
Abstract
Feature selection methods are the mostly used dimensional reduction methods in speech emotion recognition. However, most methods cannot preserve the manifold of data and cannot use the information provided by unlabeled data, so that they cannot select a good sub feature set for speech emotion recognition. This paper presents a semi-supervised feature selection method that can preserve the manifold structure of data, preserve the category structure, and use the information provided by the unlabeled data. To further deal with the manifold of speech data influenced by factors such as emotion, speaker and sentence, a new speaker normalization method is also proposed, which can achieve a good speaker normalization result in the case of a small number of samples of a speaker available. This speaker normalization method can be used in most real application of speech emotion recognition. The conducted experiments validate the proposed semi-supervised feature selection method with the speaker normalization in terms of the effectiveness of the speech emotion recognition.





Similar content being viewed by others
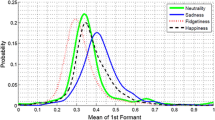
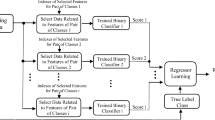
References
Albornoz, E. M., Milone, D. H., & Rufiner, H. L. (2011). Spoken emotion recognition using hierarchical classifiers. Computer Speech and Language, 25(3), 556–570.
Alexei (Alyosha) Efros, Advanced Machine Perception, https://www.cs.cmu.edu/~efros/courses/AP06/presentations/ThompsonDimensionalityReduction.pdf
Ayadi, El, Moataz, K., & Karray, F. (2011). Survey on speech emotion recognition: Features, classification schemes, and databases. Pattern Recognition, 44(3), 572–587.
Belkin, M., & Niyogi, P. (2003). Laplacian Eigenmaps for dimensionality reduction and data representation. Neural Computation, 15(6), 1373–1396.
Bitouk, D., Verma, R., & Nenkova, A. (2010). Class-level spectral features for emotion recognition. Speech Communication, 52(7), 613–625.
Bozkurt, E., Erzin, E., & Erdem, Çiǧdem Eroǧlu. (2011). Formant position based weighted spectral features for emotion recognition. Speech Communication, 53(9–10), 1186–1197.
Burkhardt, F., Paeschke, A., Rolfes, M., Sendlmeier, W. F., & Weiss, B. (2005). A database of German emotional speech, In Proceedings INTERSPEECH, Lisbon, (pp. 1517–1520).
Busso, C., Metallinou, A., & Narayanan, S. S. (2011). Iterative feature normalization for emotional speech detection, In Proceedings IEEE international conference on acoustics, speech and signal processing (ICASSP), (pp. 5692–5695).
Cai, D., Zhang, C., & He, X. (2010). Unsupervised feature selection for multi-cluster data, In Proceedings international conference on knowledge discovery and data mining (SIGKDD), (pp. 333–342).
Chang, C.-C., & Lin, C.-J. (2011). LIBSVM—A library for support vector machines. ACM Transactions on Intelligent Systems and Technology, 2(3), 1–27.
Chen, L., Mao, X., Xue, Y., & Cheng, L. L. (2012). Speech emotion recognition: Features and classification models. Digital Signal Processing, 22(6), 1154–1160.
Gharavian, D., Sheikhan, M., Nazerieh, A., & Garoucy, S. (2012). Speech emotion recognition using FCBF feature selection method and GA-optimized fuzzy ARTMAP neural network. Neural Computing and Applications, 21(8), 2115–2126.
Haq, S., & Jackson, P. J. B. (2009). Speaker-dependent audio-visual emotion recognition In Proceedings international conference on auditory-visual speech processing (AVSP), (pp. 53–58).
Hassan, A., & Damper, R. I. (2012). Classification of emotional speech using 3DEC hierarchical classifier. Speech Communication, 54(7), 903–916.
He, X., Cai, D., & Niyogi, P. (2005). Laplacian score for feature selection, In Proceedings advances in neural information processing systems(NIPS), (pp. 507–514).
He, L., Lech, M., Maddage, N. C., & Allen, N. B. (2011). Study of empirical mode decomposition and spectral analysis for stress and emotion classification in natural speech. Biomedical Signal Processing and Control, 6(2), 139–146.
Hou, C., Nie, F., & Li, X. (2011). Joint embedding learning and sparse regression: A framework for unsupervised feature selection. IEEE Transactions Cybernetics, pp(99), 1–12.
Huang, H., Li, J., & Liu, J. (2012). Enhanced semi-supervised local Fisher discriminant analysis for face recognition. Future Generation Computer Systems, 28(1), 244–253.
Iliev, A. I., Scordilis, M. S., Papab, J. P., & Falcão, A. X. (2010). Spoken emotion recognition through optimum-path forest classification using glottal features. Computer Speech and Language, 24(3), 445–460.
Kim, D-S., Jeong, J-H., & Kim, J-W. (1996). Feature extraction based on zero-crossings with peak amplitudes for robust speech recognition in noisy environments, In Proceedings IEEE international conference on acoustics, speech and signal processing (ICASSP), (pp. 61–64).
Krzanowski, W. J. (1987). Selection of variables to preserve multivariate data structure, using principal components. Journal of the Royal Statistical Society. Series C (Applied Statistics), 36(1), 22–33.
Lee, C.-C., Mower, E., Busso, C., Lee, S., & Narayanan, S. (2011). Emotion recognition using a hierarchical binary decision tree approach. Speech Communication, 53(9–10), 1162–1171.
Li, J.-B., Yang, Z.-M., Yu, Y., & Zhen, S. (2012). Semi-supervised kernel learning based optical image recognition. Optics Communications, 258(18), 3697–3703.
López-Cózar, R., Silovsky, J., & Kroul, M. (2011). Enhancement of emotion detection in spoken dialogue systems by combining several information sources. Speech Communication, 27(9–10), 1210–1228.
Luengo, I., Navas, E., & Hernáez, I. (2010). Feature analysis and evaluation for automatic emotion identification in speech. IEEE Transactions Multimedia, 12(6), 490–501.
Meyer, P., & Bontempi, G. (2006). On the use of variable complementarity for feature selection in cancer classification. In Evolutionary Computation and Machine Learning in Bioinformatics, (pp. 91–102).
Ni, D., Sethu, V., Epps, J., & Ambikairajah, E. (2012). Speaker variability emotion recognition - an adaptation based approach, In Proceedings IEEE international conference on acoustics, speech and signal processing (ICASSP), (pp. 5101–5104).
Ntalampiras, S., & Fakotakis, N. (2012). Modeling the temporal evolution of acoustic parameters for speech emotion recognition. IEEE Transactions Affective Computing, 3(1), 116–125.
Nwe, T. L., & Foo, S. W. (2003). Speech emotion recognition using hidden markov models. Speech Communication, 41(4), 603–623.
Park, J. S., Kim, J. H., & Oh, Y. H. (2009). Feature vector classification based speech emotion recognition for service robots. IEEE Transactions Consumer Electronics, 55(3), 1590–1596.
Peng, H., Long, F., & Ding, C. (2005). Feature selection based on mutual information: Criteria of max-dependency, max-relevance, and min-redundancy. IEEE Transactions Pattern Analysis and Machine Intelligence, 27(8), 1226–1238.
Pérez-Espinosa, H., & Reyes-García, C. A. (2012). Acoustic feature selection and classification of emotions in speech using a 3D continuous emotion model. Biomedical Signal Processing and Control, 7(1), 79–87.
Pérez-Espinosa, H., Reyes-García, C. A., & Villaseñor-Pineda, L. (2012). Acoustic feature selection and classification of emotions in speech using a 3D continuous emotion model. Biomedical Signal Processing and Control, 7(1), 79–87.
Pudil, P., Ferri, F. J., Novovicova, J., & Kittler, J. (1994). Floating search methods for feature selection with nonmonotonic criterion functions. Pattern Recognition Letters, 15(11), 1119–1125.
Raducanu, B., & Dornaika, F. (2012). A supervised non-linear dimensionality reduction approach for manifold learning. Pattern Recognition, 45(6), 2432–2444.
Rong, J., Li, G., & Chen, Y.-P. P. (2009). Acoustic feature selection for automatic emotion recognition from speech. Information Processing & Management, 45(3), 315–328.
Roweis, S., & Saul, L. (2000). Nonlinear dimensionality reduction by locally linear embedding. Science, 290(5500), 2323–2326.
Schuller, B., Steidl, S., & Batliner, A. (2010). The INTERSPEECH 2010 paralinguistic challenge, In Proceedings INTERSPEECH, (pp. 2794–2797).
Schuller, B., Steidl, S., & Batliner, A. (2011). The INTERSPEECH 2011 speaker state challenge feature set, In Proceedings INTERSPEECH.
Schuller, B., Steidl, S., & Batliner, A. (2012a). The INTERSPEECH 2012 speaker trait challenge feature set, In Proceedings INTERSPEECH.
Schuller, B., Steidl, S., & Batliner, A.. (2009) The INTERSPEECH 2009 emotion challenge feature set, In Proceedings INTERSPEECH, (pp. 983–986).
Schuller, B., Steidl, S., & Batliner, A. (2013). The INTERSPEECH 2013 computational paralinguistics challenge feature set, In Proceedings INTERSPEECH, (pp. 148–152).
Schuller, B., Vlasenko, B., Eyben, F., Wollmer, M., Stuhlsatz, A., Wendemuth, Andreas, et al. (2012b). Cross-corpus acoustic emotion recognition: Variances and strategies. IEEE Transactions Affective Computing, 1(2), 119–131.
Sethu, V., Ambikairajah, E., & Epps, J. (2007). Speaker normalization for speech -based emotion detection, In Proceedings IEEE international conference on digital signal processing, Cardiff, (pp. 611–614).
Shami, M., & Verhelst, W. (2007). An evaluation of the robustness of existing supervised machine learning approaches to the classification of emotions in speech. Speech Communication, 49(3), 201–212.
Shang, F., & Jiao, L. C. (2013). Semi-supervised learning with nuclear norm regularization. Pattern Recognition, 46(8), 2323–2336.
Siqing, W., Falk, T. H., & Chan, W. Y. (2011). Automatic speech emotion recognition using modulation spectral features. Speech Communication, 24(7), 768–785.
Sugiyama, M. (2006). Local fisher discriminant analysis for supervised dimensionality reduction, In Proceedings international conference on machine learning (ICML), (pp. 905–912).
The selected Speech Emotion Database of Institute of Automation Chinese Academy of Sciences (CASIA), http://www.datatang.com/data/39277
Vlasenko, B., Schuller, B., & Wendemuth, A. (2007). Frame vs. turn-level: Emotion recognition from speech considering static and dynamic processing, In Proceedings international conference on affective computing and intelligent interaction, (pp. 139–147).
Wang, Q., Yuen, P. C., & Feng, G. (2013). Semi-supervised metric learning via topology preserving multiple semi-supervised assumptions. Pattern Recognition, 46(9), 2576–2578.
Wu, C.-H., & Liang, W.-B. (2011). Emotion recognition of affective speech based on multiple classifiers using acoustic-prosodic information and semantic labels. IEEE Transactions Affective Computing, 2(1), 10–21.
Xiao, Z., Dellandrea, E., & Chen, L. (2009). Recognition of emotions in speech by a hierarchical approach, In Proceedings ACII, Amsterdam, (pp. 1–8).
Yeh, J.-H., Pao, T.-L., Lin, C.-Y., Tsai, Y.-W., & Chen, Y.-T. (2011). Segment-based emotion recognition from continuous Mandarin Chinese speech. Computers in Human Behavior, 27(5), 1545–1552.
Yun, S, & Yoo, C. D. (2012). Loss-scaled large-margin gaussian mixture models for speech emotion classification. IEEE Trans. Audio, Speech, and Language Processing, 20(2), 585–598.
Zelnik-Manor, L., & Perona, P. (2004). Self-tuning spectral clustering, In Proceedings advances in neural information processing systems (NIPS), (pp. 1601–1608).
Zhang, S., & Zhao, X. (2013). Dimensionality reduction-based spoken emotion recognition. Multimedia Tools and Applications, 63(3), 615–645.
Zhao, Z., & Liu, H. (2007). Spectral feature selection for supervised and unsupervised learning, In Proceedings international conference on machine learning (ICML), (pp. 1151–1157).
Zhao, Z., Wang, L., & Liu, H. (2010). Efficient spectral feature selection with minimum redundancy, In Proceedings AAAI conference on artificial intelligence, (pp. 673–678).
Zhao, M., Zhang, Z., & Chow, T. W. S. (2012). Trace ratio criterion based generalized discriminative learning for semi-supervised dimensionality reduction. Pattern Recognition, 45(4), 1482–1499.
Zheng, N., & Xue, J. (2009). Manifold learning. Statistical Learning and Pattern Analysis for Image and Video Processing, 87–119.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Sun, Y., Wen, G. Emotion recognition using semi-supervised feature selection with speaker normalization. Int J Speech Technol 18, 317–331 (2015). https://doi.org/10.1007/s10772-015-9272-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10772-015-9272-x