
Abstract
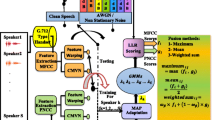
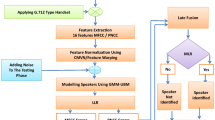
In automatic speaker recognition (SR) tasks the widely used score level combination scheme derives a general consensus from the independent opinions of individual evidences. Instead, we conjecture that collectively contributed decisions may be more effective. Based on this idea this work proposes an effective combination scheme, where the vocal-tract and excitation source information take decisions collectively, resulting higher improvements in SR accuracy. In the proposed scheme, independently made feature-specific models are padded for building resultant models. While testing, feature-specific test features are padded in similar fashion, and then used for comparison with resultant models. The main advantage of this proposed scheme is that it does not require any ground truth information for combined use of multiple evidences like in score level combination scheme. The potential of the proposed scheme is experimentally demonstrated by conducting different speaker recognition experiments in clean and noisy conditions, and also comparative studies with score level fusion scheme as reference. The TIMIT database is used for studies with clean case, and Indian Institute of Technology Guwahati Multi-Variability (IITG-MV) databases for noisy case. In clean case the proposed scheme provides relatively 1% of higher improvements in performance for GMM based speaker identification system and 8.5% for GMM–UBM based speaker verification system. In noisy case the corresponding parameters are 1% and 3%, respectively. The final evaluations on NIST-2003 database with GMM–UBM and i-vector based systems show relatively higher improvements in performance by 5.17% and 4.73%, respectively. The proposed scheme is observed to be statistically more significant than the commonly used score level fusion of multiple evidences.





Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.References
Altnccay, H., & Demirekler, M. (2000). An information theoretic framework for weight estimation in the combination of probabilistic classifiers for speaker identification. Speech Communication, 30(4), 255–272.
Altnccay, H., & Demirekler, M. (2003). Speaker identification by combining multiple classifiers using dempster-shafer theory of evidence. Speech Communication, 41(4), 531–547.
Atal, B. S. (1976). Automatic recognition of speakers from their voices. Proceedings of the IEEE, 64(4), 460–475.
Beigi, H. (2011). Fundamentals of speaker recognition. Berlin: Springer.
Campbell, J. P. (1997). Speaker recognition: A tutorial. Proceedings of IEEE, 85(9), 1437–1462.
Campbell, W. M., Sturim, D. E., & Reynolds, D. A. (2006). Support vector machines using GMM supervectors for speaker verification. IEEE Signal Processing Letters, 13(5), 308–311.
Das, R. K., & Prasanna, S. R. M. (2016). Exploring different attributes of source information for speaker verification with limited test data. The Journal of the Acoustical Society of America, 140(1), 184–190.
Dehak, N., Kenny, P. J., Dehak, R., Dumouchel, P., & Ouellet, P. (2011). Front-end factor analysis for speaker verification. IEEE Transactions on Audio, Speech, and Language Processing, 19(4), 788–798.
Djemili, R., Bedda, M., & Bourouba, H. (2007). A hybrid gmm/svm system for text independent speaker identification. International Journal of Computer and Information Science & Engineering, 1(1).
Duda, R. O., Hart, P. E., & Stork, D. G. (1973). Pattern classification and scene analysis. New York: Wiley.
Farrell, K., Kosonocky, S., & Mammone, R. (1994). Neural tree network/vector quantization probability estimators for speaker recognition. In Proceedings of the 1994 IEEE workshop on neural networks for signal processing, pp. 279–288.
Feustel, T. C., Logan, R. J., & Velius, G. A. (1988). Human and machine performance on speaker identity verification. The Journal of the Acoustical Society of America, 83(S1), S55–S55.
Furui, S. (1981). Cepstral analysis technique for automatic speaker verification. IEEE Transactions on Acoustic, Speech, and Signal Processing, 29, 254–272.
Garofolo, J. S., Lamel, L. F., Fisher, W. M., Fiscus, J. G., Pallett, D. S., Dahlgren, N. L., et al. (1993). Timit acoustic-phonetic continuous speech corpus. Philadelphia: Linguistic data consortium.
Haris, B. C., Pradhan, G., Misra, A., Prasanna, S. R. M., Das, R. K., & Sinha, R. (2012). Multi-variability speaker recognition database in Indian scenario. International Journal of Speech Technology, 15(4), 441–453.
Hermansky, H., & Morgan, N. (1994). Rasta processing of speech. IEEE Transactions on Speech and Audio Processing, 2(4), 578–589.
Hosseinzadeh, D., & Krishnan, S. (2007). Combining vocal source and mfcc features for enhanced speaker recognition performance using gmms. In IEEE 9th Workshop on Multimedia Signal Processing, pp. 365–368.
Kenny, P., Boulianne, G., Ouellet, P., & Dumouchel, P. (2007). Speaker and session variability in gmm-based speaker verification. IEEE Transactions on Audio Speech and Language Processing, 15(4), 1448.
Kenny, P., Boulianne, G., Ouellet, P., & Dumouchel, P. (2007). Joint factor analysis versus eigenchannels in speaker recognition. IEEE Transactions on Audio, Speech, and Language Processing, 15(4), 1435–1447.
Linguistic data consortium, switchboard cellular part 2 audio. (2004). Retrieved from, http://www.ldc.upenn.edu/Catalog/CatalogEntry.jspcatalogId=LDC2004S07.
Martin, A., Doddington, G., Kamm, T., Ordowski, M., & Przybocki, M. (1997). The det curve in assessment of detection task performance. In Technical Report, National Institute of Standards and Technology Gaithersburg MD.
Mashao, D. J., & Skosan, M. (2006). Combining classifier decisions for robust speaker identification. Pattern Recognition, 39(1), 147–155.
Murty, K. S. R., & Yegnanarayana, B. (2006). Combining evidence from residual phase and mfcc features for speaker recognition. IEEE Signal Processing Letters, 13(1), 52–55.
Nakagawa, S., Wang, L., & Ohtsuka, S. (2012). Speaker identification and verification by combining mfcc and phase information. IEEE Transactions on Audio, Speech, and Language Processing, 20(4), 1085–1095.
Neyman, J. (1937). Outline of a theory of statistical estimation based on the classical theory of probability. Philosophical Transactions of the Royal Society of London A, 236(767), 333–380.
Pati, D., & Prasanna, S. R. M. (2010). Speaker recognition from excitation source perspective. IETE Technical Review, 27(2), 138–157.
Pati, D., & Prasanna, S. R. M. (2011). Subsegmental, segmental and suprasegmental processing of linear prediction residual for speaker information. International Journal of Speech Technology, 14(1), 49–64.
Pati, D., & Prasanna, S. R. M. (2013). A comparative study of explicit and implicit modelling of subsegmental speaker-specific excitation source information. Sadhana, 38(4), 591–620.
Poh, N., & Kittler, J. (2008). Incorporating model-specific score distribution in speaker verification systems. IEEE Transactions on Audio, Speech, and Language Processing, 16(3), 594–606.
Prasanna, S. R. M., Gupta, C. S., & Yegnanarayana, B. (2006). Extraction of speaker-specific excitation information from linear prediction residual of speech. Speech Communication, 48(10), 1243–1261.
Ramachandran, R. P., Farrell, K. R., Ramachandran, R., & Mammone, R. J. (2002). Speaker recognition-general classifier approaches and data fusion methods. Pattern Recognition, 35(12), 2801–2821.
Ramakrishnan, A., Abhiram, B., & Prasanna, S. R. M. (2015). Voice source characterization using pitch synchronous discrete cosine transform for speaker identification. The Journal of the Acoustical Society of America, 137(6), EL469–EL475.
Reynolds, D. (1995). Speaker identification and verification using Gaussian mixture speaker models. Speech Communication, 17, 91–108.
Reynolds, D. A. (1995). Large population speaker identification using clean and telephone speech. IEEE Signal Processing Letters, 2(3), 46–48.
Reynolds, D. A., Quatieri, T. F., & Dunn, R. B. (2000). Speaker verification using adapted Gaussian mixture models. Digital Signal Processing, 10(1–3), 19–41.
The 2003 Nist speaker recognition evaluation plan (2003). In Proceedings of NIST Speaker Recognition Workshop, College Park, MD.
Venturini, A., Zao, L., & Coelho, R. (2014). On speech features fusion, α-integration Gaussian modeling and multi-style training for noise robust speaker classification. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 22(12), 1951–1964.
Wong, L. P., & Russell, M. (2001). Text-dependent speaker verification under noisy conditions using parallel model combination. In Proceedings of IEEE International Conference on Acoustics, Speech, and Signal Processing(ICASSP01), 1, 457-460.
Yegnanarayana, B., Prasanna, S. R. M., Zachariah, J. M., & Gupta, C. S. (2005). Combining evidence from source, suprasegmental and spectral features for a fixed-text speaker verification system. IEEE Transactions on Speech and Audio Processing, 13(4), 575–582.
Yegnanarayana, B., Reddy, K. S., & Kishore, S. P. (2001). Source and system features for speaker recognition using ANNN models. In Proceedings of Acoustics, Speech, and Signal Processing (ICASSP-01) (Vol. 1, pp. 409–412).
Acknowledgements
This research work is funded by Department of Electronics and Information Technology (DeitY), Govt. of India through the project “Development of Excitation Source Features Based Spoof Resistant and Robust Audio-Visual Person Identification System”. The research work is carried out in Speech Processing and Pattern Recognition (SPARC) laboratory at National Institute of Technology Nagaland, Dimapur, India.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Dutta, K., Mishra, J. & Pati, D. Effective use of combined excitation source and vocal-tract information for speaker recognition tasks. Int J Speech Technol 21, 1057–1070 (2018). https://doi.org/10.1007/s10772-018-09568-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10772-018-09568-4