
Abstract
We propose a pitch synchronous approach to design the voice conversion system taking into account the correlation between the excitation signal and vocal tract system characteristics of speech production mechanism. The glottal closure instants (GCIs) also known as epochs are used as anchor points for analysis and synthesis of the speech signal. The Gaussian mixture model (GMM) is considered to be the state-of-art method for vocal tract modification in a voice conversion framework. However, the GMM based models generate overly-smooth utterances and need to be tuned according to the amount of available training data. In this paper, we propose the support vector machine multi-regressor (M-SVR) based model that requires less tuning parameters to capture a mapping function between the vocal tract characteristics of the source and the target speaker. The prosodic features are modified using epoch based method and compared with the baseline pitch synchronous overlap and add (PSOLA) based method for pitch and time scale modification. The linear prediction residual (LP residual) signal corresponding to each frame of the converted vocal tract transfer function is selected from the target residual codebook using a modified cost function. The cost function is calculated based on mapped vocal tract transfer function and its dynamics along with minimum residual phase, pitch period and energy differences with the codebook entries. The LP residual signal corresponding to the target speaker is generated by concatenating the selected frame and its previous frame so as to retain the maximum information around the GCIs. The proposed system is also tested using GMM based model for vocal tract modification. The average mean opinion score (MOS) and ABX test results are 3.95 and 85 for GMM based system and 3.98 and 86 for the M-SVR based system respectively. The subjective and objective evaluation results suggest that the proposed M-SVR based model for vocal tract modification combined with modified residual selection and epoch based model for prosody modification can provide a good quality synthesized target output. The results also suggest that the proposed integrated system performs slightly better than the GMM based baseline system designed using either epoch based or PSOLA based model for prosody modification.




Similar content being viewed by others

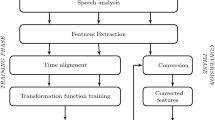
References
Abe, M., Nakanura, S., Shikano, K., & Kuwabara, H. (1988). Voice conversion through vector quantization. In Proc. of int. conf. on acoustics, speech, and signal process (Vol. 1, pp. 655–658). New York: IEEE.
Akagi, M., & Ienaga, T. (1995). Speaker individualities in fundamental frequency contours and its control. In Proc. of Eurospeech (pp. 439–442).
Arslan, L. M. (1999). Speaker transformation algorithm using segmental code books (STASC). Speech Communication, 28(3), 211–226.
Baudoin, G., & Stylianou, Y. (1996). On the transformation of speech spectrum for voice conversion. In Proc. of int. conf. on spoken language process (Vol. 3, pp. 1045–1048).
Chappel, D. T., & Hansen, J. H. (1998). Speaker specific pitch contour modeling and modification. In Proc. of int. conf. on acoustics, speech, and signal process (Vol. 2, pp. 885–888). Seattle: IEEE.
Chen, Y., Chu, M., Chang, E., Liu, J., & Runsheng, L. (2003). Voice conversion using smooth GMM and MAP adaptation. In Proc. of Eurospeech, Geneva (pp. 2413–2416).
Collobert, R., & Bengio, S. (2001). SVMTorch: support vector machines for large scale regression problems. Journal on Machine Learning, 1, 143–160.
Cruz, F. P., & Rodríguez, A. A. (2004). Speeding up the IRWLS convergence to the SVM solution. In Proc. of int. joint conf. on neural networks, IEEE, special session on least squares support vector machines (Vol. 4, pp. 555–560).
Cruz, F. P., Camps, G., Soria, E., Perez, J., Vidal, A. R. F., & Rodriguez, A. A. (2002). Multi-dimensional function approximation and regression estimation. In Proc. of int. conf. on artificial neural networks, Madrid, Spain (Vol. 2, pp. 757–762).
Cruz, F. P., Calzon, C. B., & Rodriguez, A. A. (2005). Convergence of the IRWLS procedure to the support vector machine solution. Neural Computation, 17(1), 7–18.
Desai, S., Black, A. W., Yegnanarayana, B., & Prahallad, K. (2010). Spectral mapping using artificial neural networks for voice conversion. IEEE Transactions on Audio, Speech, and Language Processing, 18(5), 954–964.
Dhananjaya, N., & Yegnarayana, B. (2010). Voiced/nonvoiced detection based on robustness of voiced epochs. IEEE Signal Processing Letters, 17(3), 273–276.
Drugman, T., Moinet, A., Dutoit, T., & Wilfart, G. (2009). Using a pitch synchronous residual codebook for hybrid HMM/frame selection speech synthesis. In Proc. of int. conf. on acoustics, speech, and signal process (pp. 3793–3796). Taipei: IEEE.
Fernandez, M. S., Cumplido, M. P., García, J. A., & Cruz, F. P. (2004). SVM multi-regression for nonlinear channel estimation in multiple-input multiple-output systems. IEEE Transactions on Signal Processing, 52(8), 2298–2307.
Ghosh, P. K., & Narayanan, S. S. (2009). Pitch contour stylization using an optimal piecewise polynomial approximation. IEEE Signal Processing Letters, 16(9), 810–813.
Han, X., Zhao, X., Fang, T., & Jia, X. (2011). Research on EEDSVQ of LSF parameters based on voiced and unvoiced classification. Journal of Convergence Information Technology, 6(1), 116–125.
Helander, E., Silen, H., Virtanen, T., & Gabbouj, M. (2012). Voice conversion using dynamic kernel partial least squares regression. IEEE Transactions on Speech and Audio Processing, 20(3), 806–817.
Inanoglu, Z. (2003). Transforming pitch in a voice conversion framework. M.Phil. thesis, St. Edmund’s College University of Cambridge. July, 2003.
Joachims, T. (1999). Making large-scale SVM learning practical. In B. Scholkopf, C. Burges & A. Smola (Eds.), Advances in kernel methods-support vector learning (pp. 169–184). Cambridge: MIT Press.
Kain, A., & Macon, M. (1998). Spectral voice conversion for text-to-speech synthesis. In Proc. of int. conf. on acoustics, speech, and signal process (Vol. 1, pp. 285–288). New York: IEEE.
Kain, A., & Macon, M. W. (2001). Design and evaluation of a voice conversion algorithm based on spectral envelop mapping and residual prediction. In Proc. of int. conf. on acoustics, speech, and signal process (Vol. 2, pp. 813–816). New York: IEEE.
Kuwabara, H. (1984). A pitch-synchronous analysis/synthesis to independently modify formant frequencies and bandwidth for voiced speech. Speech Communication, 3(3), 211–220.
Kuwabara, H., & Sagisaka, Y. (1995). Acoustics characteristics of speaker individuality: control and conversion. Speech Communication, 16(2), 165–173.
Laskar, R. H., Talukdar, F. A., Paul, B., & Chakrabarty, D. (2011). Sample reduction using recursive and segmented data structure analysis. Journal of Engineering and Computer Innovations, 2(4), 59–67.
Lee, K.-S. (2007). Statistical approach for voice personality transformation. IEEE Transactions on Audio, Speech, and Language Processing, 15(2), 641–651.
Lee, K. S., Youn, D. H., & Cha, I. W. (1996). A new voice personality transformation based on both linear and non-linear prediction analysis. In Proc. of int. conf. on spoken language process (pp. 1401–1404).
Mesbahi, L., Barreaud, V., & Boeffard, O. (2007). GMM-based speech transformation system under data reduction. In Proc. of int. speech comm. assoc., speech synthesis workshop (pp. 119–124). Bonn, Germany.
Mousa, A. (2010). Voice conversion using pitch shifting algorithm by time stretching with PSOLA and re-sampling. Journal of Electrical Engineering, 61(1), 57–61.
Murthy, K. S. R., & Yegnanarayana, B. (2006). Combining evidence from residual phase and MFCC features for speaker recognition. IEEE Signal Processing Letters, 13(1), 52–56.
Narendranath, M., Murthy, H. A., Rajendran, S., & Yegnanarayana, B. (1995). Transformation of formants for voice conversion using artificial neural networks. Speech Communication, 16(2), 206–216.
Perrot, P., Aversano, G., & Chollet, G. (2007). Voice disguise and automatic detection review and perspective. In Lecture notes in computer science (Vol. 4391, pp. 101–117). Berlin: Springer.
Platt, J. (1999). Fast training of support vector machines using sequential minimal optimization. In B. Scholkopf, C. Burges & A. Smola (Eds.), Advances in kernel methods-support vector learning (pp. 185–208). Cambridge: MIT Press.
Prasanna, S. R. M., Gupta, C. S., & Yegnanarayana, B. (2006). Extraction of speaker-specific information from linear prediction residual of speech. Speech Communication, 48(10), 1243–1261.
Rao, K. S. (2010). Voice conversion by mapping the speaker-specific features using pitch synchronous approach. Computer Speech & Language Processing, 24(3), 474–494.
Rao, K. S., & Yegnanarayana, B. (2006). Prosody modification using instants of significant excitation. IEEE Transactions on Audio, Speech, and Language Processing, 14(3), 972–980.
Rao, K. S., Laskar, R. H., & Koolagudi, S. G. (2007). Voice transformation by mapping the features at syllable level. In Lecture notes in computer sciences (Vol. 4815, pp. 479–486). Berlin: Springer.
Stylianou, Y., Cappe, Y., & Moulines, E. (1998). Continuous probabilistic transform for voice conversion. IEEE Transactions on Speech and Audio Processing, 6(2), 131–142.
Suendermann, D., Ney, H., & Hoege, H. (2003). VTLN-based cross-language voice conversion. In Proc. of automatic speech recognition and understanding workshop (pp. 676–681). New York: IEEE.
Sundermann, D., Bonafonte, A., Hoge, H., & Ney, H. (2004). Voice conversion using exclusively unaligned training data. In Proc. of ACL/SEPLN 2004, 42nd annu. meeting assoc. for comput. Linguistics/XX congreso de la sociedad espanola para el procesamiento del lenguaje natural, Barcelona, Spain, July, 2004.
Suendermann, D., Bonafonte, A., Ney, H., & Hoege, H. (2005a). A study on residual prediction techniques for voice conversion. In Proc. of int. conf. on acoustics, speech, and signal process (pp. 13–16). New York: IEEE.
Suendermann, D., Hoege, H., Bonafonte, A., Ney, H., & Black, A. (2005b). Residual prediction based on unit selection. In Proc. of automatic speech recognition and understanding workshop (pp. 369–374). New York: IEEE.
Toda, T., Saruwatari, H., & Shikano, K. (2001). Voice conversion algorithm based on Gaussian mixture model with dynamic frequency warping of STRAIGHT spectrum. In Proc. of int. conf. on acoustics, speech, and signal process (Vol. 2, pp. 841–844). New York: IEEE.
Toth, A., & Black, A. W. (2008). Incorporating durational modification in voice transformation. In Proc. of interspeech, Brisbane, Australia (pp. 1088–1091).
Turk, O., & Arslan, L. M. (2006). Robust processing techniques for voice conversion. Computer Speech & Language Processing, 20(4), 441–467.
Verhelst, W., & Mertens, J. (1996). Voice conversion using partitions of spectral feature space. In Proc. of int. conf. on acoustics, speech, and signal process (Vol. 1, pp. 365–368). New York: IEEE.
Wang, D., & Shi, L. (2008). Selecting valuable training samples for SVMs via data structure analysis. Neurocomputing, 71(13), 2772–2781.
Ye, H., & Young, S. (2004). High quality voice morphing. In Proc. of int. conf. on acoustics, speech, and signal process (Vol. I, pp. 9–12). New York: IEEE.
Yegnanarayana, B., Reddy, K. S., & Kishore, S. P. (2001). Source and system features for speaker recognition using AANN models. In Proc. of int. conf. on acoustics, speech, and signal process (Vol. 1, pp. 409–412). New York: IEEE.
Yegnarayana, B., & Veldhuis, R. N. J. (1998). Extraction of vocal-tract system characteristics from speech signals. IEEE Transactions on Speech and Audio Processing, 6(4), 313–327.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Hussain Laskar, R., Banerjee, K., Talukdar, F.A. et al. A pitch synchronous approach to design voice conversion system using source-filter correlation. Int J Speech Technol 15, 419–431 (2012). https://doi.org/10.1007/s10772-012-9164-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10772-012-9164-2