
Abstract
In this work, a speaker identification system is proposed which employs two feature extraction models, namely: the power normalized cepstral coefficients and the mel frequency cepstral coefficients. Both features are subjected to acoustic modeling using a Gaussian mixture model–universal background model. The purpose of this work is to provide a thorough evaluation of the effect of different types of noise on the speaker identification accuracy (SIA) and thereby providing benchmark figures for future comparative studies. In particular, the additive white Gaussian noise and eight non-stationary noise types (with and without the G.712 type handset) corresponding to various signal to noise ratios are tested. Fusion strategies are also employed using late fusion methods: maximum, weighted sum, and mean fusion. The measurements of randomly selected 120 speakers from the TIMIT database are employed and the SIA is used to measure the system performance. The weighted sum fusion resulted in the best performance in terms of SIA with noisy speech. The proposed model given in this work and its related analysis paves the way for further work in this important area.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Several biometrics traits have been proposed employing various traits (Chaki et al. 2019) such as speech biometric (Sun et al. 2019), fingerprint (Rajeswari et al. 2017), finger texture (Al-Nima et al. 2017), face (Sghaier et al. 2018), signature (Morales et al. 2017), human ear and palmprint (Hezil and Boukrouche 2017), sclera (Alkassar et al. 2015) and iris pattern (Abdullah et al. 2015).
An important application in biometrics and forensics is to identify speakers based on their unique voice pattern which is known as speaker recognition (Togneri and Pullella 2011). There are many areas where this technique can be successfully applied for security and investigation perspective including forensics, remote access control, web services and online banking (El-Ouahabi et al. 2019).
Traditionally, speaker recognition systems were developed and tested in a clean speech environment. However, in many applications of speaker recognition, the speech samples provided to the system may suffer from different types of noise. In order to achieve a robust speaker identification, the effect of noise should be investigated as the noise can badly affect the performance of a speaker recognition system (Ming et al. 2007). According to Verma and Das (2015), feature extraction within speaker identification should be less influenced by noise or the person’s health.
In this work, we present a thorough evaluation for the TIMIT database under a wide range of environmental noise conditions, hence, providing benchmark evaluations for other researchers working in the speaker identification field. In summary, our contributions are as follows.
-
Eight NSN types, as well as the AWGN with and without the G.712 type handset are investigated.
-
The relation between the SIAs for eight NSN and AWGN with the signal to noise ratios (SNRs) is measured.
-
Quantitative and qualitative perspectives for different background noise and handset effects on the SIA for the TIMIT database.
-
Various fusion methods are employed to boost the speaker recognition performance.
The rest of this work is organized as follows. Section 2 presents related work. In Sect. 3, the schematic diagram of the proposed method is given. Section 4 presents the late fusion method while the noise and handset effect is given in Sect. 5. The simulation results and discussion are presented in Sect. 6. Finally, Sect. 7 concludes this work.

The fusion based speaker identification system using GMM–UBM
2 Related work
There exist some work in the literature that covers the noise effect of speaker recognition. However, efforts have rarely been made on the combined effects of various types of noise with and without the handset effect. In this context, an automatic speech recognition system is investigated in Yadav et al. (2019) by using the front-end to the speech parameterization technique which is less sensitive towards pitch variations and ambient noise. For this purpose, a variational mode decomposition (VMD) was employed in order to break up the magnitude spectrum into several components. Thereby the ill-effects of noise and pitch variations are suppressed to produce a sufficiently smoothed spectrum.
The work in Univaso (2017), presented a tutorial for the speaker identification task with various features, modeling and classification methods for forensic application. However, the noise effect is not considered as well. In Chin et al. (2017), two main components are presented for speaker identification namely: the Sparse Representation Classifier (SRC) and the feature extraction. In addition, the probabilistic Principal Component Analysis (PCA) and Bartlett test are employed to extract the i-vector with high quality. However, realistic noise was not involved and the method yielded low accuracy. The system in Ma et al. (2016) outperformed the traditional Gaussian Mixture Model (GMM) but the work has not taken the noise into consideration. The work in Al-Kaltakchi et al. (2017) evaluated both the TIMIT and the Network TIMIT (NTIMIT) databases for speaker identification in order to measure the SIA. However, only original speech recording are used while noise and handset effects are not considered.
The authors in Al-Kaltakchi et al. (2016) utilized the power normalized cepstrum coefficient (PNCC)to provide robustness for additive white gaussian noise (AWGN). In addition, the MFCC was employed in order to give better speaker identification accuracy (SIA) in terms of the original speech recordings (OSR). The Fusion between the MFCC and PNCC were applied in order to give higher SIA. In addition, to mitigate the linear channel effects, normalization is utilized by applying the cepstral mean and variance normalization (CMVN) as well as the Feature Warping (FW). In Ma et al. (2016), a super-MFCCs features are employed in order to capture the dynamic information by cascading three adjacent frames of MFCCs. Then a novel probabilistic method is used by applying the probability density function (PDF) to the super-MFCCs features for text-independent speaker identification. The PDF is estimated by the proposed Histogram Transform (HT) techniques, which provides more training data to solve the discontinuity problem that occurs in the multivariate histograms computing.
It is clear from the previous literature that more work is required in order to clarify the effect of noise on speaker identification performance. Therefore, in this work, we present a thorough evaluation of the TMIT database under a wide range of noise including various NSN types as well as the AWGN with and without the G.712 handset effect.
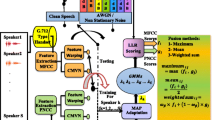
3 The schematic diagram of the proposed algorithm
The proposed system diagram is shown in Fig. 1. The G.712 type handset is applied and the two feature extraction methods are employed (MFCC and PNCC). Using the MFCC and PNCC methods made the proposed system capable of working with both noisy and clear speech environment.
3.1 Feature extraction and normalization
A 16-feature dimension is used to mirror the work in Al-Kaltakchi et al. (2017), which used both MFCC and PNCC. In addition, the MFCC features included the zero order \(C_0\) coefficient and the PNCC features included the \(Pc_0\) coefficient. A pre-emphasis finite impulse response (FIR) filter realizing a first order high-pass filter was employed to filter the speech samples with an emphasis coefficient of 0.96 (Kumari and Nidhyananthan 2012). In addition, framing and Hamming windowing are employed with a frame length of 16 ms and an inter-frame overlap of 8 ms (Nijhawan and Soni 2013). A summary of these details are given in Table 3.
The reason for selecting the MFCC is because it gives better accuracy with clean speech while the PNCC provides robustness toward the noisy speech. Hence, combing these together, results in a robust recognition system. The comparisons between features extraction and feature normalization methods are explained in Tables 1 and 2. Table 1 compares the MFCC and the PNCC feature. On the other hand, the comparison between feature warping and the CMVN is given in Table 2.
3.2 GMM–UBM modeling
The GMM is one of the early methods that was used for modeling paradigms in speaker recognition. This method suffered from unseen and insufficient data, therefore a limitation for increasing the Gaussian mixture dimension appeared and this caused degradation in speaker identification system when the number of speakers increased. The GMM–UBM was proposed to solve the drawback effects of using GMM (Togneri and Pullella 2011; Hasan and Hansen 2011).
The coupling between the GMM and UBM models are conducted as follows. A small data was trained by using Maximum A Posteriori (MAP) approach adaptation to train the individual speaker models. While large data were trained using Universal Background Model (GMM–UBM) through expectation maximization. The coupling between large training data (UBM) and a small amount of class specific data (individual speaker models) makes the GMM–UBM able to estimate a larger number of parameters which increases the mixture size dimension, and thus increases the SIA (Hasan and Hansen 2011).
Furthermore, the maximum likelihood ratio between the training and testing were utilized to decide if the speaker is a genuine speaker or fake. Then, the SIA is calculated based on the total number of true speakers identified and the total number of speakers (Al-Kaltakchi et al. 2017).
4 Late fusion (score based) techniques
In this work, three fusion methods are employed in order to enhance the performance. These methods are: maximum, weighted sum and mean fusion. The equations of the maximum, weighted sum and mean fusion are given in Eqs. 1, 2 and 3, respectively.
where \(\varvec{fmax}_{ij}\) is the score vectors for the fusion maximum.
where, i, j = 1 and 2. \(\varvec{fweight}_{ij}\) can take any of the values \(\varvec{fweight}_{11}\), \(\varvec{fweight}_{12}\), \(\varvec{fweight}_{21}\) and \(\varvec{fweight}_{22}\). For example, \(\varvec{fweight}_{11}\) is the linear combination of both \(\varvec{f}_{1}\) and \(\varvec{g}_{1}\). similarly, \(\varvec{fweight}_{12}\) is the linear combination of \(\varvec{f}_{1}\) and \(\varvec{g}_{2}\) and so on. Furthermore, \(\varvec{fweight}_{ij}\), \(\omega _{\beta }\) can take any of the values so that , \(\omega _{\beta } \in \{0.7,0.77,0.8,0.9\}\) which is empirically selected to attain the best SIA.
5 Noise and handset effects
5.1 Stationary and non-stationary noise
Basically, it is important to study the system in realist noise conditions. Therefore, stationary noise like AWGN and NSN were added during the testing phase. In this work, the NSN available online from the http://www.findsounds.com/ and https://www.freesfx.co.uk/ are used to test the system. Furthermore, all stationary and non stationary noise were trimmed to mirror the original speech recordings with a fixed size equal to 8 seconds.
5.2 G.712 type handset effects
A G.712 type handset at 16 kHz and 8 kHz with a fourth order linear IIR filter is applied to the speech signal during both the training and testing stages. The main reason for applying this distortion is to achieve a robust SIA by testing the proposed system under noisy channel conditions. The transfer function of the G.712 can be written as in Togneri and Pullella (2011):

SIA versus SNR for non-stationary noise types: a street-traffic, b metro-interior, c shopping-square, d airplane-interior

SIA versus SNR for non-stationary noise types: a train pass, b bus-interior, c restaurant, d crowd-talking
where denominator parameters are [1, − 0.2288945, − 1.29745904, 0.06100624, 0.57315888], and the numerator parameters are [1, − 0.0216047, − 1.92904276, − 0.0216047, 1].

Comparison of all stationary and non stationary noise types for a without handset b with G.712 type handset at 16 kHz c with G.712 type handset at 8 kHz

Comparison of different fusion method in term of the SIA with and without handset effect

Frequency analysis and spectrogram for all non stationary noise types using the GoldWave and the audacity software with Hamming window of 256 in size. Note1-a, 2-a, 3-a, and 4-a represent the frequency analysis while 1-b, 2-b, 3-b and 4-b represent the spectrogram for street NSN, metro interior NSN, shopping-square and airplane NSN, respectively for the duration of 8 second

Frequency analysis and Spectrogram for all Non Stationary Noise types using the GoldWave and the Audacity software with Hamming window size 256. Note1-a, 2-a, 3-a, and 4-a represent the frequency analysis while 1-b, 2-b, 3-b and 4-b represent the spectrogram for train pass NSN, bus interior NSN, restaurant and Crowd talking NSN, respectively for the duration of 8 s

The spectrogram of the test speech file from the TIMIT database (8 s length) for the clean speech and the spectrogram of the test speech with G.712 at 16 KHz under AWGN of 30 dB, 25 dB, 20 dB, 15 dB, 10 dB, 5 dB and 0 dB, respectively
6 Simulation results and discussion
6.1 The setup parameters
The setup parameters for this work are presented according to the following: Speech details, preprocessing parameters, Speakers details, Database, Training and testing details, Dialect region, Feature normalization, Classifier, SNR levels in dB. Table 3 shows all the parameters used in this work. All experiments are conducted by randomly selecting 120 speakers from the TIMIT database.
6.2 Discussion
Figures 2 and 3 show the SIAs in presence of G.712 type handset at both 8 kHz and 16 kHz. The results presented in Figs. 2 and 4 were selected from the best SIA of each SNR level among all fusion methods. It can be noted that higher SIAs are achieved without the G.712 handset effect. Using the G.712 type handset at 8 kHz achieved lower SIAs compared to the same effect at 16 kHz. This is due to the lower cutoff frequency at 16kHz than those corresponding to 8 kHz. Hence, the higher the frequency of the G.712 handset, the better the SIA. In addition, the SIA is increased with gradual increment in SNR, and the highest SIA is achieved at SNR equals to 30 dB.
In addition, Fig. 4 illustrates the relationship between the SIA and the SNR as well as gives a comparison of all stationary (AWGN) and NSN types without the handset and with the handset at 8 kHz and 16 kHz. It can be noted from Fig. 4 that the highest SIA value are achieved with bus-interior noise, while the lowest SIA is recorded with the AWGN. This is because the AWGN gives a constant noise spectrum which is easier to process and difficult to identify speakers compared with lower and variable noise spectrum in the NSN. Furthermore, increasing and the highest SIA is achieved at 30 dB. Also, the highest noise distribution is represented by the AWGN and the lowest noise distribution is obtained with the Bus interior NSN. Ithe SNR increases the SIAn addition, the results from Fig. 4 are selected according to the best fusion methods selected for each SNR level, based on maximum, mean, and weighted sums of weights 0.9, 0.8, 0.77 and 0.7.
Figure 5 shows the best fusion method in terms of the SIA in the absence and presence of the handset effect. The best SIAs are: 75.83%, 95%, 90.83%, 92.5%, 93.33%, 92.5%, 92.5%, 94.17%, 89.17%, 91.67% for AWGN, Original Speech Recordings (OSR), Street traffic, Metro-interior, Shopping square, Airplan-interior, Train pass, Bus-interior, Restaurant, Crowd talking NSN without a handset, respectively. According to Fig. 5, the Weighted Sum Fusion (WSF) achieved the best results for all the cases except for the AWGN and bus interior. Furthermore, we can observe that increasing the SNR is also increases the SIA in Fig. 5.
6.3 Qualitative perspective for noise and handset effects
In this section, the qualitative view are provided by studying the natural speech characteristic under the noise and the handset conditions using the spectrogram and the spectrum analysis. Figures 6 and 7 illustrate the spectrum and the spectrogram for only the NSN types (eight types). A Hamming window with a size of 256 is used for all figures used in this section. Audacity and Gold Wave software are employed to generate these figures. In addition, the spectrogram for test speech with handset under the AWGN with different SNR levels (0, 5, 10, 15, 20, 25, 30) dB is shown in Fig. 8. The spectrogram is the most common visual representation techniques for acoustic signal since it contains almost all data necessary for analyzing and describing the acoustic information. The spectrogram displays the spectral data over time. The vertical axis shows the frequency components while the horizontal axis displays the duration of sound.
According to Fig. 8, the spectrogram of the test file from TIMIT database is taken under: Original Speech Recordings (OSR), and AWGN with G.712 handset for SNR levels (0, 5, 10, 15, 20, 25, 30) dB. The clean speech is represented by the blue color, while different shades of the red color reflect the strength of different noise levels. The highest noise level occurs at 0 dB and the lowest noise level at 30 dB where the white color shows the features of the speech data. In Fig. 8, the handset effect is not clear because its effect is limited to the energy bandwidth for the speech signal. This causes a distortion in the low and high cutoff frequencies and hence part of the energy of the signal will be lost, and as a result reduce the performance of the system. Both Figures 6 and 7 show the spectrogram and spectrum for the Bus NSN which has fewer components of noise compared with street and crowd talking NSN and therefore gives the highest SIA compared with other types of NSN.
6.4 Comparisons
Table 5 summarizes the few works that considered the speaker recognition performance in presence of the noise. Tongneri and Pullella Togneri and Pullella (2011) examined the speaker recognition performance for 64 speakers from the TIMIT database under the effect of the AWGN at 8 KHz only using the G.712 handset. Similarly, Tazi and El-Makhfi (2017) employed a self-collected dataset of 51 speakers to investigated the effect of the AWGN without using the handset effect. Also, Faragallah (2018) used 80 speakers from a self-collected database to explore the speaker recognition performance under the AWGN without using the handset effect. On the other hand, Ming et al. (2007) employed 630 speakers from the TIMIT database and investigated the performance under the street noise without using the G.712 handset (Table 4).
Although there are some attempts in the literature to investigate the effect of noise of the speaker recognition performance, these works are limited to one or two types of noise only. In addition, the aforementioned works do not consider employing the handset effect at different frequency. To the best of our knowledge, this work is amongst the first in literature which investigate the speaker recognition performance under a wide range of environmental noise exploiting the G.712 handset effect at both 8 KHz and 16 KHz.
7 Conclusion
In this work, we presented a thorough evaluation of the effect of different types of noise on the Speaker Identification Accuracy (SIA) using 120 speakers from the TIMIT database. In particular, the additive white Gaussian noise (AWGN) and eight Non-Stationary Noise (NSN) types (with and without the G.712 type handset) corresponding to various Signal to Noise Ratios (SNRs) are tested. Fusion strategies are also employed and the Weighted Sum Fusion (WSF) resulted in the best performance in terms of SIA with noisy speech.
The proposed system employed two feature extraction models, namely: The Power Normalized Cepstral Coefficients (PNCC) and the Mel Frequency Cepstral Coefficients (MFCC). Both features are subjected to acoustic modeling using a Gaussian Mixture Model-Universal Background Model (GMM–UBM). The AWGN was found to be the most effective in terms of degrading the recognition performance compared with other types of noise. The summary of all the experiments are illustrated in Table 5. The proposed model given in this work and its related comparisons provides benchmark figures for future comparative studies in the field of speaker recognition.
Our future work will focus on employing the i-vector for speaker modeling in addition to utilizing the extreme learning machine (ELM) classifier. Experiments will be conducted on two additional databases namely the NIST 2008 and speaker in the wild (SITW) databases.
References
Abdullah, M.A., Chambers, J.A., Woo, W.L., & Dlay, S.S. (2015). Iris biometrie: Is the near-infrared spectrum always the best? In: 2015 IEEE 3rd IAPR Asian conference on pattern recognition (ACPR) (pp. 816–819). IEEE.
Al-Kaltakchi, M.T., Woo, W.L., Dlay, S.S., & Chambers, J.A. (2016). Study of statistical robust closed set speaker identification with feature and score-based fusion. In: 2016 IEEE statistical signal processing workshop (SSP) (pp. 1–5). IEEE.
Al-Kaltakchi, M.T., Woo, W.L., Dlay, S.S., & Chambers, J.A. (2017). Speaker identification evaluation based on the speech biometric and i-vector model using the timit and ntimit databases. In: 2017 IEEE 5th international workshop on biometrics and forensics (IWBF) (pp. 1–6). IEEE.
Al-Kaltakchi, M. T., Woo, W. L., Dlay, S., & Chambers, J. A. (2017). Evaluation of a speaker identification system with and without fusion using three databases in the presence of noise and handset effects. EURASIP Journal on Advances in Signal Processing, 2017(1), 80.
Al-Nima, R. R. O., Abdullah, M. A., Al-Kaltakchi, M. T., Dlay, S. S., Woo, W. L., & Chambers, J. A. (2017). Finger texture biometric verification exploiting multi-scale sobel angles local binary pattern features and score-based fusion. Digital Signal Processing, 70, 178–189.
Alkassar, S., Woo, W. L., Dlay, S. S., & Chambers, J. A. (2015). Robust sclera recognition system with novel sclera segmentation and validation techniques. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 47(3), 474–486.
Chaki, J., Dey, N., Shi, F., & Sherratt, R. S. (2019). Pattern mining approaches used in sensor-based biometric recognition: A review. IEEE Sensors Journal, 19(10), 3569–3580.
Chin, Y. H., Wang, J. C., Huang, C. L., Wang, K. Y., & Wu, C. H. (2017). Speaker identification using discriminative features and sparse representation. IEEE Transactions on Information Forensics and Security, 12(8), 1979–1987.
El-Ouahabi, S., Atounti, M., & Bellouki, M. (2019). Toward an automatic speech recognition system for amazigh-tarifit language. International Journal of Speech Technology, 22(2), 421–432. https://doi.org/10.1007/s10772-019-09617-6.
Faragallah, O. S. (2018). Robust noise MKMFCC-SVM automatic speaker identification. International Journal of Speech Technology, 21(2), 185–192.
Hasan, T., & Hansen, J. H. (2011). A study on universal background model training in speaker verification. IEEE Transactions on Audio, Speech, and Language Processing, 19(7), 1890–1899.
Hezil, N., & Boukrouche, A. (2017). Multimodal biometric recognition using human ear and palmprint. IET Biometrics, 6(5), 351–359.
Kim, C., & Stern, R. M. (2016). Power-normalized cepstral coefficients (PNCC) for robust speech recognition. IEEE/ACM Transactions on Audio, Speech and Language Processing (TASLP), 24(7), 1315–1329.
Kumari, R. S. S., Nidhyananthan, S. S., et al. (2012). Fused mel feature sets based text-independent speaker identification using gaussian mixture model. Procedia Engineering, 30, 319–326.
Ma, Z., Yu, H., Tan, Z. H., & Guo, J. (2016). Text-independent speaker identification using the histogram transform model. IEEE Access, 4, 9733–9739.
Ming, J., Hazen, T. J., Glass, J. R., & Reynolds, D. A. (2007). Robust speaker recognition in noisy conditions. IEEE Transactions on Audio, Speech, and Language Processing, 15(5), 1711–1723.
Morales, A., Morocho, D., Fierrez, J., & Vera.Rodriguez, R. (2017). Signature authentication based on human intervention: Performance and complementarity with automatic systems. IET Biometrics, 6(4), 307–315.
Nijhawan, G., & Soni, M. (2013). A new design approach for speaker recognition using MFCC and VAD. International Journal of Image Graphics Signal Process (IJIGSP), 5(9), 43–49.
Rajeswari, P., Raju, S.V., Ashour, A.S., & Dey, N. (2017). Multi-fingerprint unimodel-based biometric authentication supporting cloud computing. In: Intelligent techniques in signal processing for multimedia security (pp. 469–485). New York: Springer.
Sghaier, S., Farhat, W., & Souani, C. (2018). Novel technique for 3d face recognition using anthropometric methodology. International Journal of Ambient Computing and Intelligence (IJACI), 9(1), 60–77.
Sun, L., Gu, T., Xie, K., & Chen, J. (2019). Text-independent speaker identification based on deep gaussian correlation supervector. International Journal of Speech Technology, 22(2), 449–457. https://doi.org/10.1007/10772-019-09618-5.
Tazi, E.B., El-Makhfi, N. (2017). An hybrid front-end for robust speaker identification under noisy conditions. In: IEEE 2017 Intelligent Systems Conference (IntelliSys) (pp. 764–768).
Togneri, R., & Pullella, D. (2011). An overview of speaker identification: Accuracy and robustness issues. IEEE Circuits and Systems Magazine, 11(2), 23–61.
Univaso, P. (2017). Forensic speaker identification: A tutorial. IEEE Latin America Transactions, 15(9), 1754–1770.
Verma, P., & Das, P. K. (2015). i-vectors in speech processing applications: A survey. International Journal of Speech Technology, 18(4), 529–546.
Yadav, I. C., Shahnawazuddin, S., & Pradhan, G. (2019). Addressing noise and pitch sensitivity of speech recognition system through variational mode decomposition based spectral smoothing. Digital Signal Processing, 86, 55–64.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Al-Kaltakchi, M.T.S., Al-Nima, R.R.O., Abdullah, M.A.M. et al. Thorough evaluation of TIMIT database speaker identification performance under noise with and without the G.712 type handset. Int J Speech Technol 22, 851–863 (2019). https://doi.org/10.1007/s10772-019-09630-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10772-019-09630-9