP-96, Philadelphia, PA, USA (pp. 2328–2331).
Tajchman, G., Fosler, E., & Jurafsky, D. (1995). Building multiple pronunciation models for novel words using exploratory computational phonology. In EUROSPEECH-95, Madrid, Spain (pp. 2247–2250).
Wester, M. (2003). Pronunciation modeling for ASR, knowledge-based and data-derived methods. Computer Speech & Language, 17(1), 69–85.
{kind=link}
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
AbuZeina, D., Al-Khatib, W., Elshafei, M. et al. Within-word pronunciation variation modeling for Arabic ASRs: a direct data-driven approach. Int J Speech Technol 15, 65–75 (2012). https://doi.org/10.1007/s10772-011-9122-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10772-011-9122-4