
Abstract
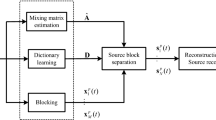
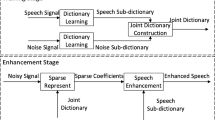
The cross projection engenders when mixed speech signal is represented over joint dictionary because of the bad distinguishing ability of joint dictionary in single-channel blind source separation (SBSS) using sparse representation theory, which leads to bad separation performance. A new algorithm of constructing joint dictionary with common sub-dictionary is put forward in this paper to this problem. The new dictionary can effectively avoid being projected over another sub-dictionary when a source signal is represented over joint dictionary. In the new algorithm, firstly we learn identify sub-dictionaries using source speech signals corresponding to each speaker. And then we discard similar atoms between two identity sub-dictionaries and construct a common sub-dictionary using these similar atoms. Finally, we combine those three sub-dictionaries together into a joint dictionary. The Euclidean distance among two atoms is used to measure the correlation of them in different identity sub-dictionaries, and similar atoms are searched based on the correlation. In testing stage, each source can be reconstructed with the projection coefficients corresponding to individual sub-dictionary and the common sub-dictionary. Contrast experiments tested in speech database show that the algorithm proposed in this paper performs better, when the Signal-to-Noise Ratio (SNR) is used to measure separation effect. The algorithm set out in this paper has lower time complexity as well.










Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.References
Agrawal, A., Raskar, R., & Chellappa, R. (2006). Edge suppression by gradient field transformation using cross-projection tensors computer vision and pattern recognition, 2006 IEEE Computer Society Conference on. IEEE, 2301–2308.
Bao, G., Xu, Y., & Ye, Z. (2014). Learning a discriminative dictionary for single-channel speech separation. IEEE/ACM Transactions on Audio Speech & Language Processing, 22(7), pp. 1130–1138.
Bofill, P., & Zibulevsky, M. (2001). Underdetermined blind source separation using sparse representations. Signal Processing, 81(11), 2353–2362.
Grais, E., Erdogan, H. (2013). Discriminative nonnegative dictionary learning using cross-coherence penalties for single channel source separation (pp. 808–812). France: INTERSPEECH, Lyon.
Lian, Q., Shi, G., & Chen, S. (2015). Research progress of dictionary learning model, algorithm and its application. Journal of Automation, 41(2), 240–260.
Michal, A., Elad, M. (2006). K-SVD: An algorithm for designing overcomplete dictionaries for sparse representation. IEEE Transactions on Signal Processing, 54(11), 4311–4322.
Rambhatla, S., Haupt, J. (2014). Semi-blind source separation via sparse representations and online dictionary learning. In 2013 Asilomar conference on signals, systems and computers (pp. 1687–1691). IEEE.
Roweis, S. (2000). One microphone source separation, NIPS, pp. 793–799.
Shapoori, S., Sanei, S., & Wang, W. (2015). Blind source separation of medial temporal discharges via partial dictionary learning. In 2015 IEEE 25th International workshop on machine learning for signal processing (MLSP), Boston, MA, pp. 1–5.
Tan, H., & Liu, H. L. (2007). On recoverability of blind source separation based on sparse representation. Journal of Guangdong University of Technology, 2008(02), 44–46.
Tang, S., Guo, H., Zhou, N., Huang, L., & Zhan, T. (2016). Coupled dictionary learning on common feature space for medical image super resolution, 2016 IEEE International Conference on Image Processing (ICIP)., Phoenix, AZ, pp. 574–578.
Tang, Y., Chen, Y., & Xu, N., et al. (2015). Speech reconstruction via sparse representation using harmonic regularization. IEEE: International Conference on Wireless Communications and Signal Processing, pp. 1–4.
Tian, Y., Wang, X., & Zhou, Y. (2017). A new algorithm for single channel blind source separation based on sparse representation. Journal of Electronics and Information, 39(6), 1371–1378.
Vincent, E., Gribonval, R., & Fevotte, C. (2006). Performance measurement in blind audio source separation. IEEE Transactions on Audio Speech and Language Processing, 14(4), 1462–1469.
Xu, L., Yang, Z., & Shao, X. (2015). Dictionary design in subspace model for speaker identification. International Journal of Speech Technology, 18(2), 177–186.
Yang, M., Zhang, L., Yang, J., & Zhang, D. (2010). Metaface learning for sparse representation based face recognition. IEEE International Conference on Image Processing, 1601–1604.
Yang, Z., Yang, Z., & Sun, L. (2013). A review of orthogonal matching pursuit algorithms for signal compression reconstruction. Signal Processing, 29(4), 486–496.
Yu, F., Xi, J., & Zhao, L., et al. (2011). Analysis of sparse component underdetermined blind source separation based on CS and K-SVD. Journal of Southeast University, 41(6), 1127–1131.
Yu, X., Hu, D., & Xu, J. (2013). Blind Source Separation: Theory and Applications. Journal of the Acoustical Society of America, 105(2), 1101–1102.
Zhen, L., Peng, D., & Yi, Z., et al. (2016). Underdetermined blind source separation using sparse coding. IEEE Transactions on Neural Networks and Learning Systems, 99, 1–7.
Acknowledgements
This work is supported by the National Natural Science Foundation of China (No.61501251), the Natural Science Foundation of Jiangsu Province (BK20140891) and the Scientific Research Foundation of Nanjing University of Posts and Telecommunications (NY214038).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Sun, L., Zhao, C., Su, M. et al. Single-channel blind source separation based on joint dictionary with common sub-dictionary. Int J Speech Technol 21, 19–27 (2018). https://doi.org/10.1007/s10772-017-9469-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10772-017-9469-2