
Abstract
Consideration of visual speech features along with traditional acoustic features have shown decent performance in uncontrolled auditory environment. However, most of the existing audio-visual speech recognition (AVSR) systems have been developed in the laboratory conditions and rarely addressed the visual domain problems. This paper presents an active appearance model (AAM) based multiple-camera AVSR experiment. The shape and appearance information are extracted from jaw and lip region to enhance the performance in vehicle environments. At first, a series of visual speech recognition (VSR) experiments are carried out to study the impact of each camera on multi-stream VSR. Four cameras in car audio-visual corpus is used to perform the experiments. The individual camera stream is fused to have four-stream synchronous hidden Markov model visual speech recognizer. Finally, optimum four-stream VSR is combined with single stream acoustic HMM to build five-stream AVSR. The dual modality AVSR system shows more robustness compared to acoustic speech recognizer across all driving conditions.
















Similar content being viewed by others

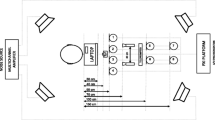

Notes
The data of eight microphone is not available in the database. Thus literally we can say the number of microphones is seven.
Some files of some speakers are missing due to equipment failure while recording.
References
Biswas, A., Sahu, P., Bhowmick, A., & Chandra, M. (2015). AAM based features for multiple camera visual speech recognition in car environment. Procedia Computer Science, 57, 614–621.
Biswas, A., Sahu, P. K., & Chandra, M. (2014). Admissible wavelet packet features based on human inner ear frequency response for hindi consonant recognition. Computers & Electrical Engineering (Elsevier), 40(4), 1111–1122.
Chien, J.-T., Lai, J.-R., Lai, P.-Y. (2001). Microphone array signal processing for far-talking speech recognition. In IEEE Third Workshop on Signal Processing Advances in Wireless Communications, (pp. 322–325).
Cootes, T. F., Edwards, G. J., & Taylor, C. J. (1998). Active appearance models (pp. 484–498). Lecture Notes in Computer Science Heidelberg: Springer.
Davis, S. B., & Mermelstein, P. (1980). Comparison of parametric representations for monosyllabic word recognition in continuously spoken sentences. In IEEE Transactions on Acoustic Speech Signal Process ASSP-28 (357–366).
Estellers, V., & Thiran, J.-P. (2012). Multi-pose lipreading and audio-visual speech recognition. EURASIP Journal on Advances in Signal Processing, 2012(1), 1–23.
Faubel, F., Georges, M., Kumatani, K., Bruhn, A., & Klakow, D. (2011). Improving hands-free speech recognition in a car through audio-visual voice activity detection. In Joint Workshop on Hands-free Speech Communication and Microphone Arrays (HSCMA), (pp. 70–75).
Gao, X., Su, Y., Li, X., & Tao, D. (2010). A review of active appearance models. IEEE Transactions on Systems, Man, and Cybernetics, Part C: Applications and Reviews, 40(2), 145–158.
Irwin, A. (2008). Investigating the effects of accent on visual speech, Ph.D. thesis, University of Nottingham.
Kaynak, M. N., Zhi, Q., Cheok, A. D., Sengupta, K., Jian, Z., & Chung, K. C. (2004). Lip geometric features for human-computer interaction using bimodal speech recognition: comparison and analysis. Speech Communication, 43(1), 1–16.
Kleinschmidt, T., Dean, D., Sridharan, S., Mason, M. (2007). A continuous speech recognition evaluation protocol for the AVICAR database. In In proceedings of the International Conference on Signal Processing and Communication Systems (pp. 339–344).
Lee, K. F., & Hon, H. W. (1989). Speaker-independent phone recognition using hidden Markov models. IEEE Transactions of Acoustics, Speech and Signal Processing, 37(14), 1641–1648.
Lee, B., Hasegawa-Johnson, M., Goudeseune, C., Kamdar, S., Borys, S., Liu, M., & Huang, T. S. (2004). AVICAR: Audio-visual speech corpus in a car environment. In INTERSPEECH (pp. 2489–2492). Jeju Island.
Lucey, P., & Potamianos, G. (2006). Lipreading using profile versus frontal views. In IEEE 8th Workshop on Multimedia Signal Processing (pp. 24–28).
Navarathna, R., Dean, D., Sridharan, S., & Lucey, P. (2013). Multiple cameras for audio-visual speech recognition in an automotive environment. Computer Speech & Language, 27(4), 911–927.
Navarathna, R., Dean, D. B., Lucey, P. J., Sridharan, S., & Fookes, C. B. (2010). Recognising audio-visual speech in vehicles using the AVICAR database. In Proceedings of the 13th Australasian International Conference on Speech Science and Technology, The Australasian Speech Science & Technology Association (pp. 110–113).
Navarathna, R., Kleinschmidt, T., Dean, D. B., Sridharan, S., & Lucey, P. J. (2011). Can audio-visual speech recognition outperform acoustically enhanced speech recognition in automotive environment? In In Interspeech, (pp. 2241–2244).
Potamianos, G., & Neti, C. (2003) Audio-visual speech recognition in challenging environments. In INTERSPEECH (pp. 1293–1296).
Potamianos, G., Neti, C., Luettin, J., & Matthews, I. (2004). Audio-visual automatic speech recognition: An overview. Issues in Visual and Audio-Visual Speech Processing, 22, 23.
Potamianos, G., & Lucey, P. (2006). Audio-visual asr from multiple views inside smart rooms. In IEEE International Conference on Multisensor Fusion and Integration for Intelligent Systems (pp. 35–40).
Stewart, D., Seymour, R., Pass, A., & Ming, J. (2014). Robust audio-visual speech recognition under noisy audio-video conditions. IEEE Transactions on Cybernetics, 44(2), 175–184.
Viola, P., Jones, M. (2001). Rapid object detection using a boosted cascade of simple features. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, (Vol. 1, pp. 511–518).
Acknowledgments
This work is supported by the Department of Electronics and Information Technology, Government of India. We are thankful to the volunteers for their tremendous efforts to annotate the frame sequences.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Biswas, A., Sahu, P.K. & Chandra, M. Multiple cameras audio visual speech recognition using active appearance model visual features in car environment. Int J Speech Technol 19, 159–171 (2016). https://doi.org/10.1007/s10772-016-9332-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10772-016-9332-x